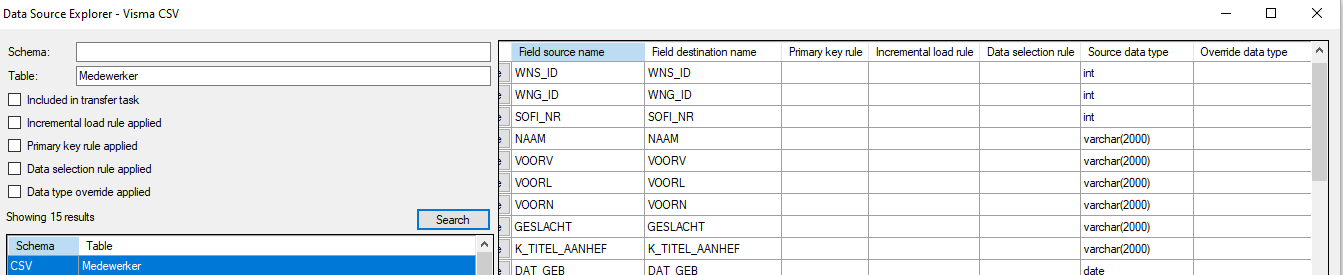
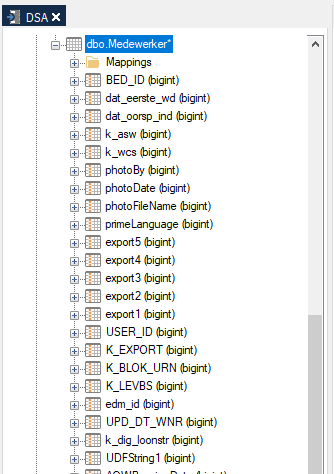
I have created a CSV source in Timextender NG ODX. The data explorer shows the data type correctly for my table.
However, when I drag the table to the DSA, all fields appear as bigint type. (by the way, I have set
Quote Character to “ and Row Scan Depth to 0). Any help on how to resolve this issue, would be appreciated.
Best answer by Christian Hauggaard
Hi @Jan Stroeve
The synchronize task on the data source level synchronizes the structure of the source with the meta data stored in the ODX. For example, if a column is added in the source, and the data source is setup in the ODX to include all columns from that table, then executing the synchronize task will ensure that the column is also added to the ODX meta data and when the transfer task is next executed the new column will be included.
Furthermore, if a column is renamed in the data source, then executing the synchronize task will ensure that we do not get an “Invalid column name” error next time the transfer task is executed.
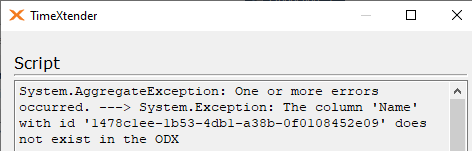
Synchronize objects, on the ODX level, will identify DW instances that are impacted by structural changes in the ODX. For example, if a column is renamed in the source, and the synchronization task has been run, the ODX transfer task will succeed, but the DW table execution (with a mapping to this field that has undergone the name change) will fail with the following error.
