Hello,
we're using Timextender with ADF for the data movement between our Data Lake storage and SQL Database. Running the execute from TimeXtender of rerun it within ADF the performance is poor (slow!).
Our setup at the moment, regarding to the specs within the topic "Create a Demo Template Project TX SaaS”. We wanted to start basic and then tweak the settings for better performance. Executing the first
SQL Database
- Service tier: General Purpose
- Compute tier: Serverless
- Hardware: Standard (Gen5), Min/Max vCores 10 and 30GB Min/Max Memory
- Auto-pause delay: 1 hour
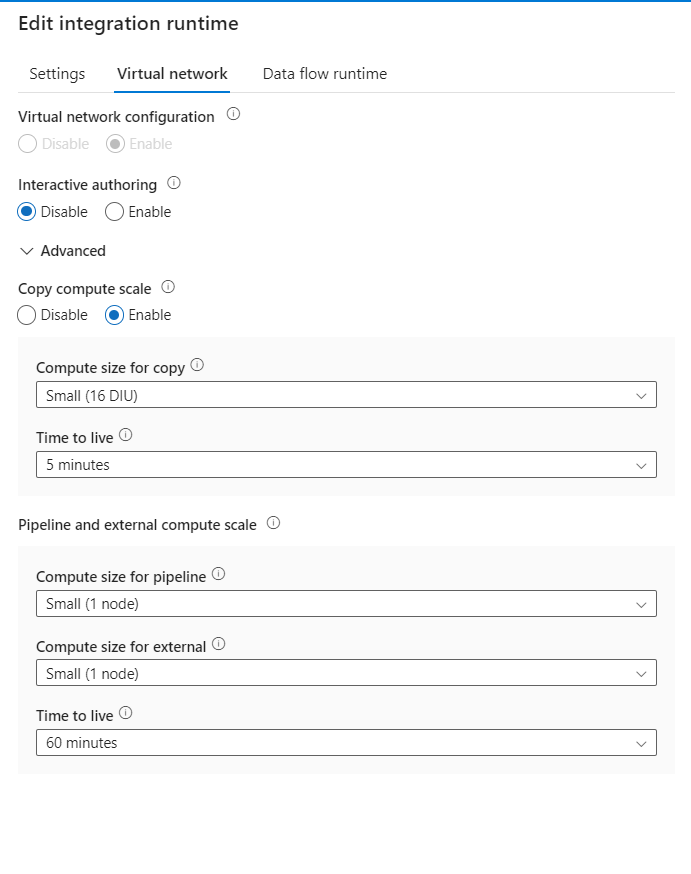
Integration Runtime - type Azure
- Computer Size: small
We tried using a different Computer Size on the IR and also changed the SQL DB Tier for more DTU. No performance improvement after changing.
Looking at one of the jobs we are transferring 2048 rows from our Data Lake to our Azure SQL.
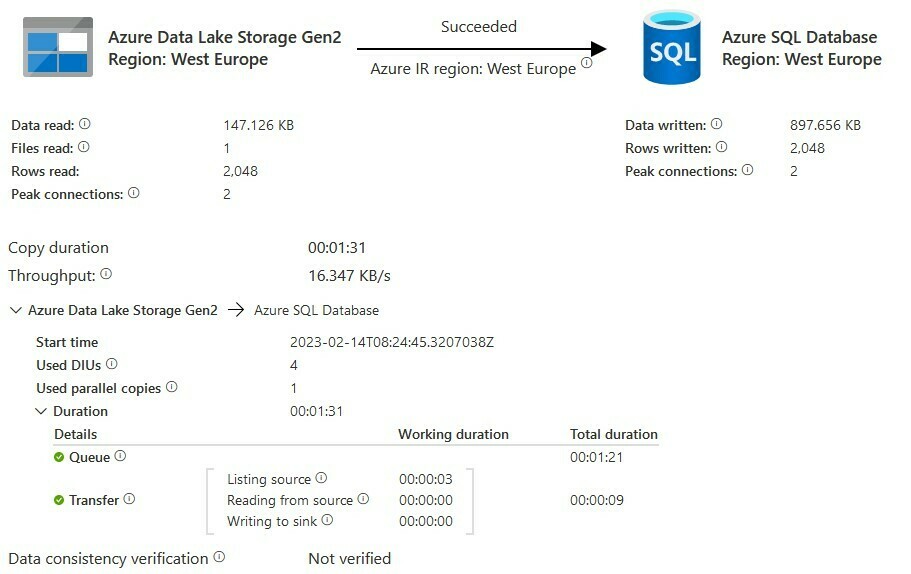
The Queue is taking most of the time. We did some research on the support page of TimeXtender (No topics) and also at the Microsoft community. There are several topics about Slow Performance when using the function “ForEach”:
" Update queries at the same time as the lookup which is trying to update the table is within foreach. With the increase in the number of concurrent queries running in the database , it might have blocked the resource class and in turn one query is blocking other queries. (link to source)”.
Wondering if this is a familiar problem and can we fix it using TimeXtender or do we need to tweak more settings within ADF? If so, this will require also (more) knowledge of ADF. As TimeXtender is building up the Pipelines and Linked Services I'm wondering if it is wise to change settings on the ADF side.
Tahnk you and hopefully somebody can help us.