Hi!
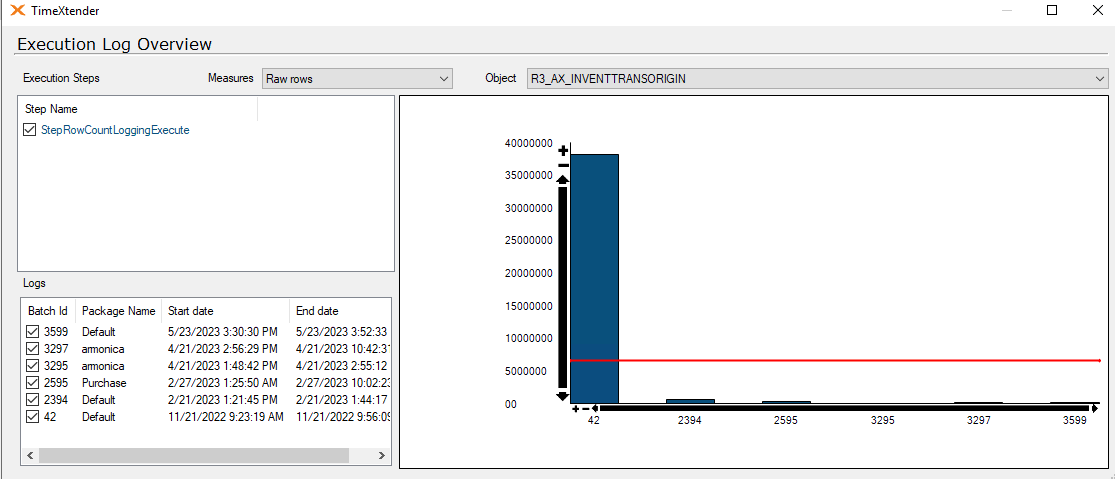
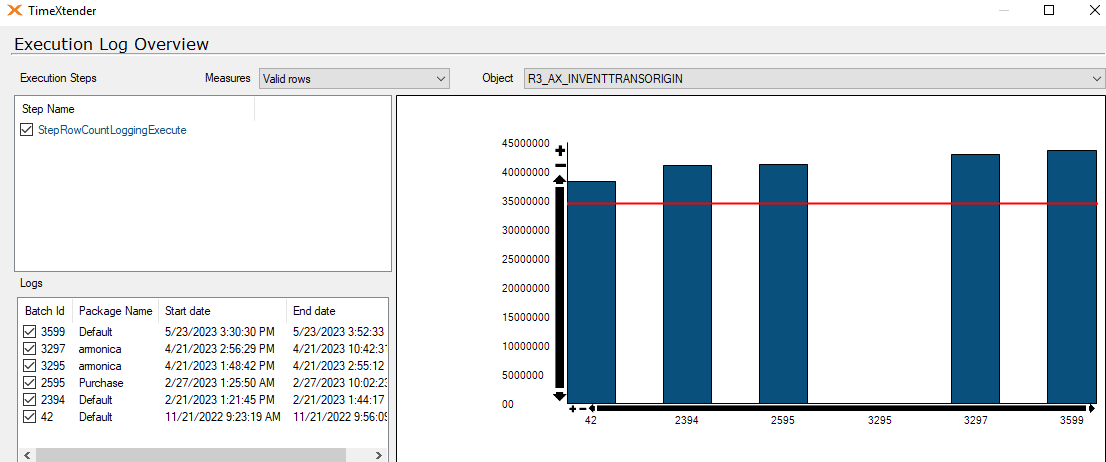
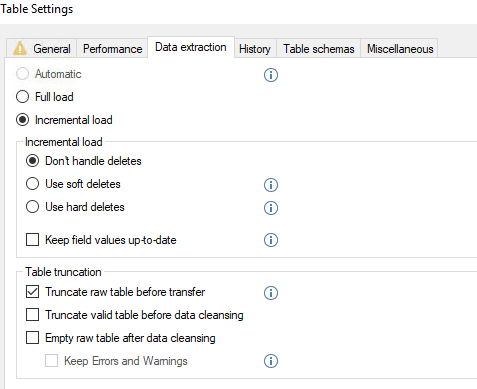
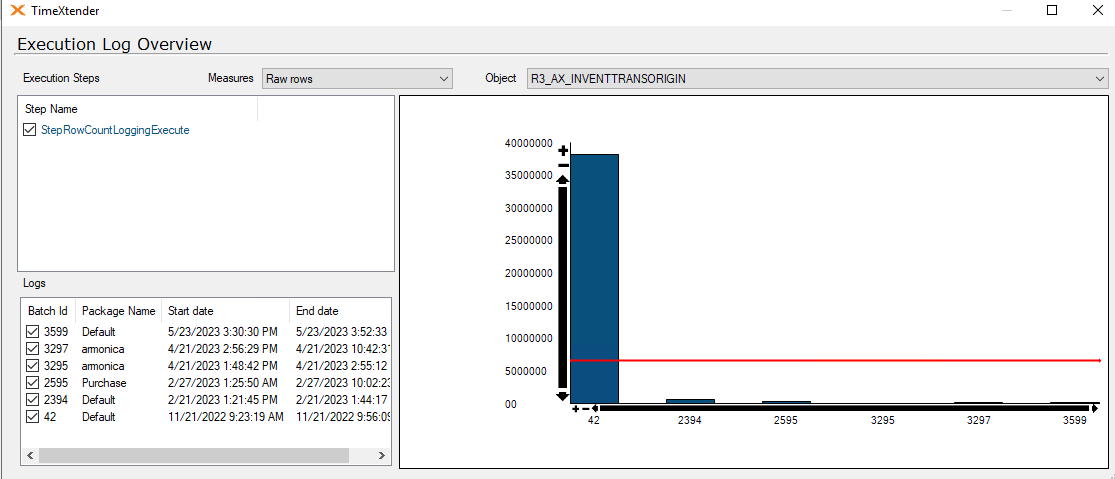
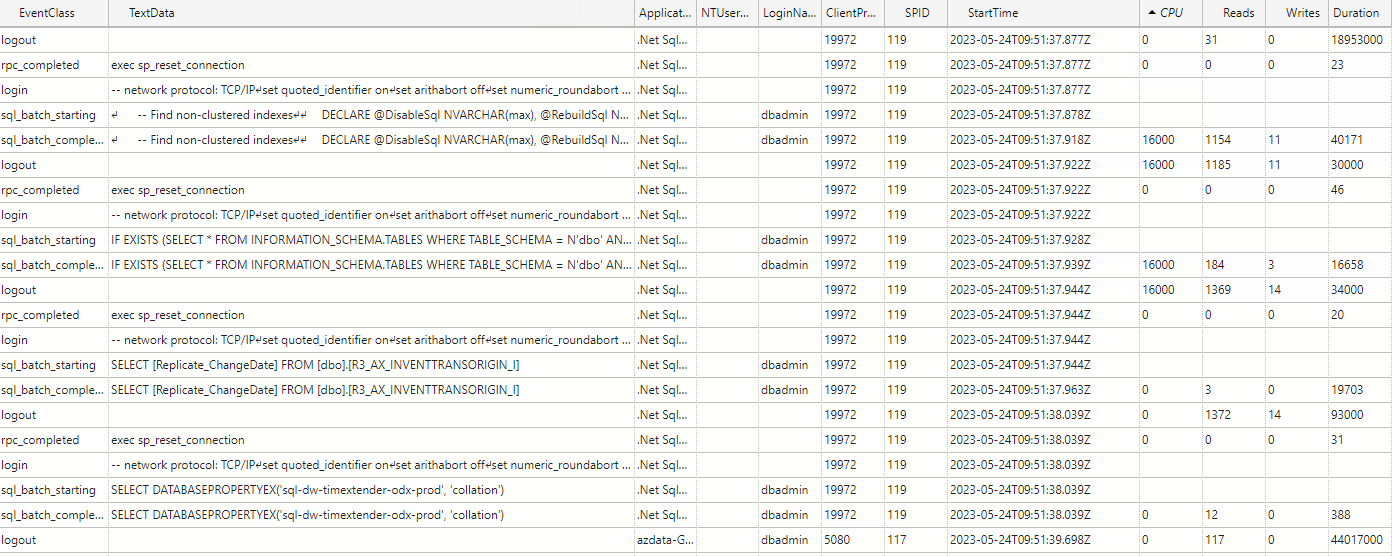
