
Hi team,
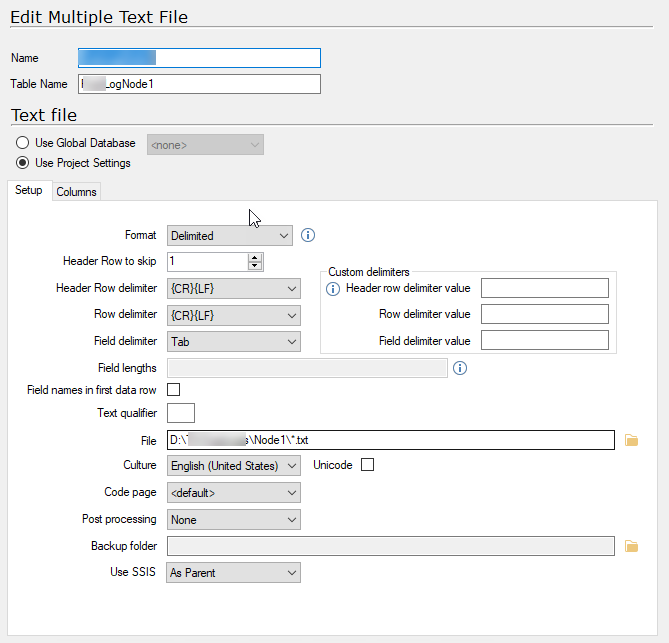
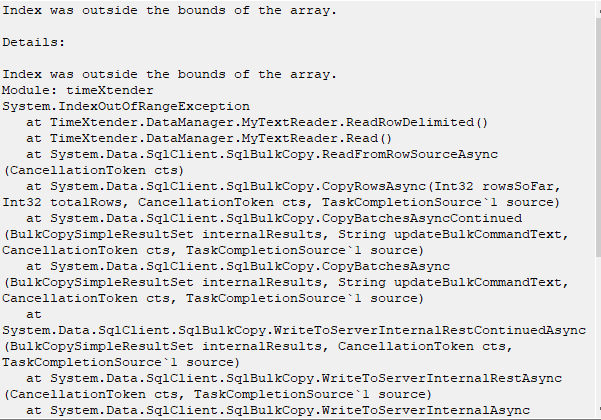
I’m facing the following issue when Multiple Text File connector to pull in *.TXT files. I’m getting the following error “Index was outside the bounds of the array” when i execute table in the ODX.
Hi team,
I’m facing the following issue when Multiple Text File connector to pull in *.TXT files. I’m getting the following error “Index was outside the bounds of the array” when i execute table in the ODX.
Best answer by Thomas Lind
Hi
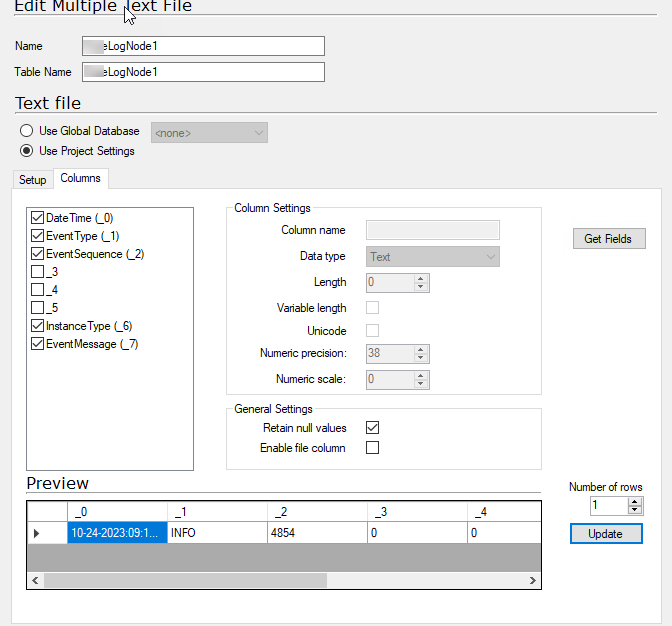
You will get this for any field that is longer than what you set as the data type, it will not tell you what field this is, so there are a few ways to figure out what to do.
You set all fields to nvarchar(4000) and synchronize and see if it goes through.
If it is a delimiter issue as suggested by Rory, it may not be enough as it has a max character limit of 4000 in one field, so then your only option is to manually look at the file to see if you can locate the issue or create a CData CSV data source and point to the same file with that. If you have set the row scan depth to 0 it will read the whole file before determining the data types and it should be easier to see what fields gives issues.
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.


