I have a setup of a TimeXtender 20.10.40.64, ODX, ADL, ADF, Self hosted IR which I get to work just fine.
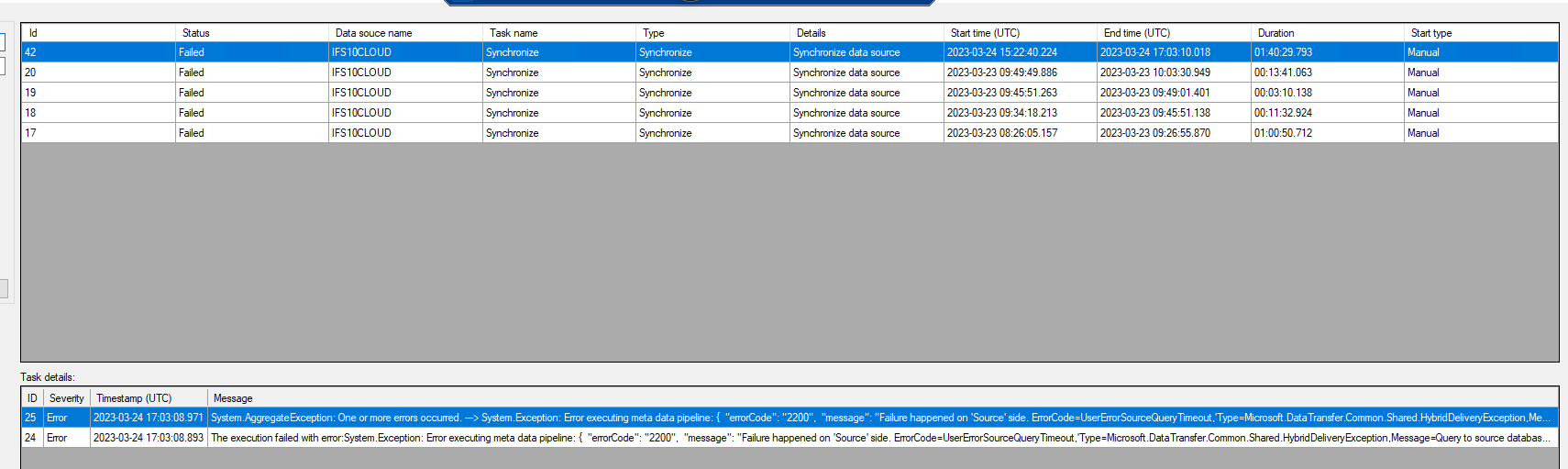
I need to extract data from an IFS10 source, Oracle database, and it works until syncing then it seems to start an endless