

Hello,
TimeXtender: 20.10.40.64
ODX: 20.10.31
We are using the ODX and TimeXtenders SQL database connector to get data from a synpase database.
Sometimes the synpase databas seems to have problems, where a query runs and doesn’t complete (a seperate issue we are working on).
However what happens in TimeXtender in the ODX is that the transfer task keeps running indefinitely and never times out, leading timextender execution package to run but just sits there waiting for the odx transfer task to finish. However nothing fails anywhere, so we do not get an alert.
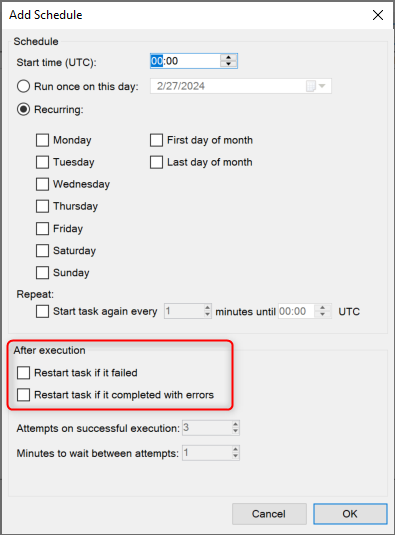
We need some way to be able to capture this.
Is there anyway to set up one or both of these things in TimeXtender or if you have any other ideas?
1. Kill the transfer task if it takes more then X minutes
2. Get an alert on failure or long running task
Thank you!
Solved
ODX Transfer task running indefinitely
Best answer by Christian Hauggaard
Hi
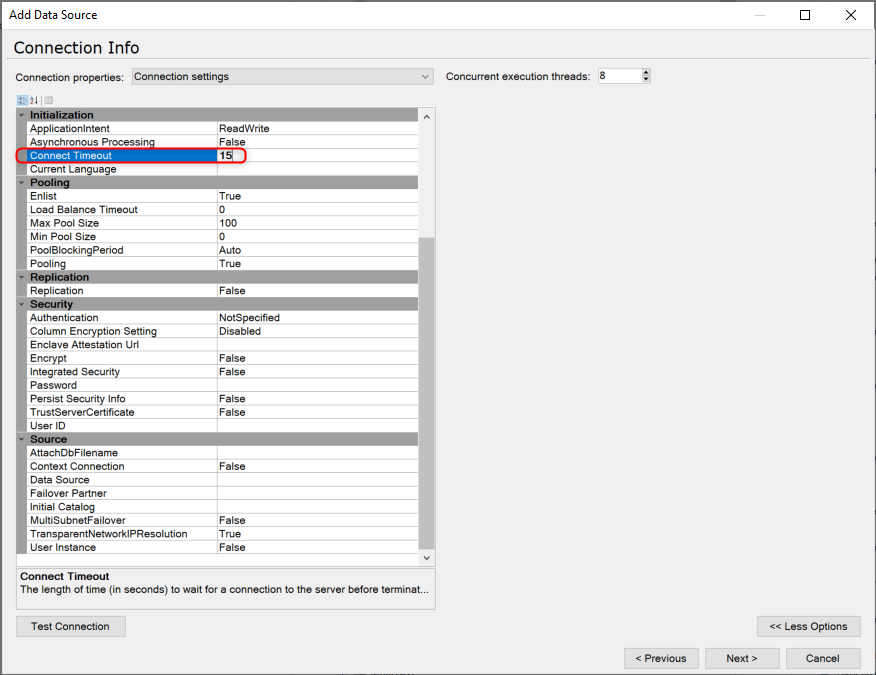
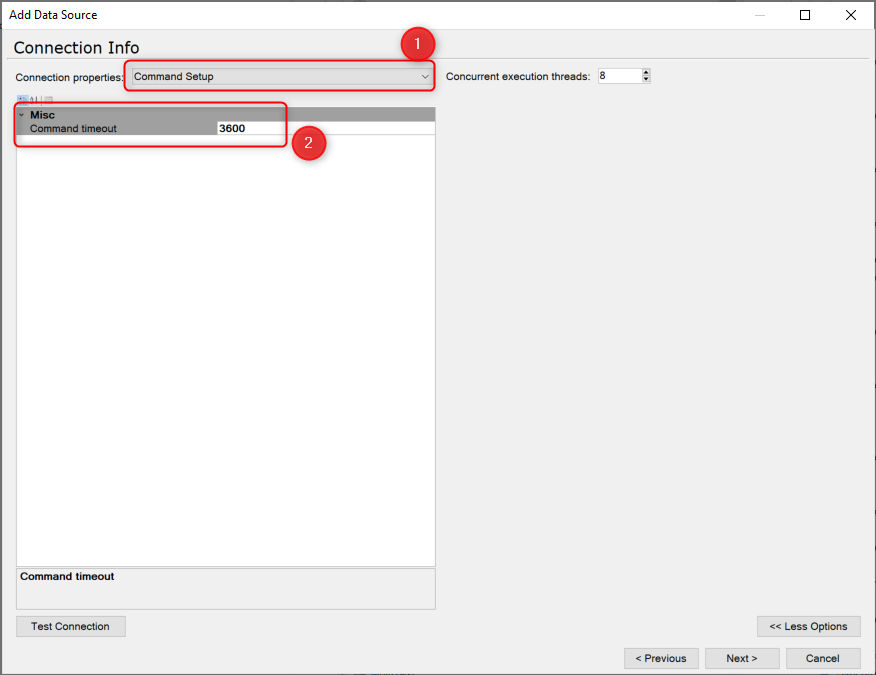
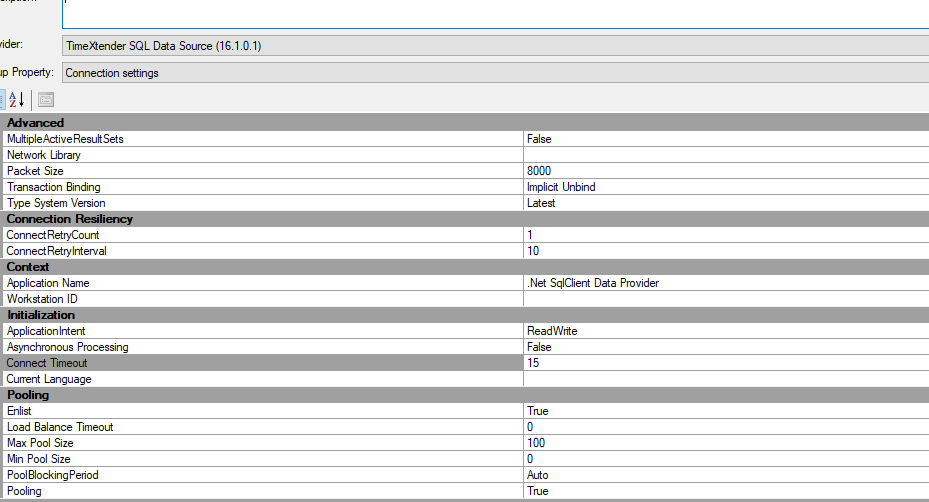
Could you please lower the command timeout to 300 to troubleshoot further? How many tables do you have for the transfer task for the TX SQL data source?




Reply
Most helpful members this week

Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.