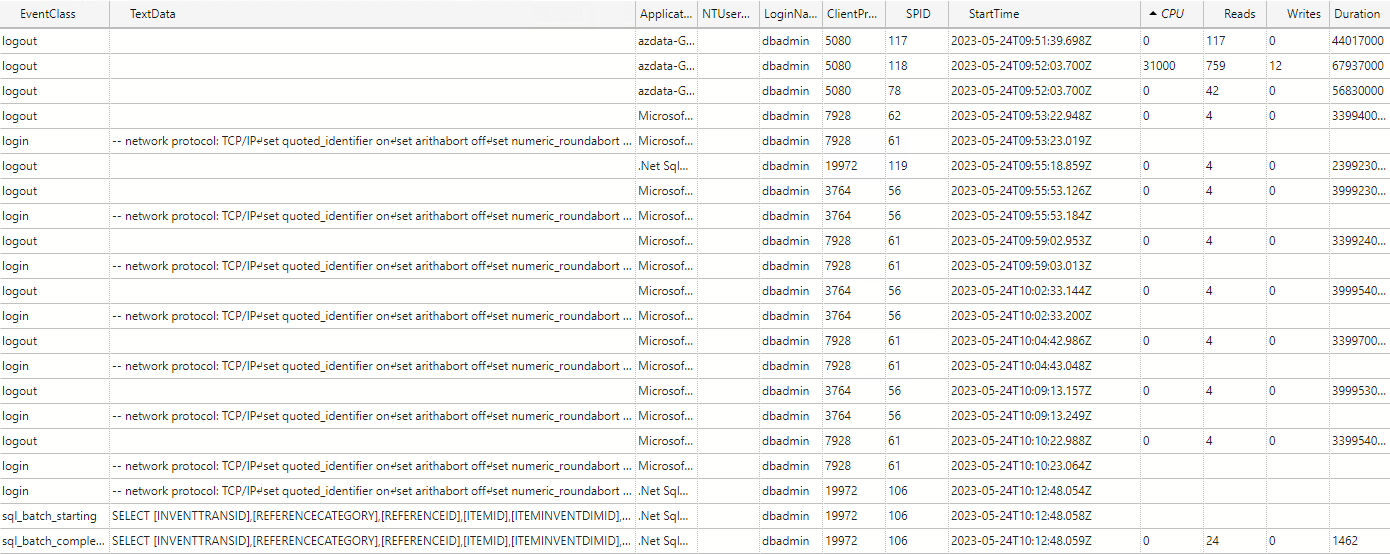
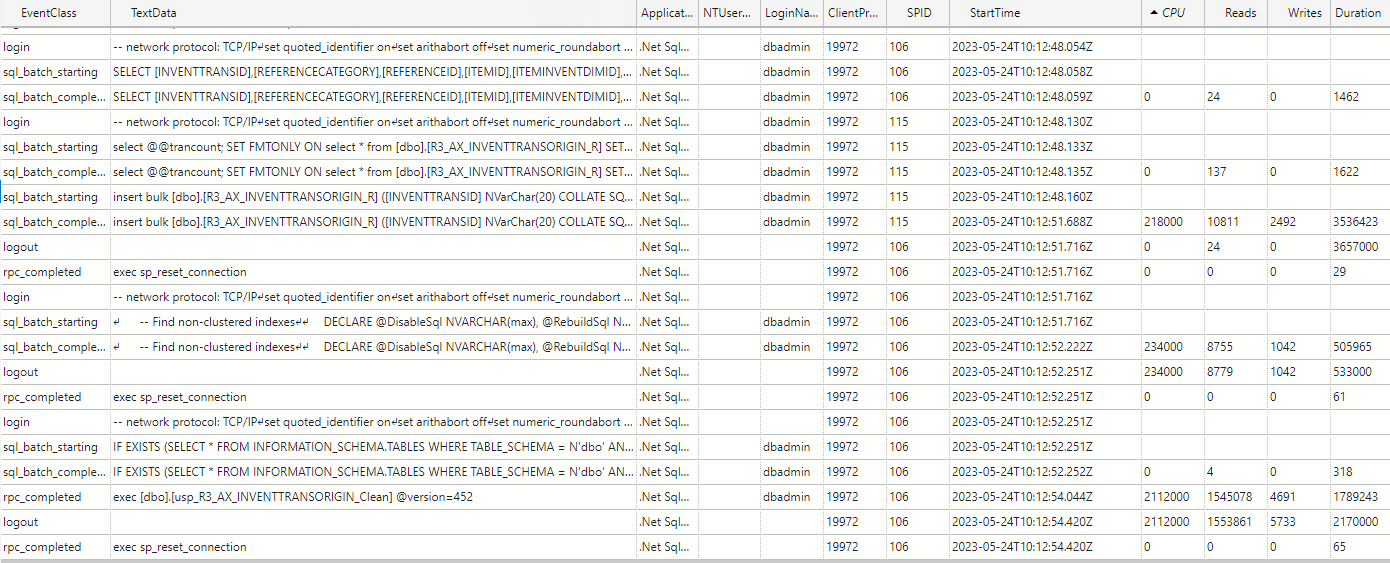
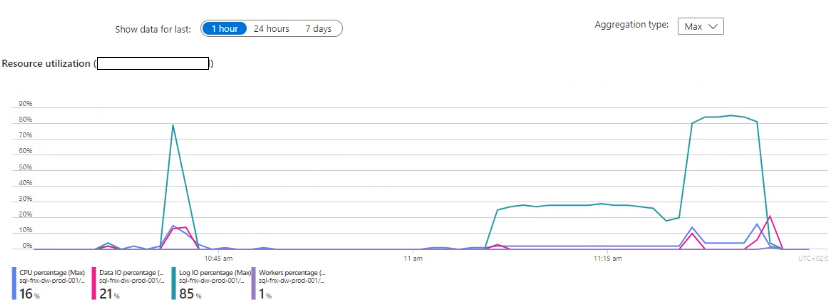
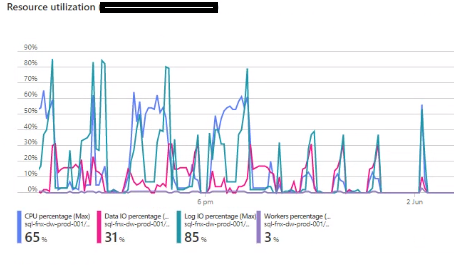
I am experiencing an issue with ADO.NET transfer times on incrementally loaded tables where the ADO.NET transfer takes the same amount of time regardless of the amount of new rows coming into the table. A full load of the table containing about 45 million rows takes about 25 minutes, on the next incremental load the load time is still the same with ADO.NET taking up around 24 of these minutes.