loop and never finish or gives an error.
In TX I have
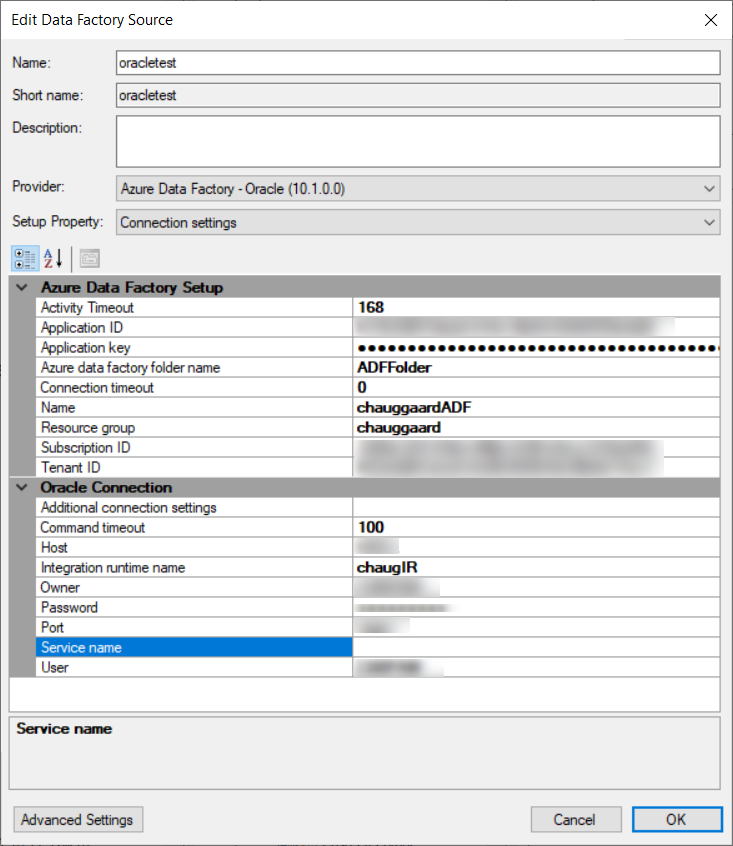
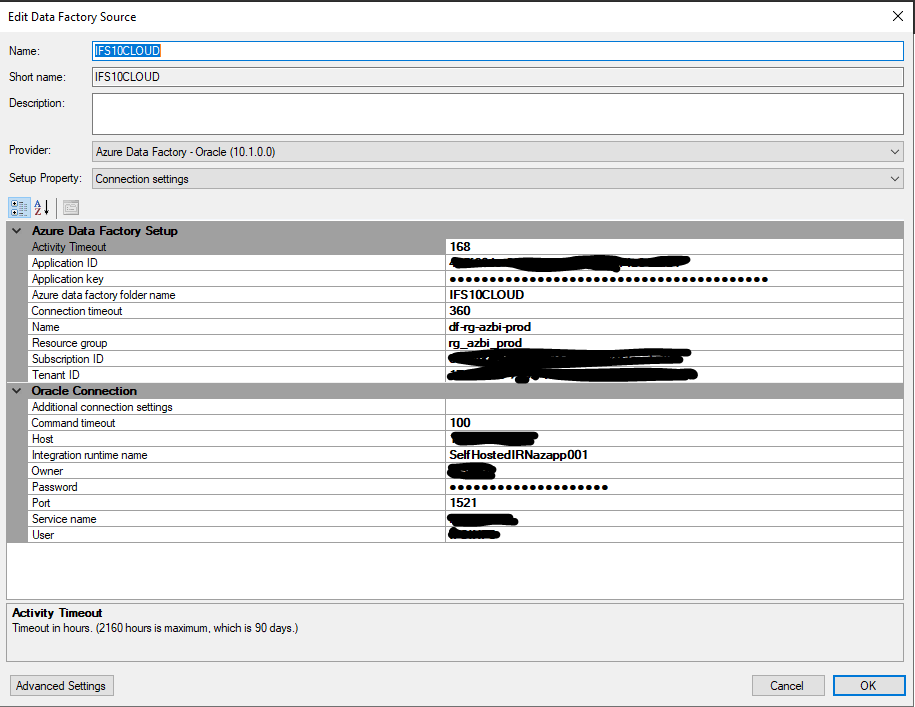
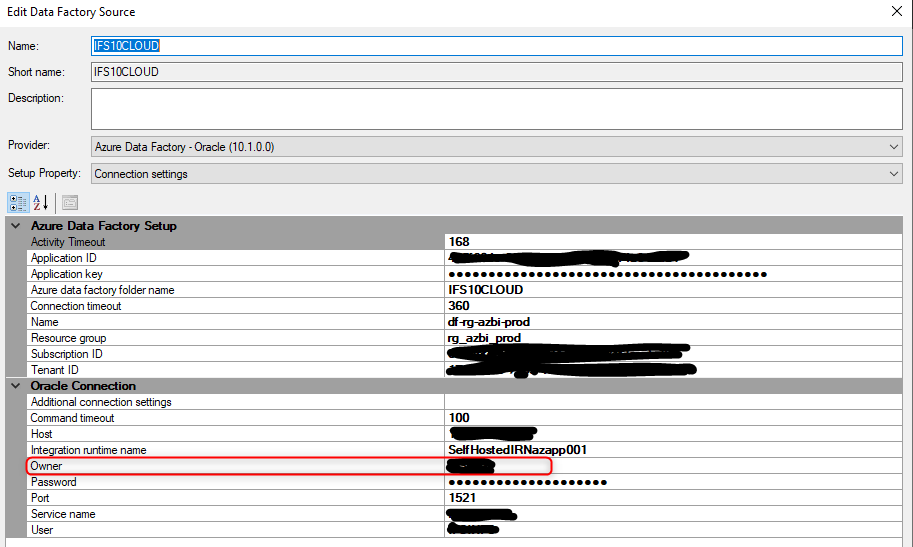
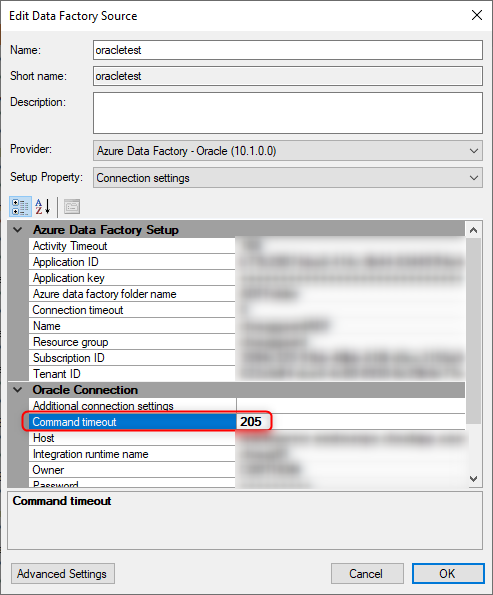
- setup a new data source, Azure Data Factory - Oracle
