The TimeXtender OneLake Delta Parquet Data Source allows ingestion of delta parquet tables from Microsoft Fabric OneLake. This data source is particularly useful for ingesting data from ERPs offering (Delta) Lake replication.
Note: This data source is only supported with data lake Ingest storage. This data source is not currently supported in OneLake and SQL Ingest storage.
Create an App Registration in the Azure Portal - It is recommended to use a dedicated app registration to ensure this account is the only one with access to the client credentials
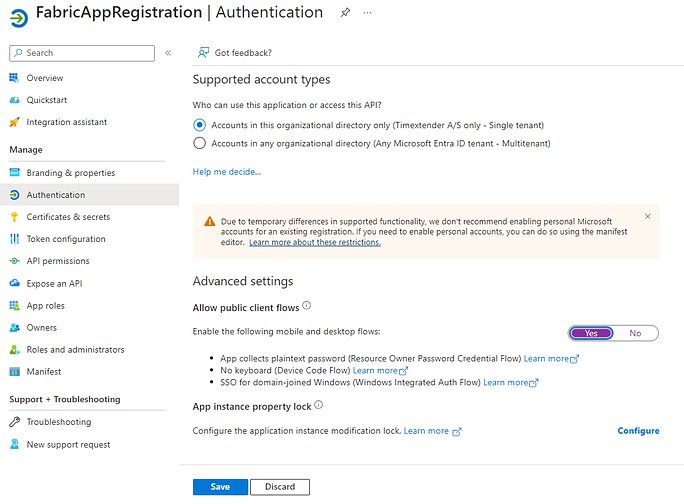
Navigate to Authentication settings for the App Registration. Set Allow public client flows to Yes
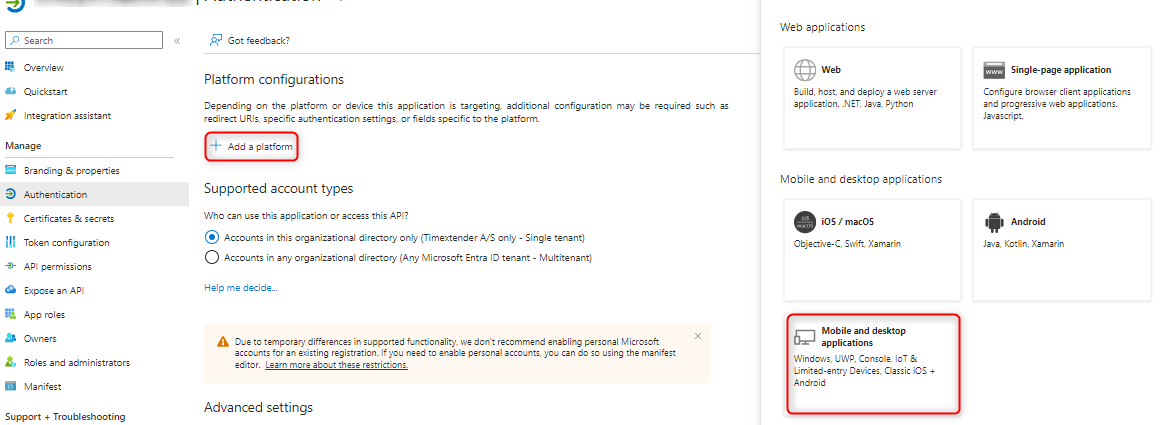
