Hi Everyone,
---------Background
My organization is trying to build a Supervisory Org tracking database. Our previous HRM system did this natively, and enough departments are tired of waiting for the new system quirks to be ironed out so I’m tasked with a work around. I can’t connect TX directly to the new system, but HR can download a csv that includes employee ID, Employee Name, Supervisor ID, Supervisor Name, Job Title, Work Location and various less critical fields.
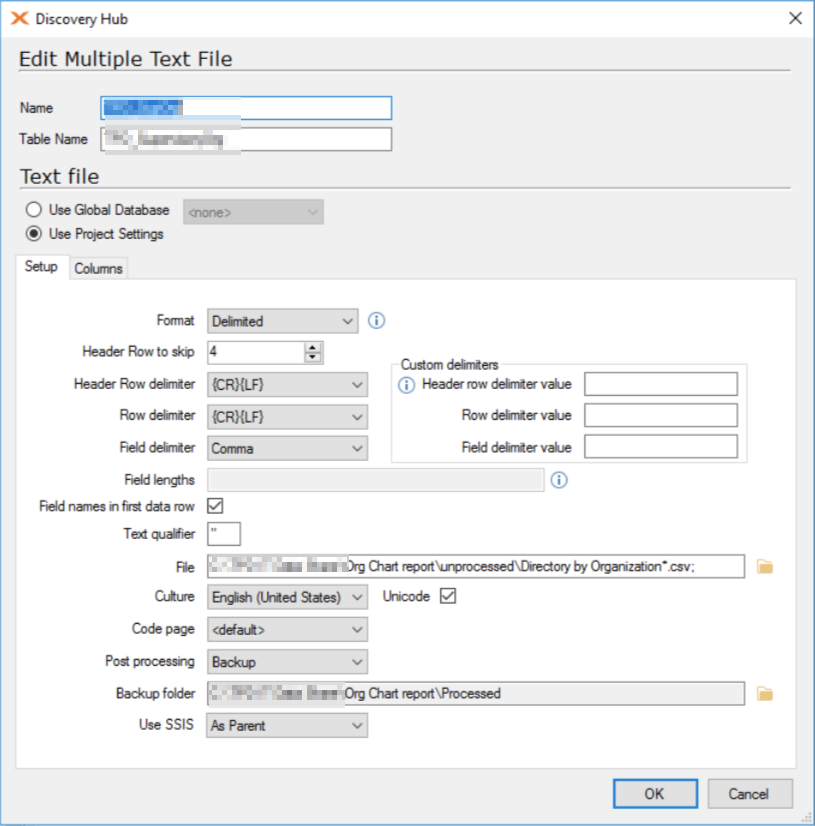
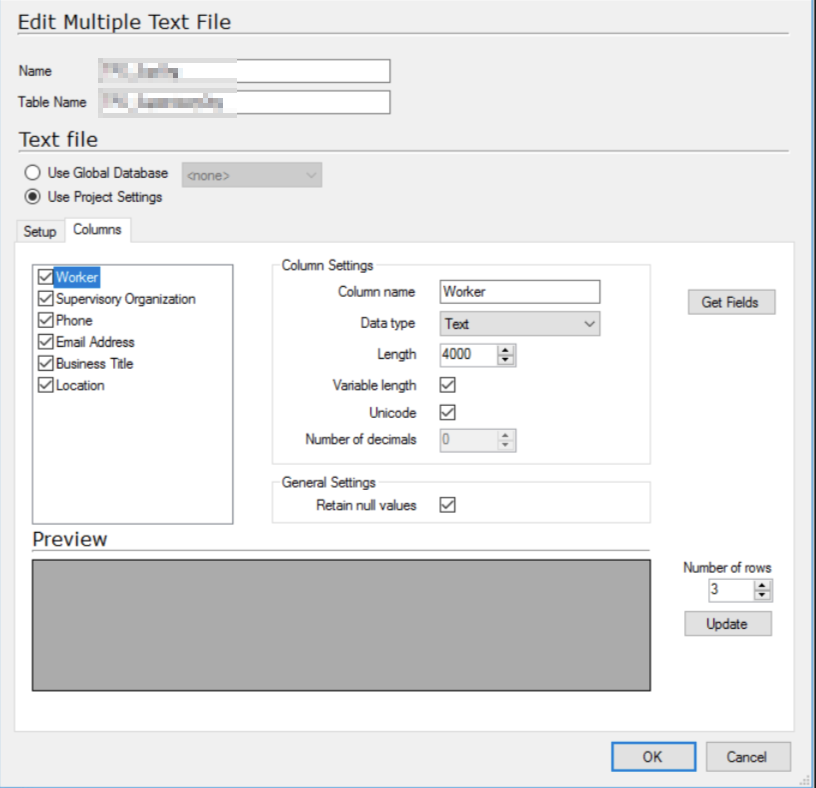
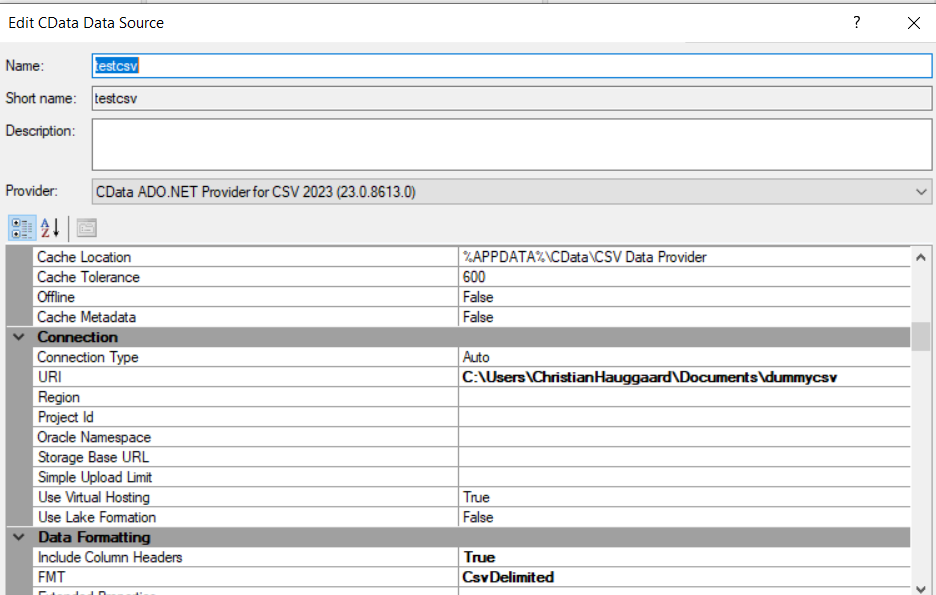
My plan then was to have an HR rep download the csv file once a week to a specific network folder, point TX at it with the Multiple Text File data source. I’d then use the DSA to perform some basic transformations and enable history on the DSA table. In theory this gives me a weekly update to an employee, tracking changes to key things like job title, supervisor, etc. We have a little over 1200 employees in the report, and 60-70k records a year shouldn’t be a problem.