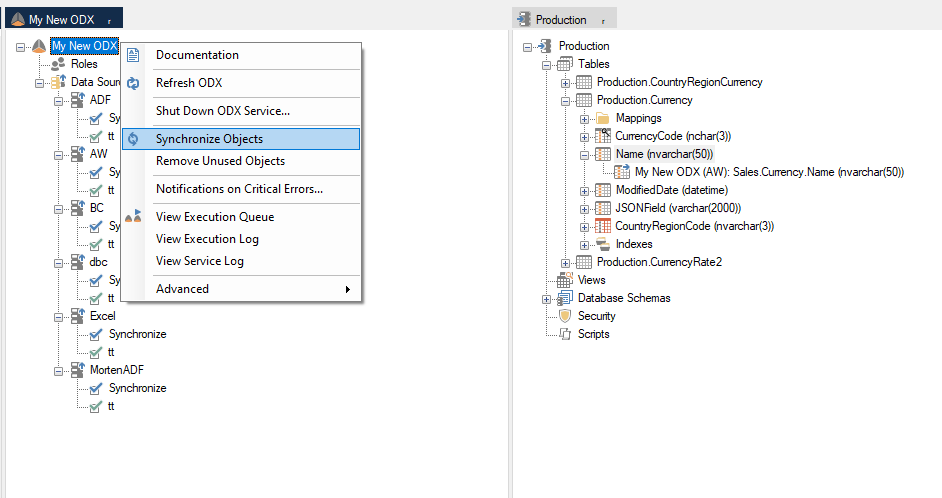
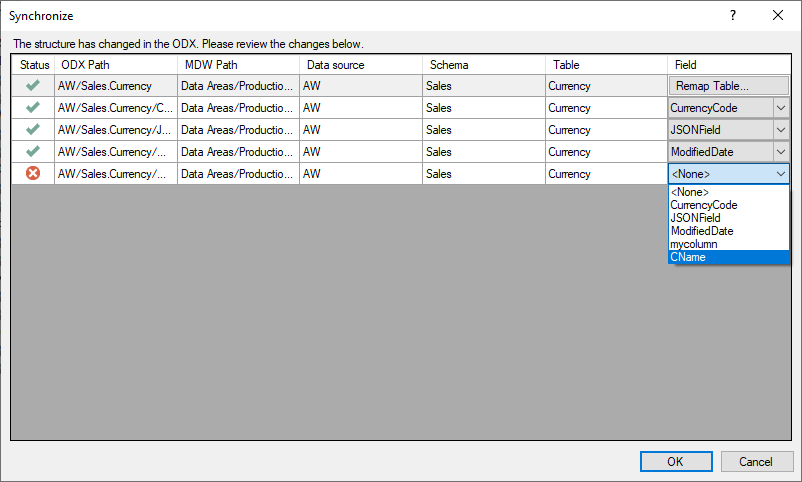
In the below example, the “Name” column in the Currency table was renamed to “CName”. As a result, the “Name” column no longer exists in the ODX, and therefore the mapping is broken in the DW table and the DW table execution will fail. However, by selecting “synchronize objects”, TimeXtender will identify columns in DW instances affected by the field name change, and allows the user to fix the broken mapping (select the new field name).
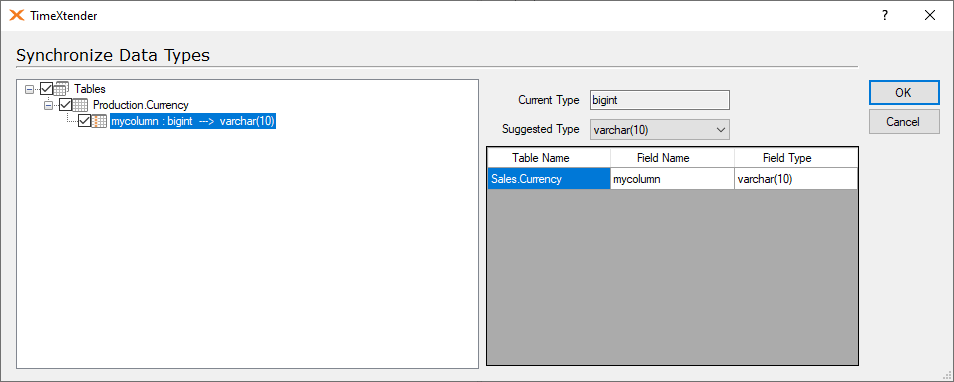
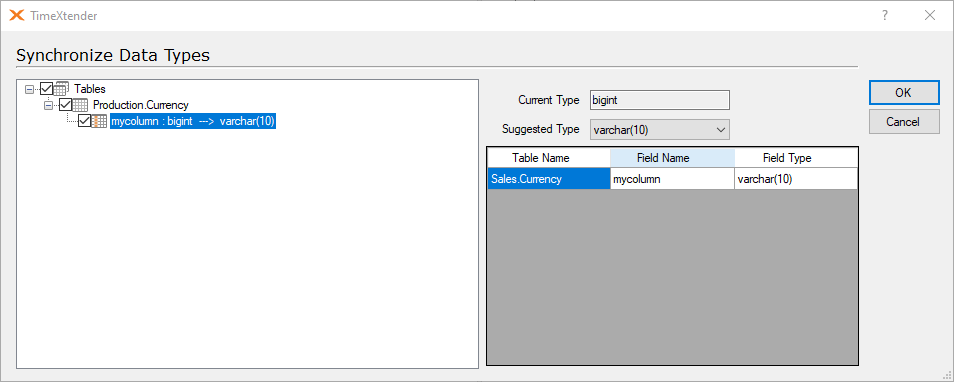
Furthermore, if the “new” field (i.e. renamed field) from the ODX storage that is chosen for the Synchronize Objects remapping, has a different data type than the target column, then TimeXtender will suggest a data type synchronization, so that the data type of the field in the DW table is changed accordingly.
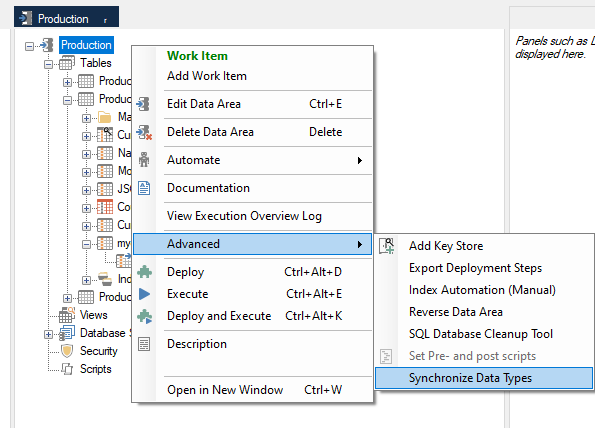
This suggestion can also be reached by right clicking on the DW table or data area, and selecting synchronize data types under advanced.
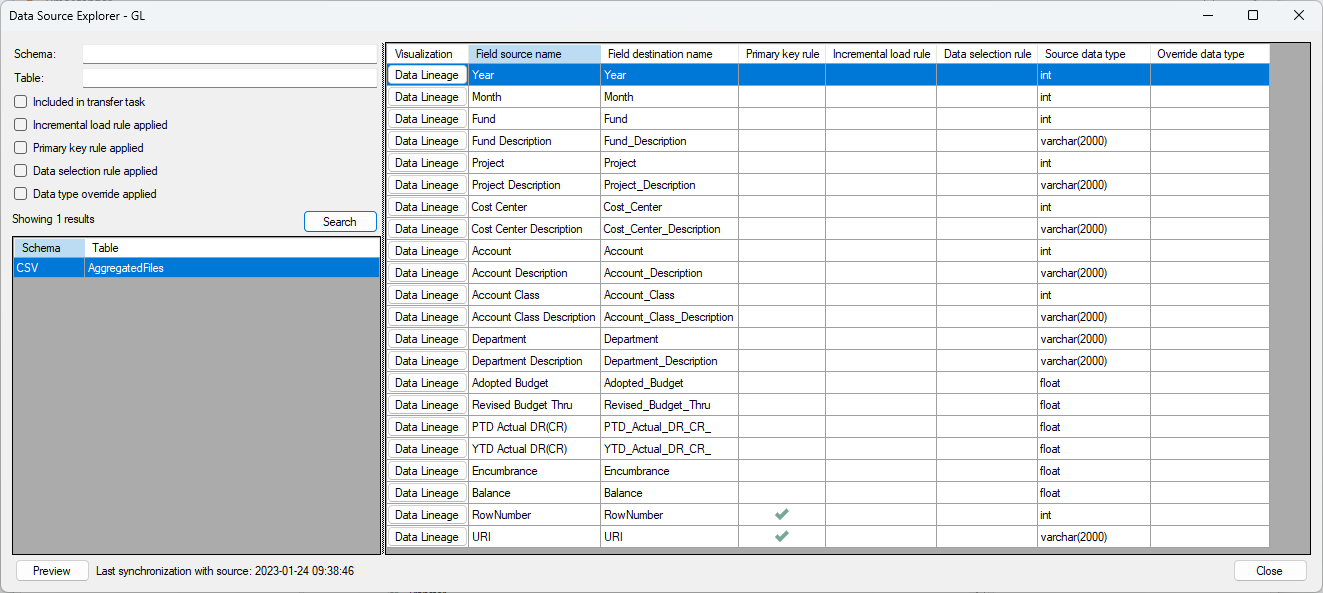
Can you show in images how it looks in the Data Source explorer, when you click on that table and add a image of it here?
