Hi community,
I have a MariaDB data source which I connect to using ODX Server (v 6346) and the CData/ADO.net connector for MariaDB v 23.0.8565.0.
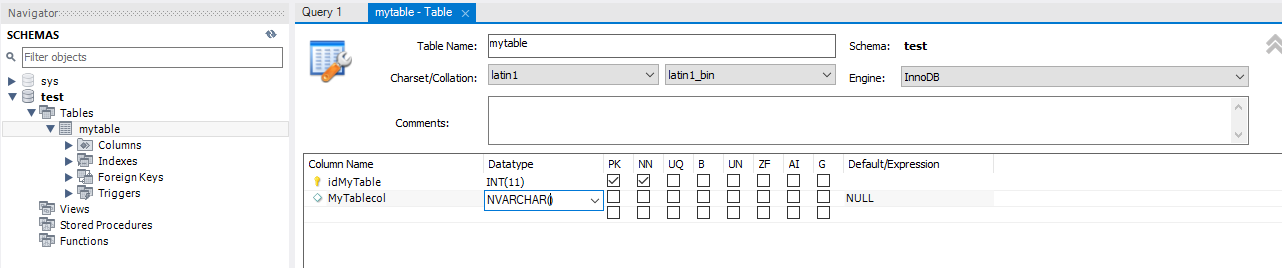
The source database is set to collation utf8mb4_general_ci. I noticed by copying from ODX Server to a Data Area that some special characters are slightly different than the source/ODX. I can fix this by manually changing the data type to nvarchar instead of varchar, but that is a lot of field editing.
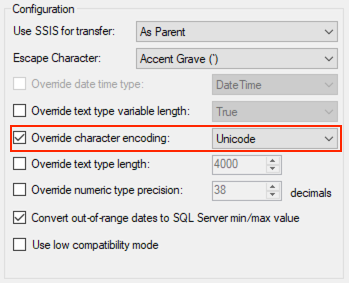
The Override Data Type function can help as well, but as we have a wide range of field lengths, this also means a lot of override rules.
Is there a way to tell ODX Server that all varchar fields should be unicode/nvarchar by default (eg. based on the source database collation)?
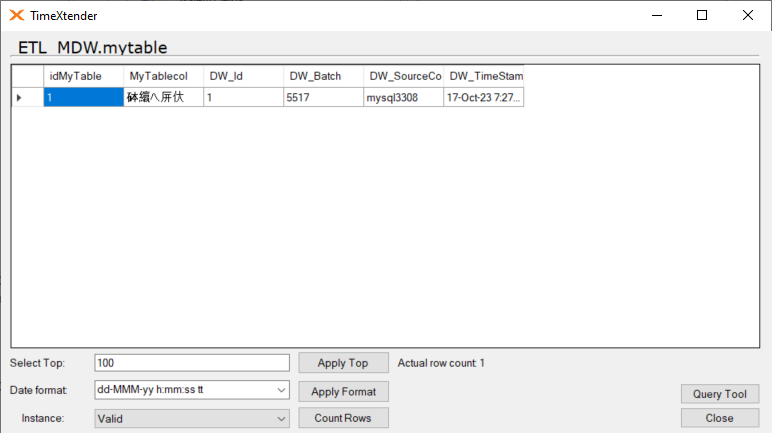
Example from ODX Server. These fields should all be nvarchar(xx) instead of varchar(xx):

Implementing this idea would work for me as well :)
In TX v20 Business Units, we had this option: