Hi @aftabp ,
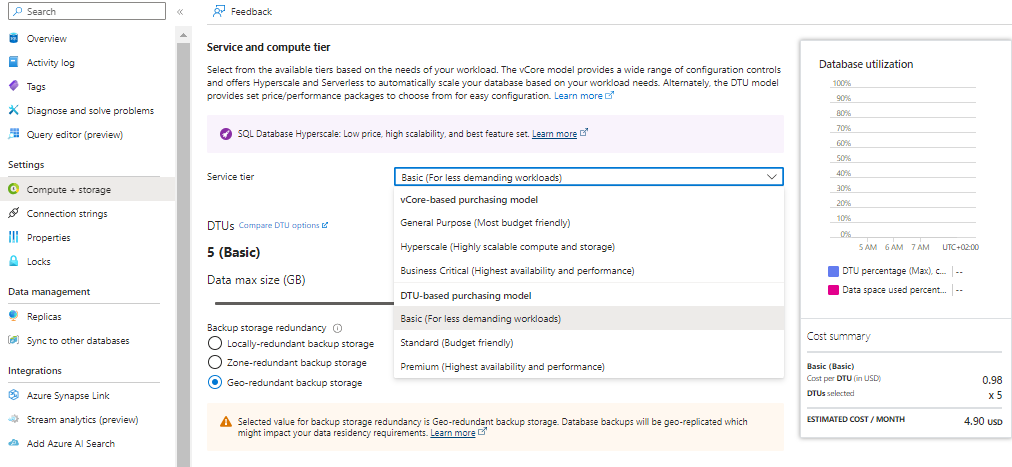
2 vCore for the repository should be more than enough if you clean execution logs regularly. It will only start slowing down on very large projects or with many versions stored. For smaller implementations 50 DTU could also be enough for the starting / initial implementation period.
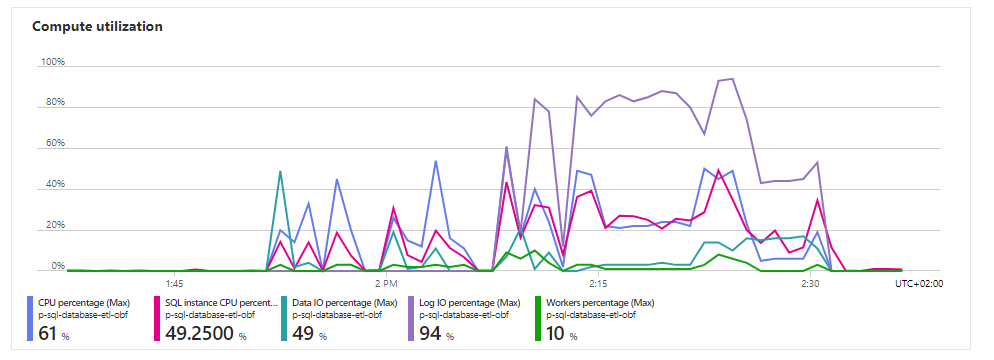
The main benefit from Hyperscale is the Log I/O being higher - in your metrics chart you can see a short period where it reaches above 90%. I wouldn't worry about small spikes of Log I/O reaching 100%, as long as it is not pegged at that level or your waits start indicating I/O Governor as a major contributor.
There is (in preview) now also Premium Managed Instance which can have (at higher scalings) more Log I/O at 192 mb/s. This is more costly than Hyperscale which always has 100 mb/s.
Depending on the transformations you are doing you may need to add indexes to speed things up, checking Custom Views and Aggregate tables is a good start. As your CPU seems the most consumed item I would stay away from table compression for now, you may want to experiment with lowering threading though.