If you want to use one where you can obscure info, Screenpresso is free and what we use.
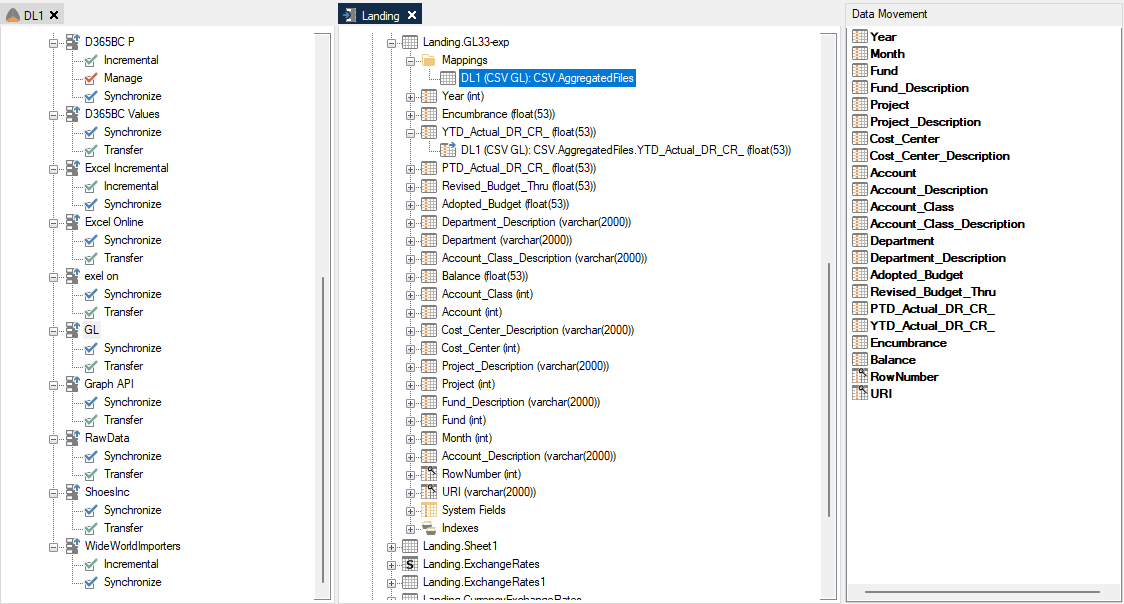
Can you create a similar image of its setup when you add it to the DSA, turn on Data Types beforehand and add it here?
If it is correct in the Data Source Explorer, differences will normally be due to Data Type Override rules, or someone manually changed the fields data types in the MDW Instance. Like in this setup I got.
Thanks for your explanations. Synchronize objects worked and I didn't have to change the CSV file. So, that's great.
I am not sure I understand the difference between the ODX synchronize task (on source level) and the Synchronize objects command on the ODX level. It would be great if you could explain the difference. Regards.
The synchronize task on the data source level synchronizes the structure of the source with the meta data stored in the ODX. For example, if a column is added in the source, and the data source is setup in the ODX to include all columns from that table, then executing the synchronize task will ensure that the column is also added to the ODX meta data and when the transfer task is next executed the new column will be included.
Furthermore, if a column is renamed in the data source, then executing the synchronize task will ensure that we do not get an “Invalid column name” error next time the transfer task is executed.
Synchronize objects, on the ODX level, will identify DW instances that are impacted by structural changes in the ODX. For example, if a column is renamed in the source, and the synchronization task has been run, the ODX transfer task will succeed, but the DW table execution (with a mapping to this field that has undergone the name change) will fail with the following error.
In the below example, the “Name” column in the Currency table was renamed to “CName”. As a result, the “Name” column no longer exists in the ODX, and therefore the mapping is broken in the DW table and the DW table execution will fail. However, by selecting “synchronize objects”, TimeXtender will identify columns in DW instances affected by the field name change, and allows the user to fix the broken mapping (select the new field name).
Furthermore, if the “new” field (i.e. renamed field) from the ODX storage that is chosen for the Synchronize Objects remapping, has a different data type than the target column, then TimeXtender will suggest a data type synchronization, so that the data type of the field in the DW table is changed accordingly.
This suggestion can also be reached by right clicking on the DW table or data area, and selecting synchronize data types under advanced.