There is a host of pages under the open data umbrella and one of the providers is called Socrata. This https://soda.demo.socrata.com/ is the main URL for this and in there you have a lot of data based options on specific things such as environment, governance, and health.
This API uses a specific pagination method where you need to state an offset and limit value to get all the data.
Many other APIs do something similar. I have seen some use take and size, some start and size and so forth. They all work the same way and this should work for these as well.
Initial Setup
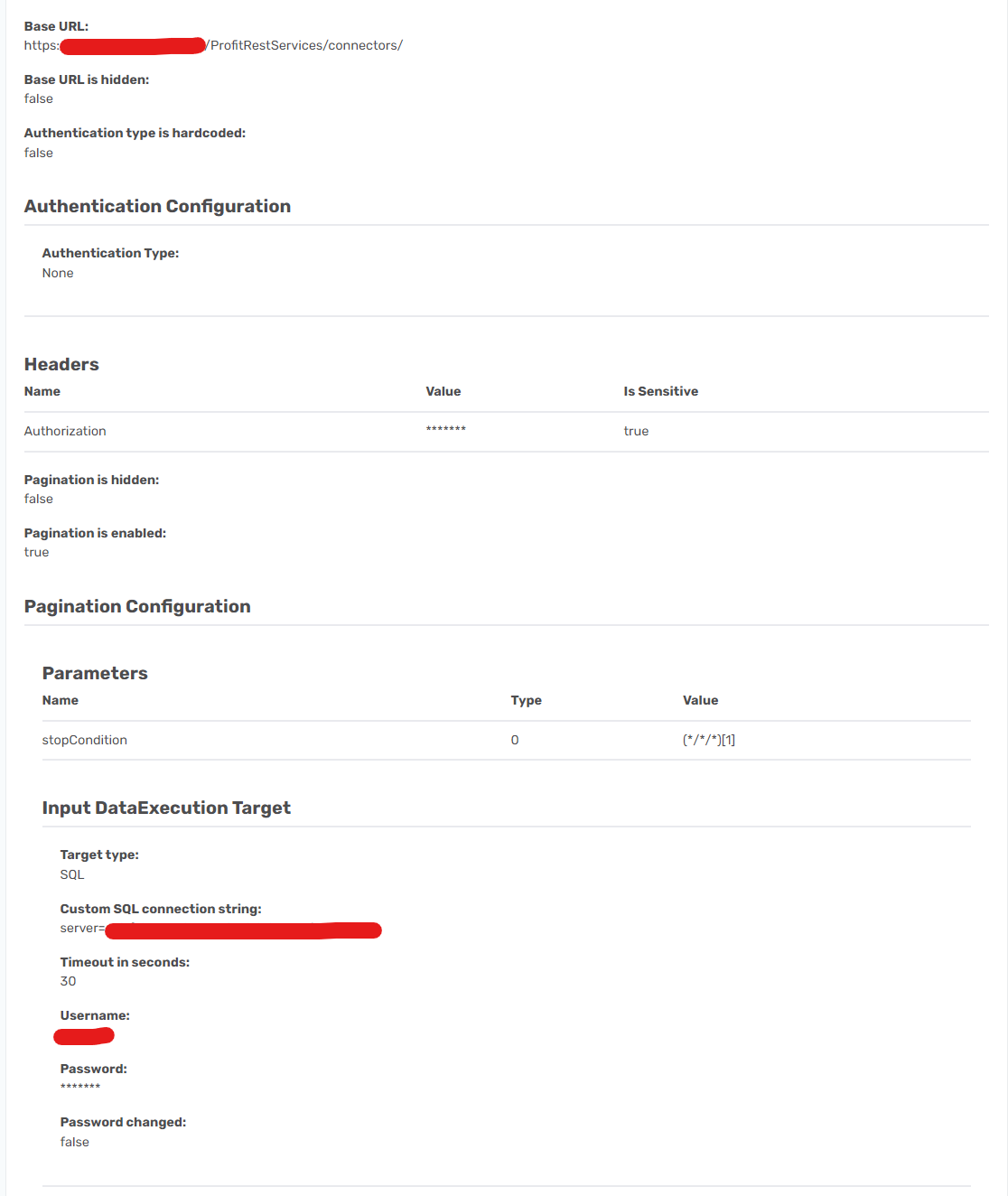
Start by finding the base URL.
