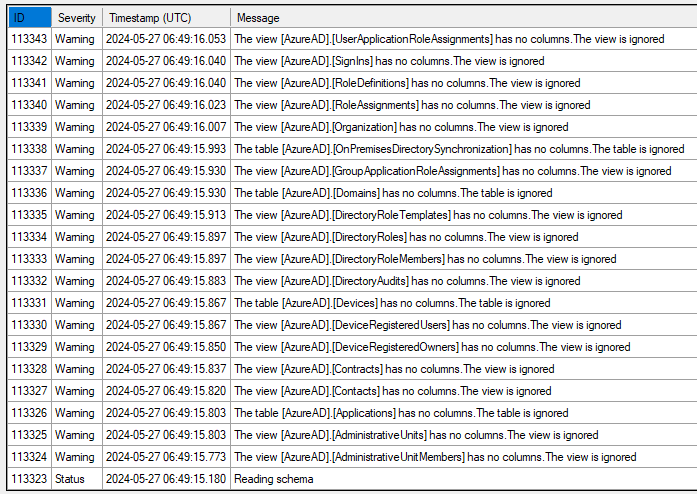
Hi Folks,
I'm trying to use the Azure AD data source to get information from our Azure AD into TimeXtender. I'm extracting User, Group and GroupMembership information using this data source. So far it's working but i notice that a lot of columns that were found are not filled (NULL). If i do a test with PostMan to the Graph API, i see that the fields are filled in (Department and CompanyName).
I’ve also enabled logging, i see the Graph API request being made:
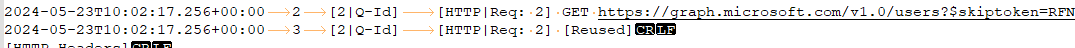
I don't see the fields that i want come back in the results:

I'm guessing that the schema used to get the data from the API does not contain my field so i want to add them. Normally i would generate the schema files using the ‘Generate Schema Files’ option on the portal and edit those to expand the call to the API. There is an option to specify the location of the schema files, but i'm lacking the ‘Generate Schema Files’ option like we have on other similar data sources:
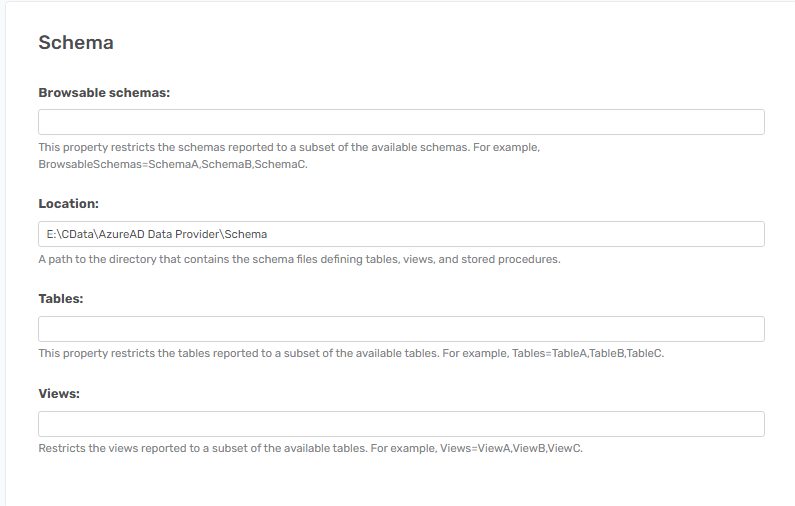
Is there maybe an option to enable this outside the portal? Or is the option simply missing from the portal?
We are on TimeXtender version 6536.1 and i'm using data source type Azure Active Directory version 23.0.8770.0.