Hi community,
I’ve a question about the ‘PK’ table that is created in the ODX when you enabled the ‘Handle primary key updates’ and ‘Handle primary key deletes’.
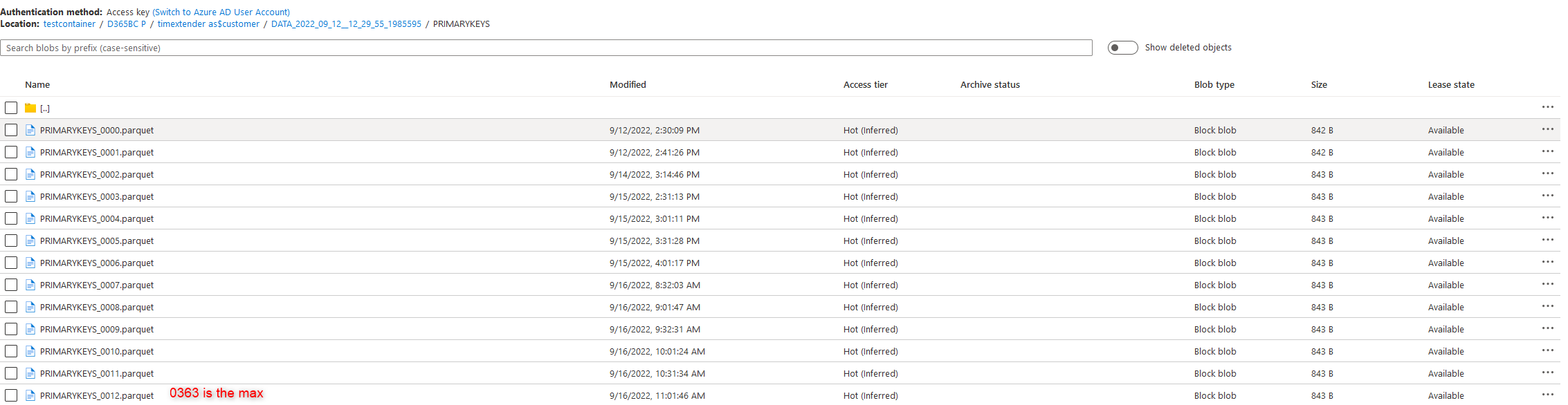
I’ve noticed the ODX database (SQL Database) is growing rapidly in disk space after enable an incremental load schedule to reload data every 5 minutes. When I used the default SQL ‘Disk usage by top tables’ I noticed the PK tables are the biggest in terms of disk space.
My PK table of the GL Entry table contains 4.5 billion rows! And is 95 GB. While my DATA table contains only 118 million records.
When I query the PK table and filter the primay key in this table on 1 value. This value is saved 75 times in this table. For every odx_batch_number (odx_batchnumber 0 – 74). Is this normal? I think it is a bit strange that my PK tables are the biggest tables in the ODX in terms of disk space.
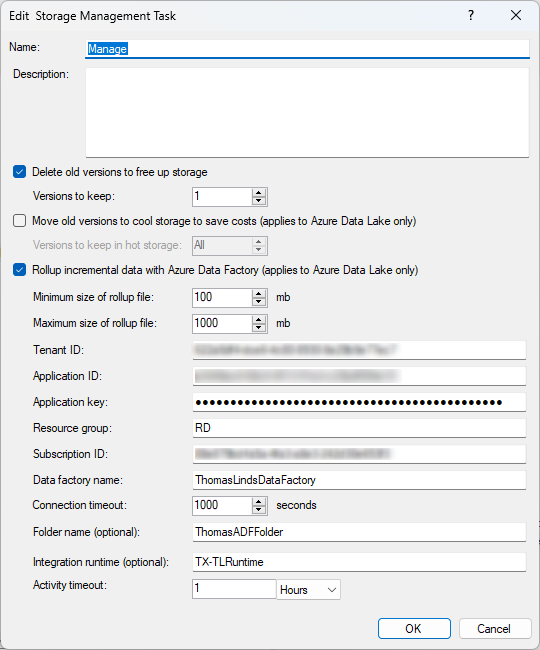
Even when I run the storage management task. It doesn’t clean the PK table’s. It always contains the primary key for every odx batch load.
The customer is using version 20.10.37.64