First, you find the endpoint you want to use I use the Current Employee Salaries dataset.
Once located you can find the actual endpoint by clicking on Actions and then API.
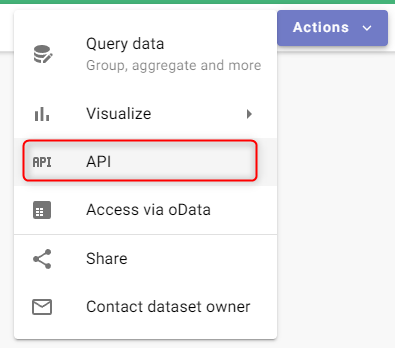
You can copy it from this location.
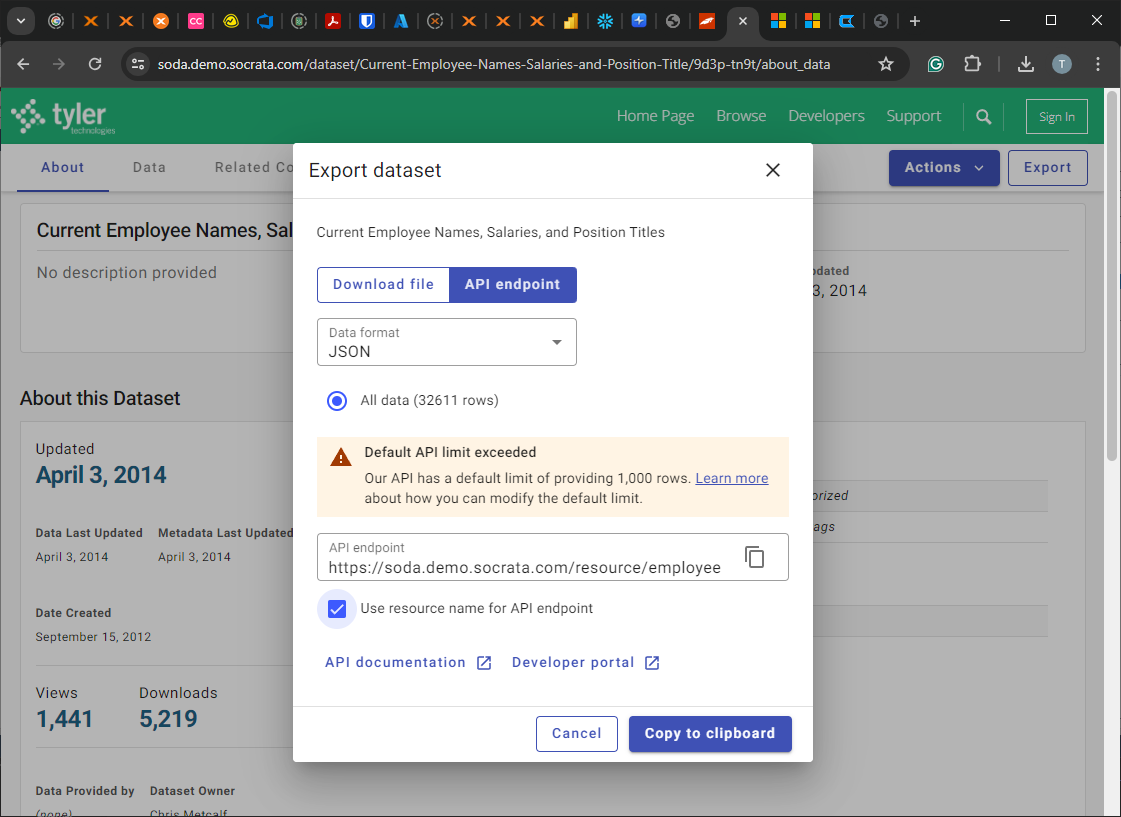
Once copied you can add this part as the Base URL.
https://soda.demo.socrata.com/resource/
It should look like this.
