So want a rowcount, count(*) on our tables loaded in de ODX. Our ODX is configured with ADSL (Azure Datalake Gen2 Storage).
So we want to use the ODX TimeXtender Parquet Data Source connector (23.1.1.0 64bit).
Is it possible to run a count(*) query to our tables when we setup this connection to our ADSL? We need to know how many records are loaded in all of our tables.
We have a lot of incremental tables, so we worry of all the increment files in the lake. Do we need to configure some sort of a aggregation ?
Is there documentation available how to configure this ? The connector has a lot of options, we don’t know all the details.
Hope somebody has some experience with this Parquet connector.
Thank you in advance for looking into this.
Regards,
Arthur
Best answer by Christian Hauggaard
Hi @avanrijn
Regarding the aggregation of incremental files please see the roll up option for storage management tasks:
Regarding the row count, this is not supported currently in the TimeXtender Parquet data source. Please create a product idea for this.
Some workarounds according to ChatGPT:
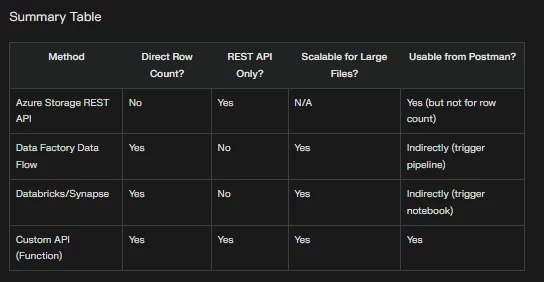
Azure Data Factory or Synapse Pipelines Use a Data Flow activity with an aggregate transformation to count rows in a Parquet file The Lookup activity is limited (max 5,000 rows and 4 MB) For larger files, use Mapping Data Flows, Databricks, or Synapse serverless SQL Azure Databricks or Synapse Analytics Use a notebook (PySpark or SQL) to read the Parquet file and count rows, then expose this result via a custom API or Azure Function This approach is scalable for large files (millions or billions of rows) Custom REST API Build an Azure Function or web service that reads the Parquet file (using a library like Parquet.Net or PyArrow), counts the rows, and returns the count via an HTTP endpoint This API can then be called from Postman.
Using Postman
You can use it to call the Azure Storage REST API to list or download files, but you cannot get row counts directly
To get a row count, you would need to:
Deploy a custom API (such as an Azure Function) that reads the Parquet file and returns the row count
Call this custom API from Postman by setting up OAuth2 authentication and sending a GET or POST request to your endpoint
Example Workflow
Create an Azure Function that:
Authenticates to your Data Lake.
Downloads the Parquet file.
Uses a library (e.g., PyArrow for Python, Parquet.Net for .NET) to read and count rows.
Returns the count as a JSON response
Register the Function App/API in Azure AD and grant it permissions to access your Data Lake
In Postman:
Use OAuth2 to authenticate (client credentials or authorization code flow)
Make a request to your custom API endpoint.
View the returned row count in the response.
Key Points
Azure Storage REST API cannot count rows in Parquet files directly
You need to process the file content (using Data Factory, Databricks, Synapse, or a custom API).
Postman can call any REST endpoint, so if you expose row count via a custom API, you can retrieve it from Postman
Regarding the aggregation of incremental files please see the roll up option for storage management tasks:
Regarding the row count, this is not supported currently in the TimeXtender Parquet data source. Please create a product idea for this.
Some workarounds according to ChatGPT:
Azure Data Factory or Synapse Pipelines Use a Data Flow activity with an aggregate transformation to count rows in a Parquet file The Lookup activity is limited (max 5,000 rows and 4 MB) For larger files, use Mapping Data Flows, Databricks, or Synapse serverless SQL Azure Databricks or Synapse Analytics Use a notebook (PySpark or SQL) to read the Parquet file and count rows, then expose this result via a custom API or Azure Function This approach is scalable for large files (millions or billions of rows) Custom REST API Build an Azure Function or web service that reads the Parquet file (using a library like Parquet.Net or PyArrow), counts the rows, and returns the count via an HTTP endpoint This API can then be called from Postman.
Using Postman
You can use it to call the Azure Storage REST API to list or download files, but you cannot get row counts directly
To get a row count, you would need to:
Deploy a custom API (such as an Azure Function) that reads the Parquet file and returns the row count
Call this custom API from Postman by setting up OAuth2 authentication and sending a GET or POST request to your endpoint
Example Workflow
Create an Azure Function that:
Authenticates to your Data Lake.
Downloads the Parquet file.
Uses a library (e.g., PyArrow for Python, Parquet.Net for .NET) to read and count rows.
Returns the count as a JSON response
Register the Function App/API in Azure AD and grant it permissions to access your Data Lake
In Postman:
Use OAuth2 to authenticate (client credentials or authorization code flow)
Make a request to your custom API endpoint.
View the returned row count in the response.
Key Points
Azure Storage REST API cannot count rows in Parquet files directly
You need to process the file content (using Data Factory, Databricks, Synapse, or a custom API).
Postman can call any REST endpoint, so if you expose row count via a custom API, you can retrieve it from Postman