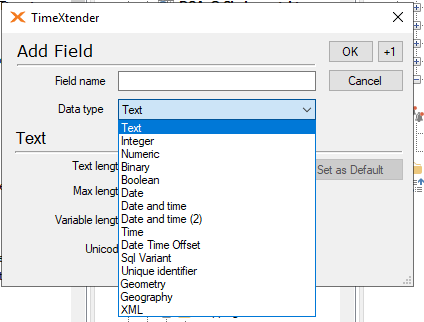
I need some guidence saving contents ofan endpoint as BLOOB. I can see that the version we use doesnot have an option for BLOOB but may be Text or Binary with maximum length can give me what i need.
So I have this RSD that i created
<api:script xmlns:api="http://apiscript.com/ns?v1" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<!-- See Column Definitions to specify column behavior and use XPaths to extract column values from JSON. -->
<api:info title="GetAllStops" desc="Generated schema file." xmlns:other="http://apiscript.com/ns?v1">
<!-- You can modify the name, type, and column size here. -->
<attr name="kortnavn" xs:type="string" readonly="false" other:xPath="/json/kortnavn" />
<attr name="tittel" xs:type="string" readonly="false" other:xPath="/json/tittel" />
<attr name="virksomhet" xs:type="string" readonly="false" other:xPath="/json/virksomhet" />
<attr name="opprinnelse" xs:type="string" readonly="false" other:xPath="/json/opprinnelse" />
<attr name="navn" xs:type="string" readonly="false" other:xPath="/json/navn" />
<attr name="vedleggID" xs:type="string" readonly="false" other:xPath="/json/elements/id" />
</api:info>
<api:set attr="urlbase" value="https://some.url.io"/>
<api:set attr="filein.DataModel" value="DOCUMENT" />
<api:set attr="filein.JSONPath" value="$." />
<api:set attr="filein.URITemplate" value="[urlbase]?kortnavn=ABCD&fomDato=1999-01-01"/>
<api:set attr="filein.ElementMapPath#" value="/json/uuid" />
<api:set attr="filein.ElementMapName#" value="file_id" />
<api:set attr="stopin.DataModel" value="FLATTENEDDOCUMENT" />
<api:set attr="stopin.EnablePaging" value="TRUE" />
<api:set attr="stopin.JSONPath" value="$.;$.elements;" />
<api:set attr="stopin.URITemplate" value="[urlbase]/file_id"/>
<!-- The GET method corresponds to SELECT. Here you can override the default processing of the SELECT statement. The results of processing are pushed to the schema's output. See SELECT Execution for more information. -->
<api:script method="GET">
<api:set attr="filein.URI" value="[filein.URITemplate]"/>
<api:call op="jsonproviderGet" in="filein" out="fileout">
<api:set attr="stopin.URI" value="[stopin.URITemplate | replace('file_id', [fileout.file_id])]"/>
<api:call op="jsonproviderGet" in="stopin" out="stopout">
<api:set attr="out.kortnavn" value="[stopout.kortnavn | allownull()]"/>
<api:set attr="out.tittel" value="[stopout.tittel | allownull()]"/>
<api:set attr="out.virksomhet" value="[stopout.virksomhet | allownull()]"/>
<api:set attr="out.opprinnelse" value="[stopout.opprinnelse | allownull()]"/>
<api:set attr="out.vedleggID" value="[stopout.vedleggID | allownull()]"/>
<api:push item="out"/>
</api:call>
</api:call>
</api:script>
</api:script>Now, the BLOOB file has another endpoint: [urlbase]/file_id/attachment/vedleggID
I have urlbase which is https://some.url.io
I have file_id from that code above
I have vedleggID from the code above
So the end pint loosk like this: [urlbase]/123abc456defghi/attachment/222eee444ggg66677
How do i now build the RSD futher to get the attachment into the DVH?