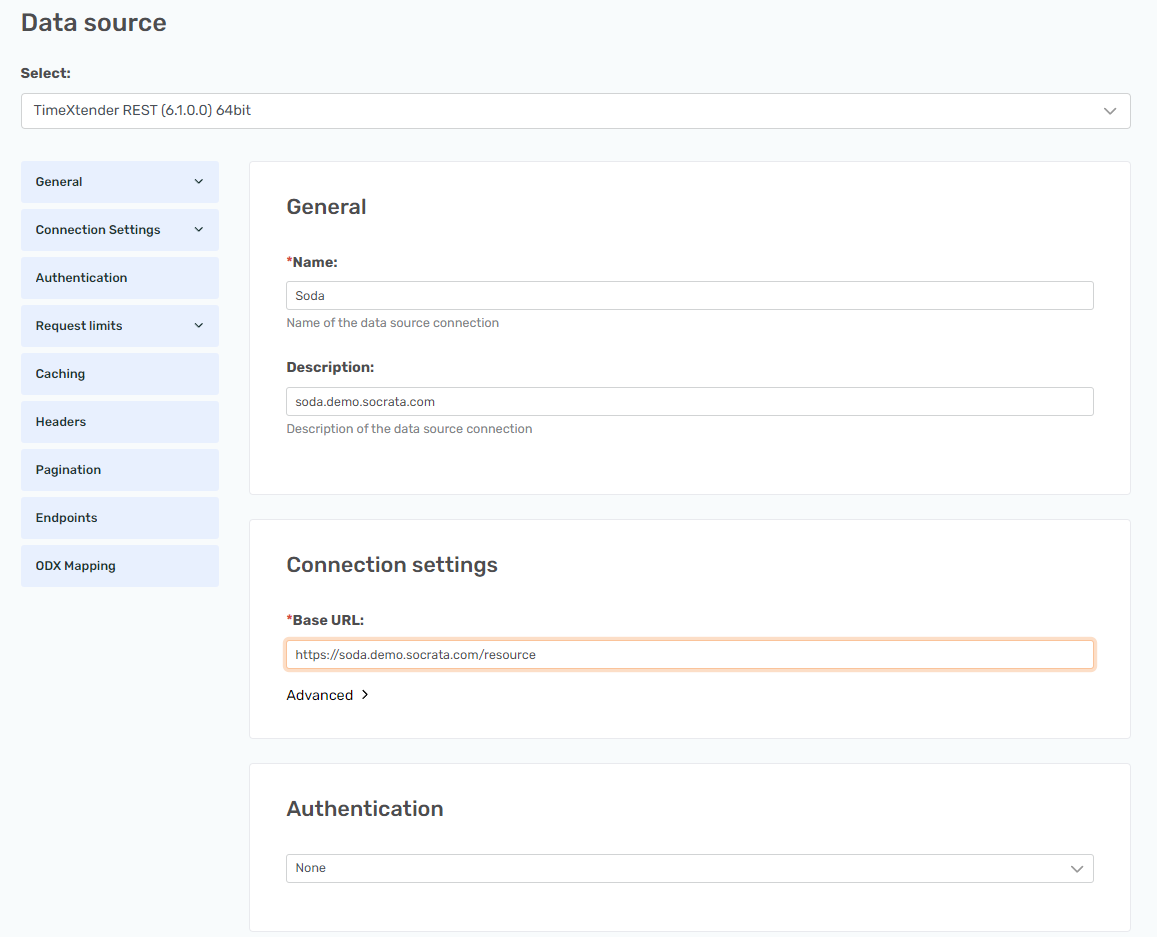
Pagination
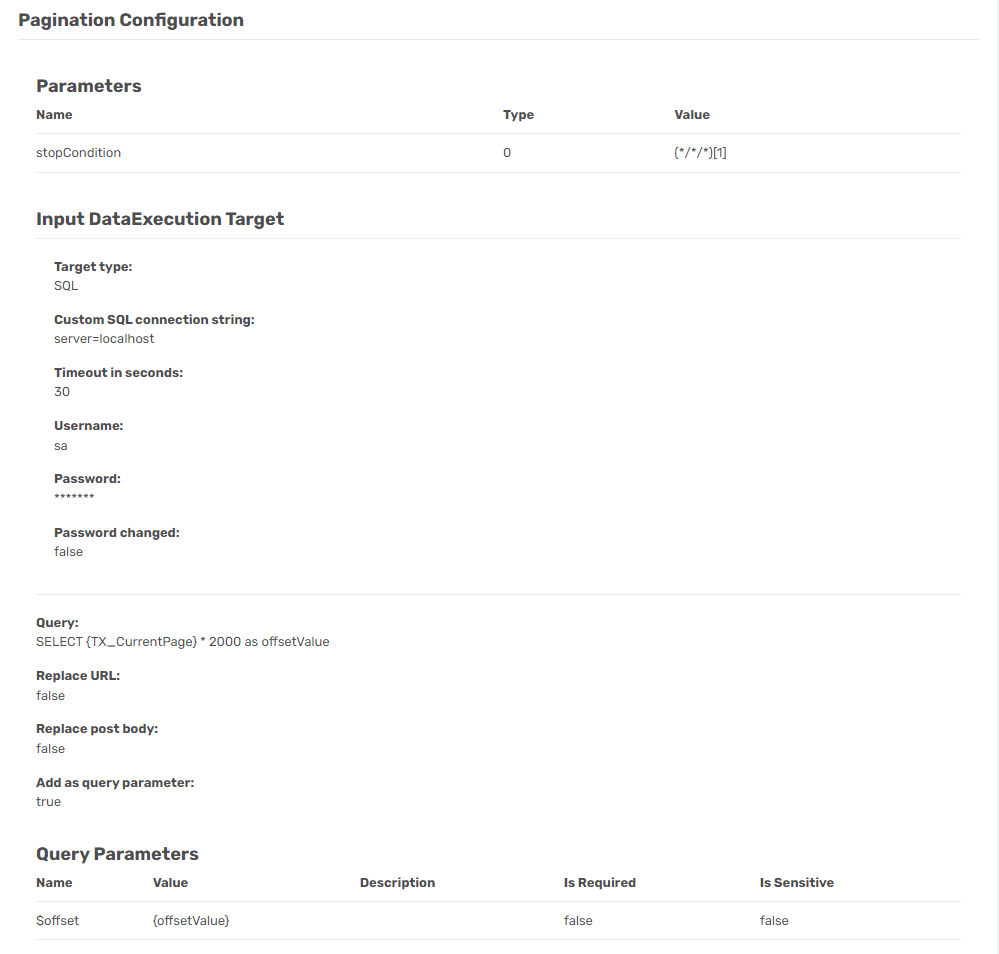
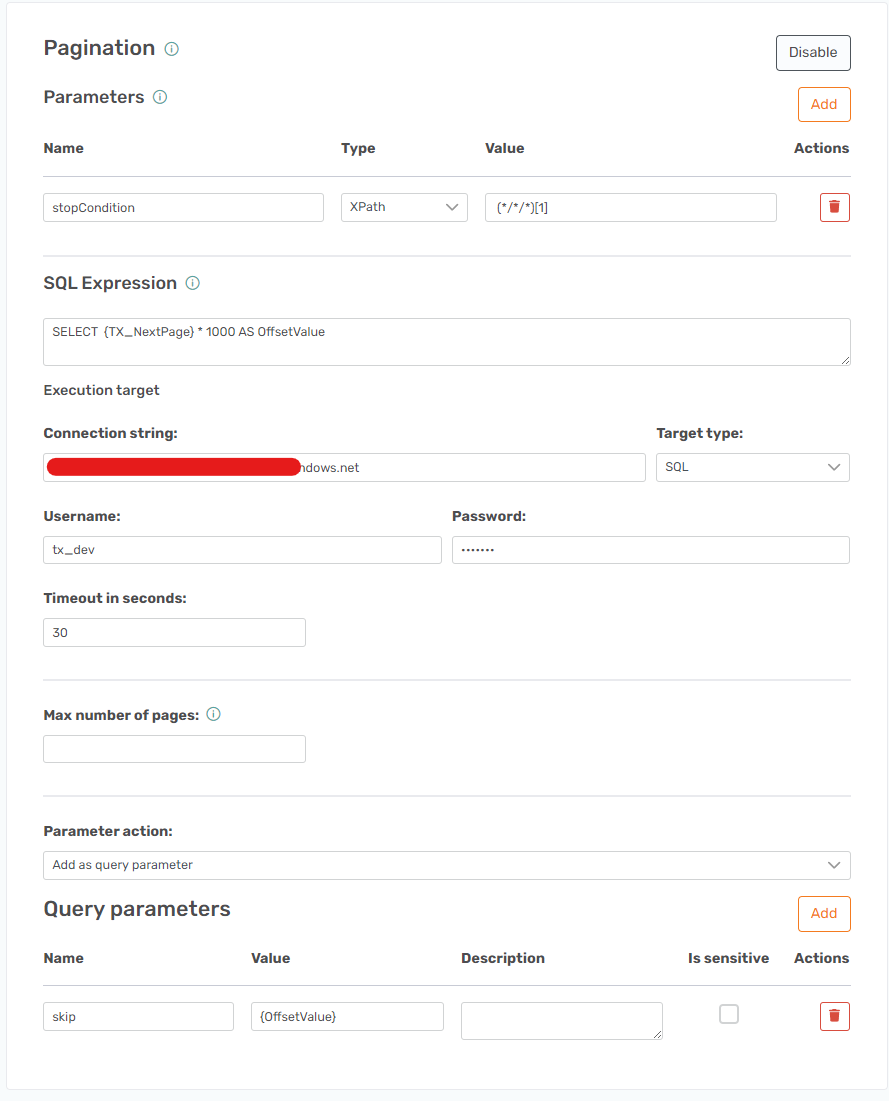
To set up pagination we need to use a dynamic SQL query and the {TX_CurrentPage} number operator option. This option will increase its value by one on each iteration starting with 0.
The two options that are used for pagination on this API are called $offset and $limit. The default limit value is 1000, but you can increase it to 2000 maximum. That is what we want to do to keep the pages as few as possible.
The dynamic SQL query I made looks like this.
SELECT {TX_CurrentPage} * 2000 as offsetValueThis means that it will use the current {TX_CurrentPage} number and increase it with 2000 on each iteration and this value will be saved in the offsetValue name.
You also point to an SQL Server, but you do not need to specify what database it should run on.
server=localhostThe User field is set to an SQL Authorization user and the Password field is this user's password.
Finally, the result of this is used in a parameter where the Name is equal to $offset and the Value is equal to {offsetValue}.
To figure out how to find when it should stop you can add a check on what is returned and then see if the returned contains what you look for. So if you set up that it should increase the page value on each iteration, the first page will look like this.
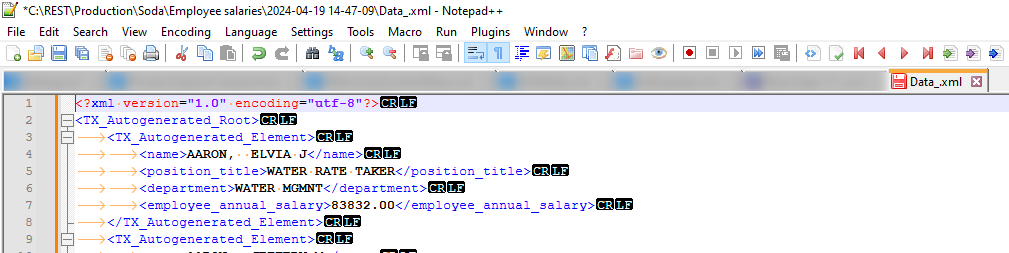
And the last page will look like this.
