Hi Community,
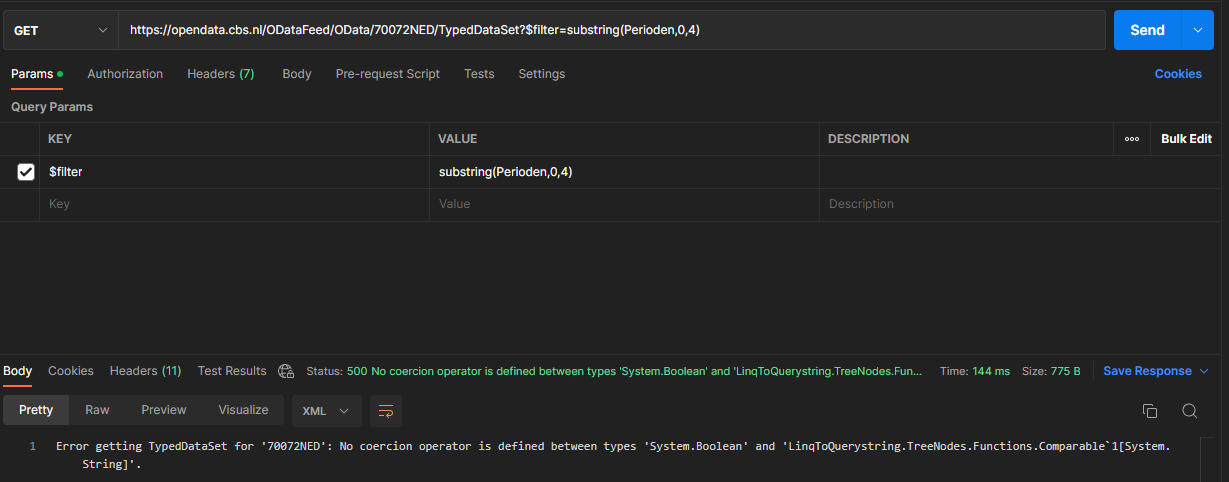
I'm trying to connect the database from CBS (in both old and new version of TX). The original request URI gives an error response that the query exceeds 10.000 rows at test connection. This is a well-known issue with data from CBS, so I adapted the URI to include a filter. I tested this new query both in Postman and Qlik Sense Desktop and there the filter works and I retrieve aprox. 2.500 rows, from 2020 until 2022.
Using this query in TX does not work unfortunately. The error that normally encounters when testing connection does not pop-up, however, the table still retrieves 10.000 rows. Probably just random from all available years (1995 t/m 2022).
I am using below request URI:
https://opendata.cbs.nl/ODataFeed/OData/70072NED/TypedDataSet?$filter=substring(Perioden,0,4) ge '2020' and substring(Perioden,4,2) eq 'JJ'
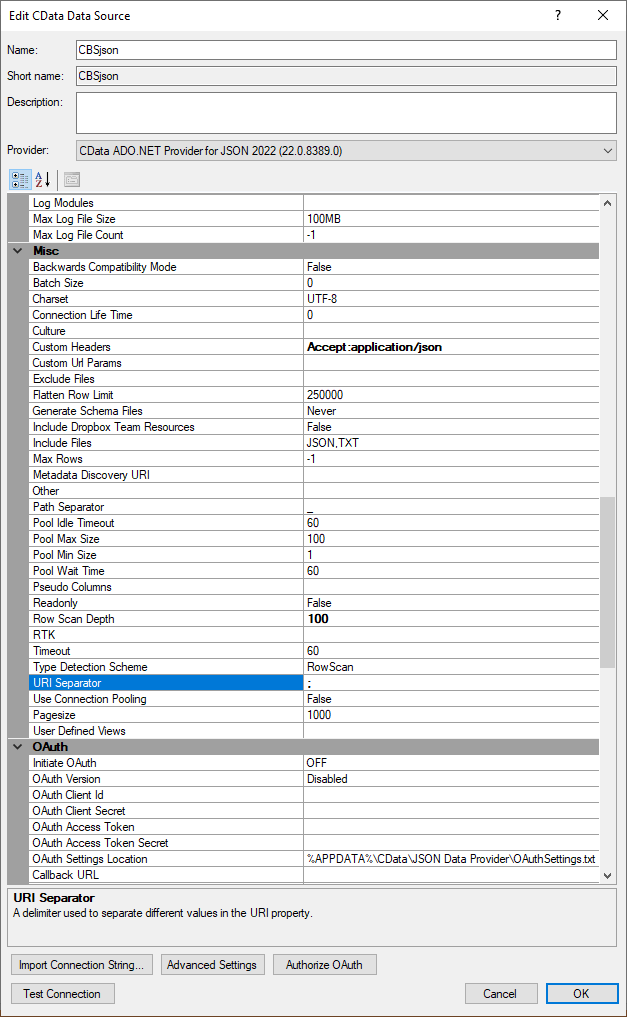
with custom header: accept:application/json
Any ideas what causes this? Thanks!