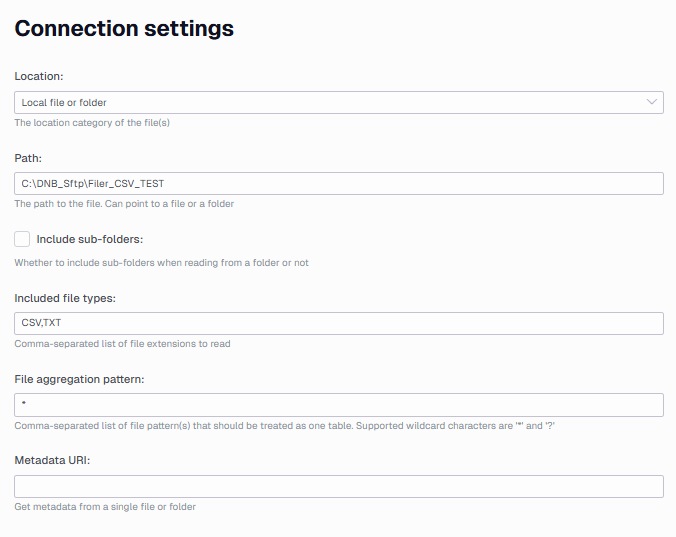
Hi,
We are trying to connect to several CSV files stored in a local folder. While we can successfully synchronize the data source and perform a full load in the ODX, we encounter an error when attempting to add the table to our data area (DSA).
The issue lies in the path to the Parquet file stored in Azure. The correct path should be:
CSV_DNB/csv_*/DATA_2024_11_28__11_09_50_2219585/DATA/DATA_0000.parquet
However, the path Timextender is looking for is:
CSV_DNB/csv_^*/DATA_2024_11_28__11_09_50_2219585/DATA/DATA_0000.parquet
It seems that Timextender is misinterpreting the automatically generated name and adds a ^ character.
I also attempted to use a specific file aggregation pattern, such as;H100.*.csv
(all files in folder have the prefix H100 followed by a random number). However, I encountered the same error. Is there a way to specify the name of the table generated in the ODX? It seems like the “File aggregation pattern” is the issue. Do you have any idea how to fix this?
-Execute Execution Package Execution Queue Default 'Failed'
System.AggregateException: Pipeline execution failed ---> System.Exception: {
"errorCode": "ActionFailed",
"message": "Activity failed because an inner activity failed; Inner activity name: TIMEXTENDER COPY DATA, Error: ErrorCode=UserErrorFileNotFound,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=ADLS Gen2 operation failed for: Operation returned an invalid status code 'NotFound'. Account: 'xxx'. FileSystem: 'containerodx'. Path: 'CSV_DNB/csv_^*/DATA_2024_11_28__11_09_50_2219585/DATA/DATA_0000.parquet'. ErrorCode: 'PathNotFound'. Message: 'The specified path does not exist.'