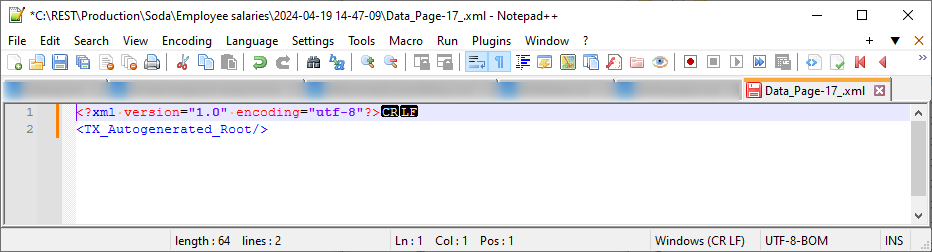
This means that the rule should check whether the file is empty and if so stop. The XPath rule that can do that is the following (*/*/*)[1]. That setup means that it will run if there is any content after the third level and if there isn’t it will stop. A different wording of the XPath could be (TX_Autogenerated_Root/TX_Autogenerated_Element)[1]/*[1]. The reason it checks for three levels is that there could be another level TX_Autogenerated_Element that could be received without having any real data.
You need a Parameter with the Name field equal to stopCondition, the Type field equal to XPath, and the Value field equal to (*/*/*)[1].
It should all look like this.
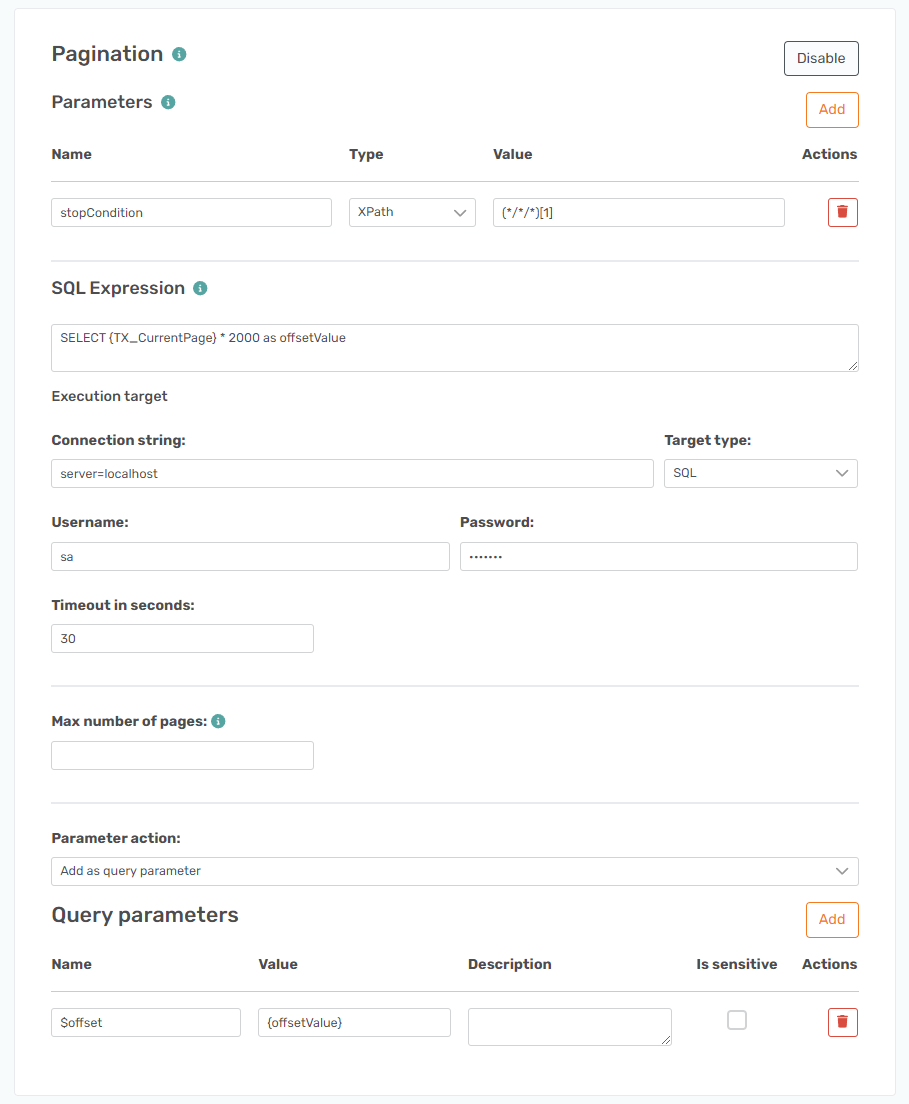
There is no $limit query parameter set up on this as it will run the first iteration without this setup and therefore only return 1000 on the first page.