Our current data flow is as follows:
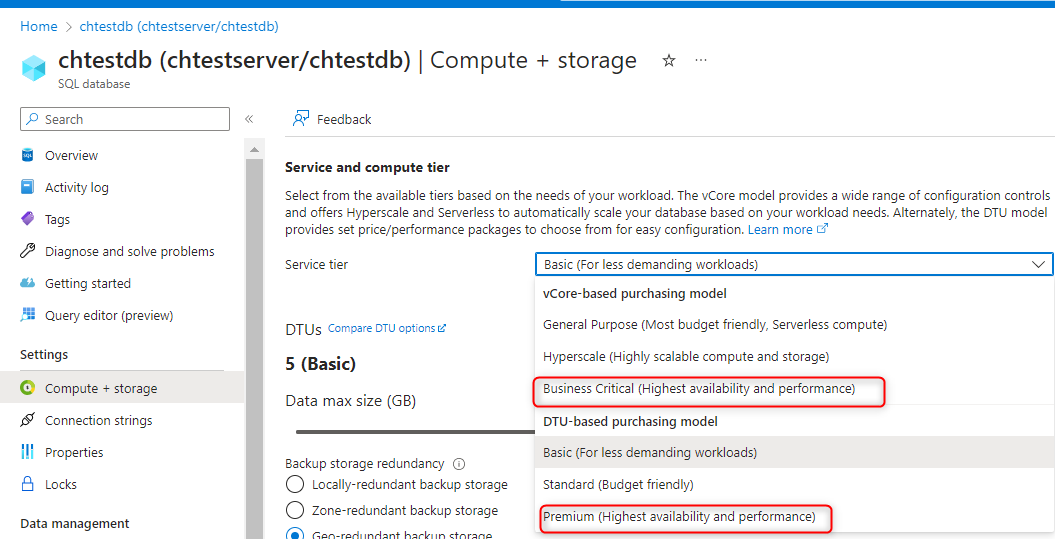
SQL server → TimeXtender → Azure elastic pool (this is where all of our TimeXtender databases resides)
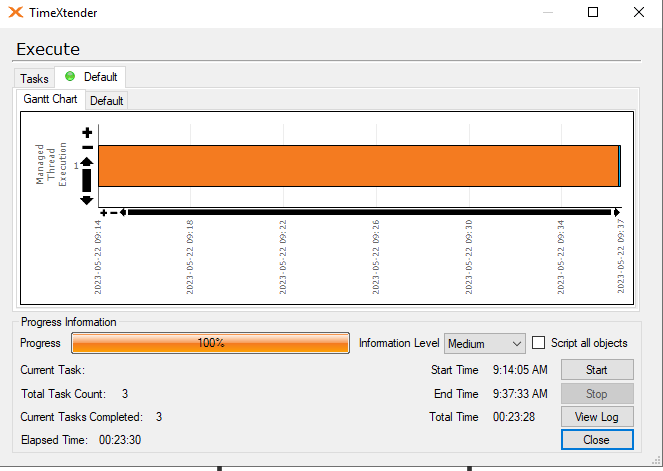
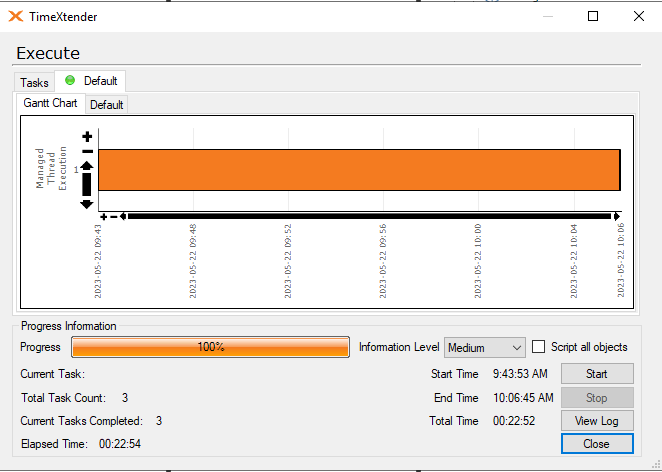

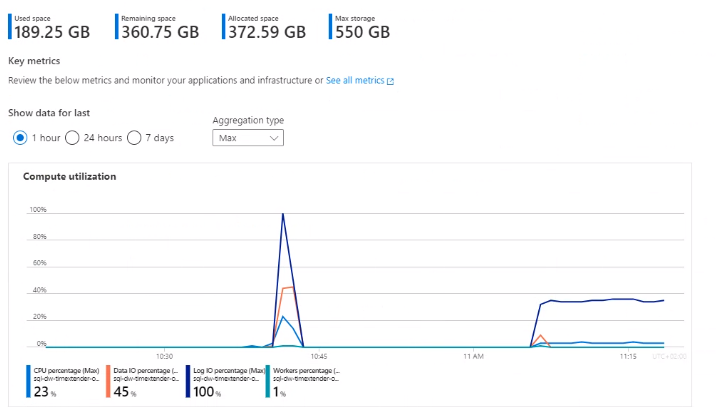
Has anyone experienced a similar issue? My best guess is that the problem resides in the azure elastic pool where the ado.net transfer is being throttled. Even if I have 0 rows in the _R table the ADO.NET transfer time is the same.
Thank you!