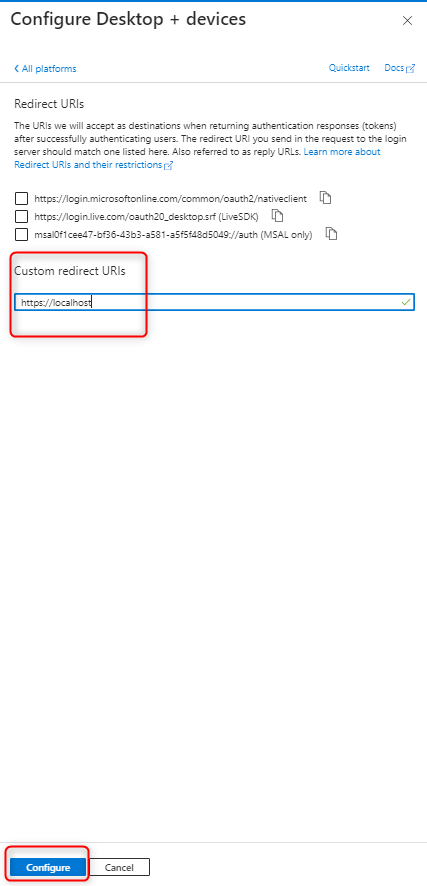
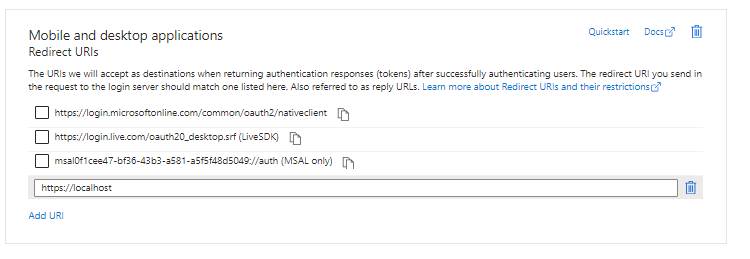
Add a platform and select Mobile and desktop application and enter https://localhost as the custom redirect URI and click Configure and then Save This will result in the following Redirect URIs being added automatically
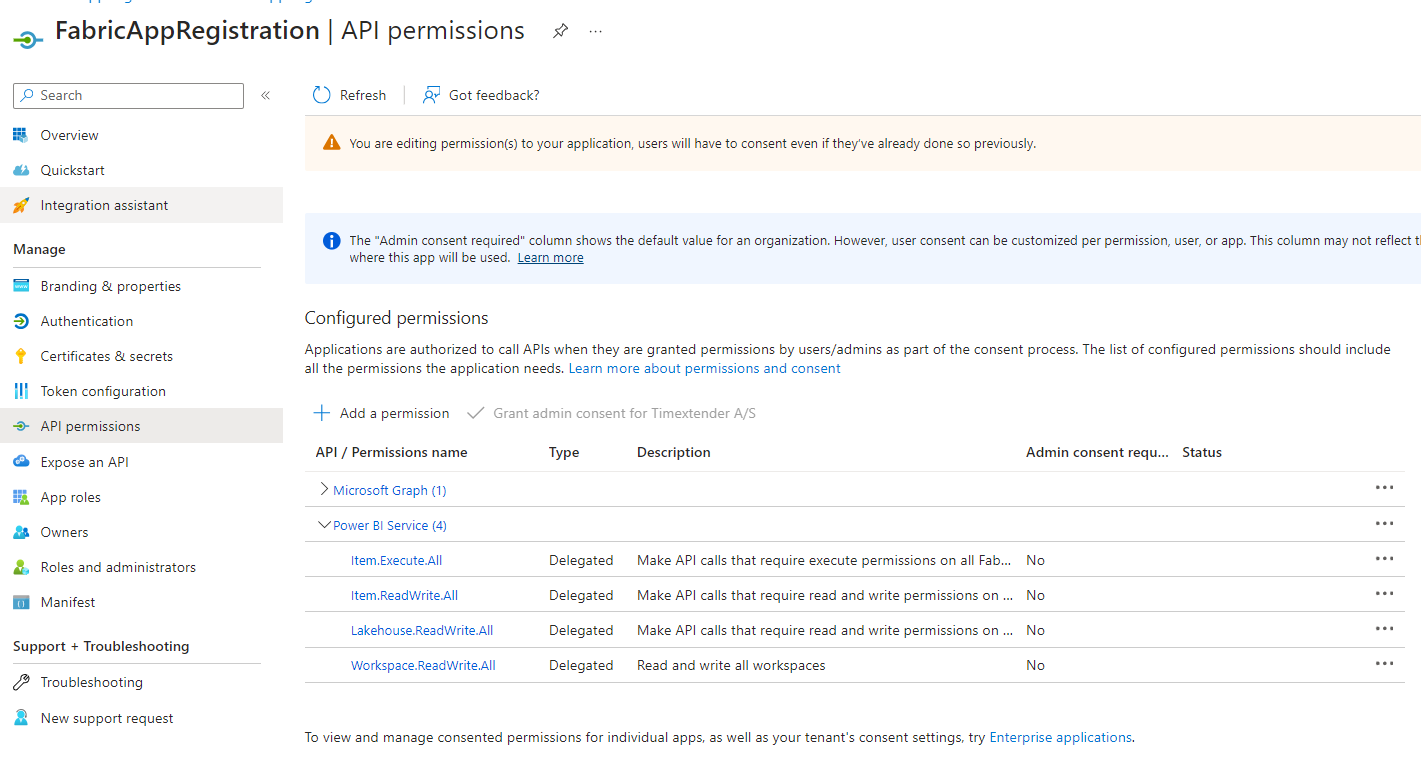
Navigate to API permissions for the App Registration. Add the following Power BI Service delegated permissions
Workspace.ReadWrite.All
Item.ReadWrite.All
Item.Execute.All
Lakehouse.ReadWrite.All
Add a user that does not require multi-factor authentication (i.e. a non-MFA account) as Owner of the App Registration, in order to allow for unattended re-authentication. A login will be required only during data source creation.
