Hello,
TimeXtender 20.10.31.64
ODX: 20.10.31
We are currently running a database on hyperscale with 12vcores and premium memory optimized hardware. ODX is a data lake.
We are running execution packages on 4 threads and we want to reduce our odx transfer times as that is out biggest impact right now.
This is an example of a load.

I am seeing long ODX transfer times for very small tables that I cant find the cause of or explain.
We have alot of small tables (see example below) that is taking 1-3 minutes, while some tables doing data cleansing on 1million + rows is doing it in the same amount of time.
See this small table that is 400 rows, no transformations and only 10 columns.
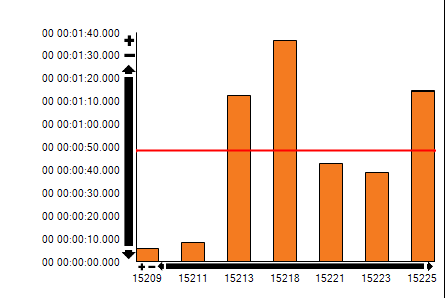
I can see we are peaking log io at 100% during certain periods.
However, that seems to be during the later parts of the loads and not during odx transfer in the start.

Is there any thing that can cause this or possibility to improve it?
Thank you,
Victor