

I'm reading XML files from a folder using cdata XML provider. This is working fine and using incremental loading also works. The issue I'm having is that there is an attribute defined in my rsd file that is not always present in the XML files. When ODX starts reading the folder and the first file it parses doesn't have this field it skips the field for all following files. Similarly if the first file does have the attribute all the rest is parsed ok. Is this a bug or is there a setting I'm not aware of? Or maybe a definition in rds that could help?
Solved
ODX cdata XML missing attribute
Best answer by Thomas Lind
Hi
Sorry for the late answer.
I would be sure to add all the necessary fields that are used across all XML files.
Then in the call command of the RSD file, I would add the following.
<!-- The GET method corresponds to SELECT. Here you can override the default processing of the SELECT statement. The results of processing are pushed to the schema's output. See SELECT Execution for more information. -->
<api:script method="GET">
<api:set attr="method" value="GET"/>
<api:call op="xmlproviderGet" in=”callin” out=”callout”>
<api:set attr="out.country" value="[callout.country | allownull()]"/>
<api:set attr="out.id" value="[callout.id | allownull()]"/>
<api:set attr="out.field1" value="[callout.field1 | allownull()]"/>
<api:set attr="out.field2" value="[callout.field2 | allownull()]"/>
<api:set attr="out.name" value="[callout.name | allownull()]"/>
<api:push item="out"/>
</api:call>
</api:script>Be sure all fields are mentioned in the call procedure and that they have the allownull() function. The callout that becomes a out is a way to reset the order, or you could experience that it puts the values in the wrong field.
An alternative method is to use the Metadata Discovery URI
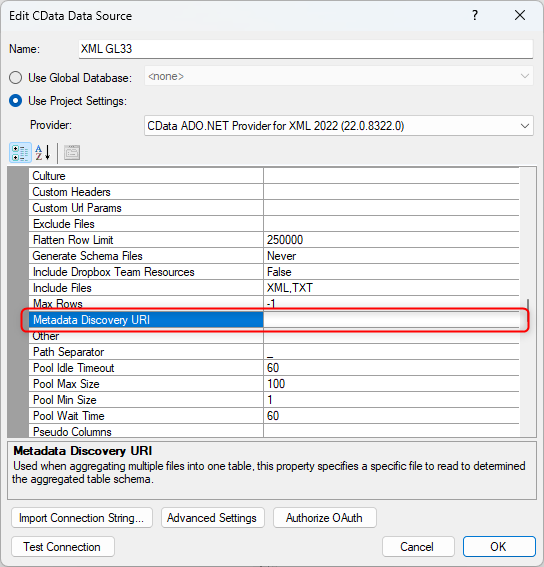
You create a XML file that contains all the fields and one value of the type you want it to become. Then you point at this file in that field.



Reply
Most helpful members this week


Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.