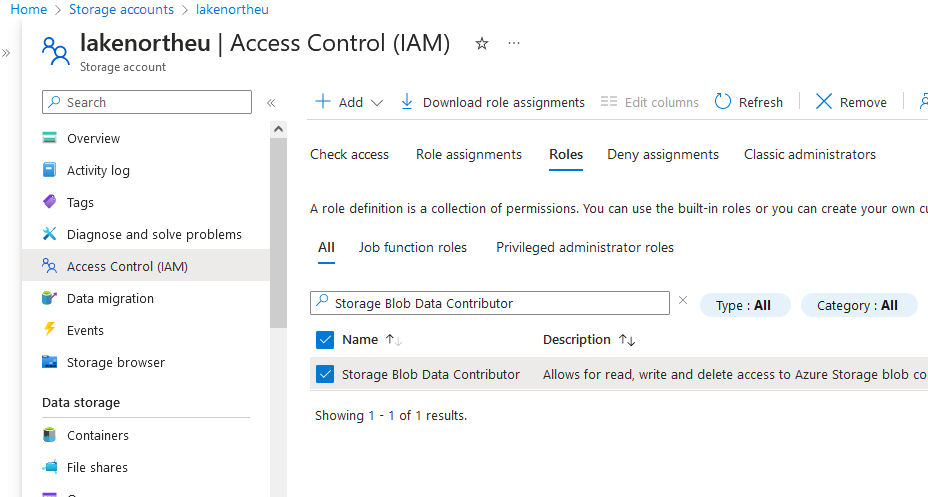
Navigate to the destination Data Lake storage account that you are using for your Ingest instance. Select Access Control. Grant the App Registration access to the storage account by adding the Storage Blob Data Contributor role for the App Registration
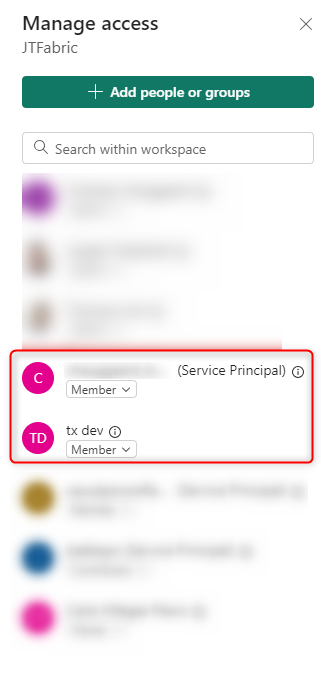
Create a workspace and Lakehouse, or navigate to an existing Lakehouse, in the Fabric portal and select Manage access. Grant the App Registration and the non-MFA account Member access to the Fabric workspace
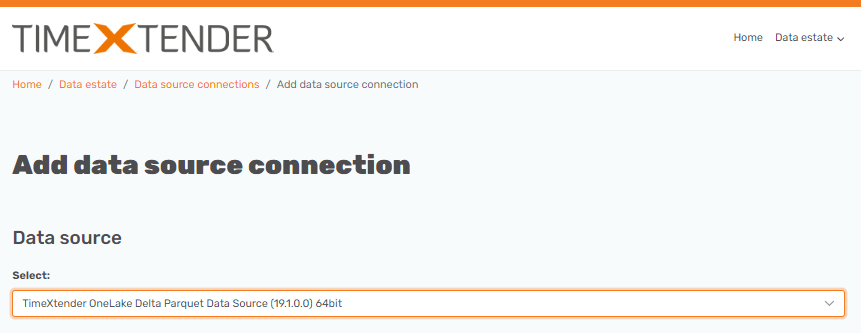
Adding the OneLake data source connection
In the Portal, add the TimeXtender OneLake Delta Parquet Data Source connection
Then configure the below settings.