The initial ingest works well. TX reads the file, moves it to a back up location. The transformations and history in the DSA work, and the MDW gets a copy of the IsCurrent and IsTombstone fields and a new record every week.
--------The Problem
I want to schedule this execution package to run at least once a day, because we have the human point of failure and regardless of what time we decided the report will be updated, there will be delays/mistakes/vacations to deal with.
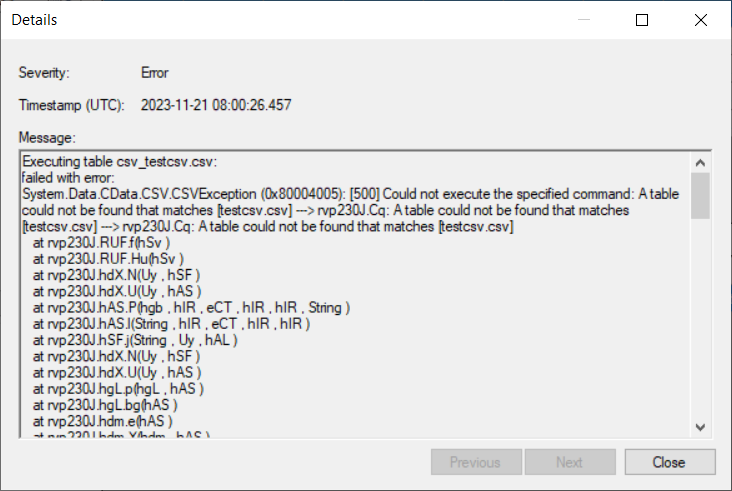
If the job runs and there is no file, the ODX clears the table. The DSA then marks everything as deleted and current, and every employee in the MDW gets a line of nulls marked as current. I haven’t found a way to prevent the execution from happening if a new file is not present.
If I instead keep the historical files in the same folder, the ODX table grows by 1200 duplicates each week and the history functions are lost.
I’m open to any suggestions that would meet my goal, though I’d like to keep them inside TimeXtender.