Endpoint
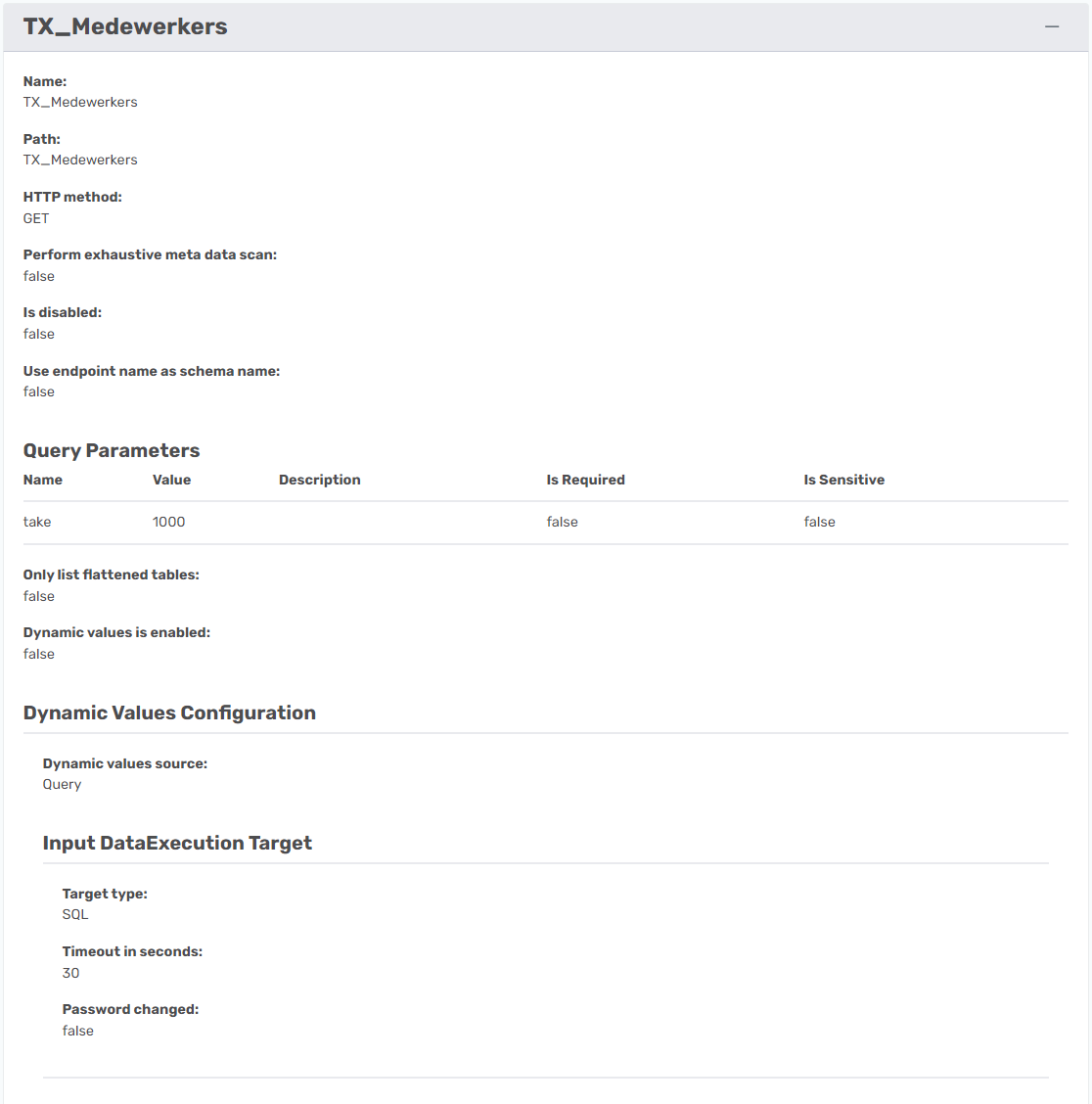
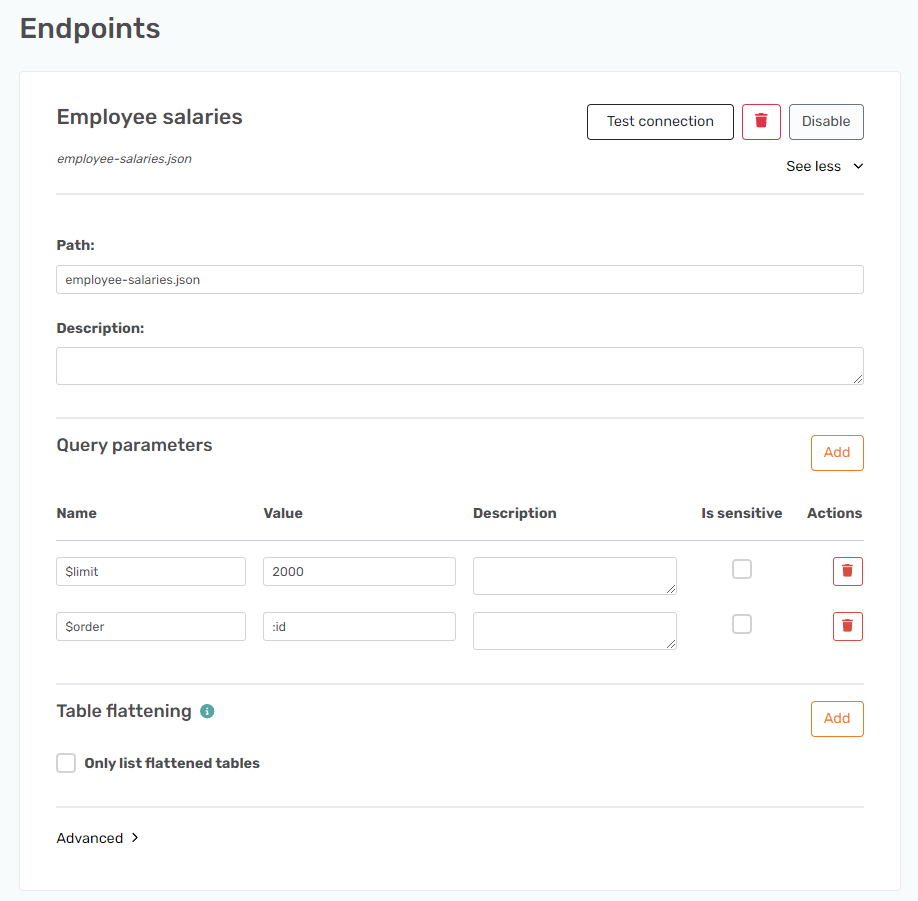
The endpoint for this dataset is Employees, so the endpoint path is Name equal to Employee salaries and Path equal to employee-salaries.json.
Besides this, you need to add the @limit query parameter as Name equal to @limit and Value equal to 2000.
As an option, you can also add an $order parameter to order the data based on one of the fields. I made the result be ordered by the ID field. To name a field add a : in front of it.
I set the Name field to be equal to $order and the Value field to be equal to :id.
It should look like this.
That is it. It should iterate over the 32.6k rows and show this info.