Connection Settings
Tenant id: Enter the identifier of the tenant associated with Fabric
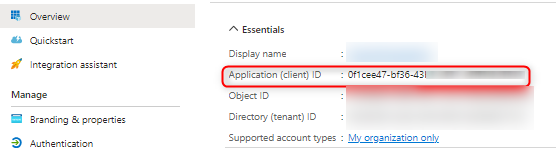
Application id: Enter the App identifier of the App Registration
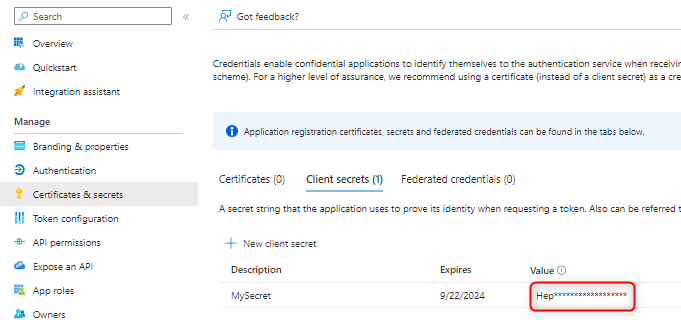
Application Key: Enter the client secret value associated with the App Registration
Workspace: Specify the name of the Fabric workspace where the source will do its work in
Lakehouse: Specify the name of the Lakehouse where the source will do its work in
Username: Specify the username for the non-MFA user used for authentication
Password: Specify the password for the non-MFA user used for authentication
Metadata Settings
Gathering metadata from Fabric involves reading all available delta tables, determined by what's accessible to the user and the application defined in the connection options. This information is extracted through a Notebook and saved in Fabric before being downloaded to the local disk.
Cache meta data: Indicates whether metadata caching is enabled or not. Enabling Cache metadata prevents repeated refreshing of metadata by saving the output from the metadata Notebook result.
Cache tolerance: Specifies the tolerance duration for metadata caching in minutes. Use the Cache tolerance setting to manage the age of the cache by specifying the duration in minutes before a refresh is required.
Meta data cache location: Specifies the location where metadata cache is stored. The cache file will be stored in the path defined in the 'Metadata cache location' setting.
Execution Settings
Local work location: Specifies the default location for local work.
Max. Notebook Parallelism: Indicates the maximum parallelism allowed for notebook execution.
Debugging Settings Category
Enable debugging: Indicates whether debugging is enabled or not. When debugging is enabled on the data source, the generated Notebooks and files in Fabric, as well as files saved on the local disk, will not be deleted.
Authenticate the Data Source in TimeXtender Data Integration
Open TimeXtender Data Integration
Right-click on the newly added data source, and select Authenticate. Use the non-MFA account to login and accept the permissions it wants to add.
Query Tool and Preview Data
When previewing data in the Query Tool, Spark SQL queries are expected. Upon query execution, a Fabric Notebook is generated and executed. The Notebook runs the query, storing the result in a Parquet file within the Fabric working directory. Subsequently, the file is downloaded to the local working directory, from which the data is read and displayed in the Desktop application. Both the Notebook and the Parquet file in the Fabric and local working directories are deleted before displaying the result, unless the Debug connection setting is enabled.
Transfer Tasks
A Fabric Notebook is generated upon task execution. It executes a query for each selected table, incorporating a WHERE clause with column selections and filters. The query results are then saved in a Parquet file within a temporary folder on the Data Lake storage, alongside the _delta_log folder for verification purposes. Finally, the data is committed to the DATA folder, and the generated notebook and temporary files deleted. Transfers with incremental load
Incremental transfer works in a similar way. Incremental rules are added to the WHERE clause and a query is run per table model from a Fabric Notebook. In case of an empty transfer, empty parquet files are generated in order to verify a successful run and check if any metadata should be updated. These empty parquet files are ignored and cleaned up from the temporary folders afterwards. If 'handle deletes' is enabled for incremental transfer, as with a regular transfer, a parquet file is created on the temporary folder, and moved to the PRIMARYKEYS folder during commit.
Storage Credentials
Currently, storage credentials are added to notebooks on clear text. As mentioned in the prerequisites section above, it is recommended that dedicated app registrations own and are the only members with access to the Workspace targeted by the data source. All notebooks are disposed after execution, but there is a risk of exposing credentials to other users, if they are given access to the Lakehouse.
Limitations
This data source does not currently support:
Data Type Overrides - it is possible to add data type overrides however, this will not change the output data types for the delta parquet tables in the Ingest storage. If data type overrides are added it will affect the formatting of values in incremental load and selection rules. Therefore data type overrides are currently not supported.