- included all connection info information
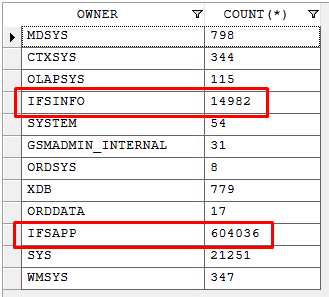
- In Select tables I click “Search” and get all the tables available in the Oracle DB
- I Include a couple a tables
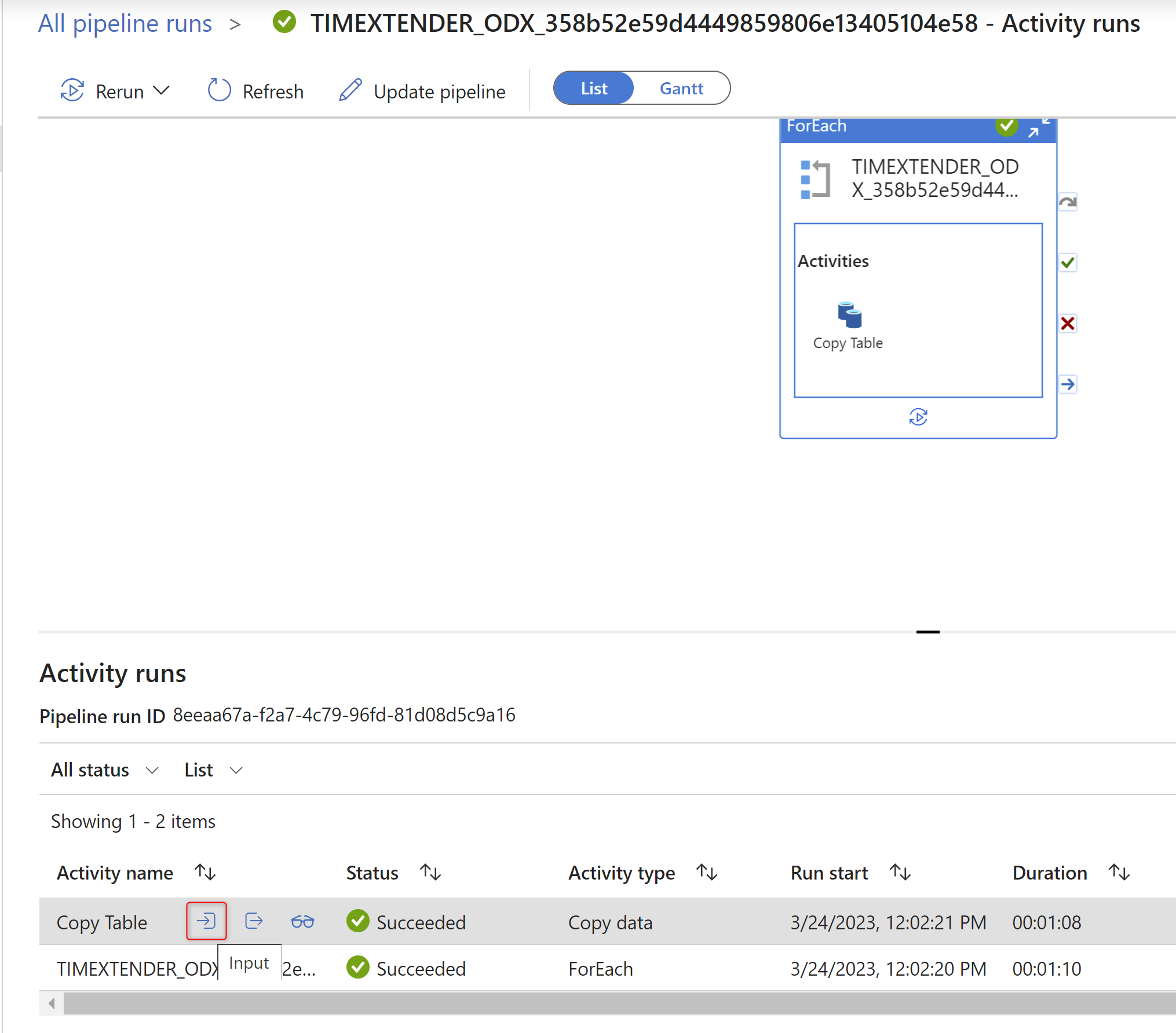
- Setup a transfer task
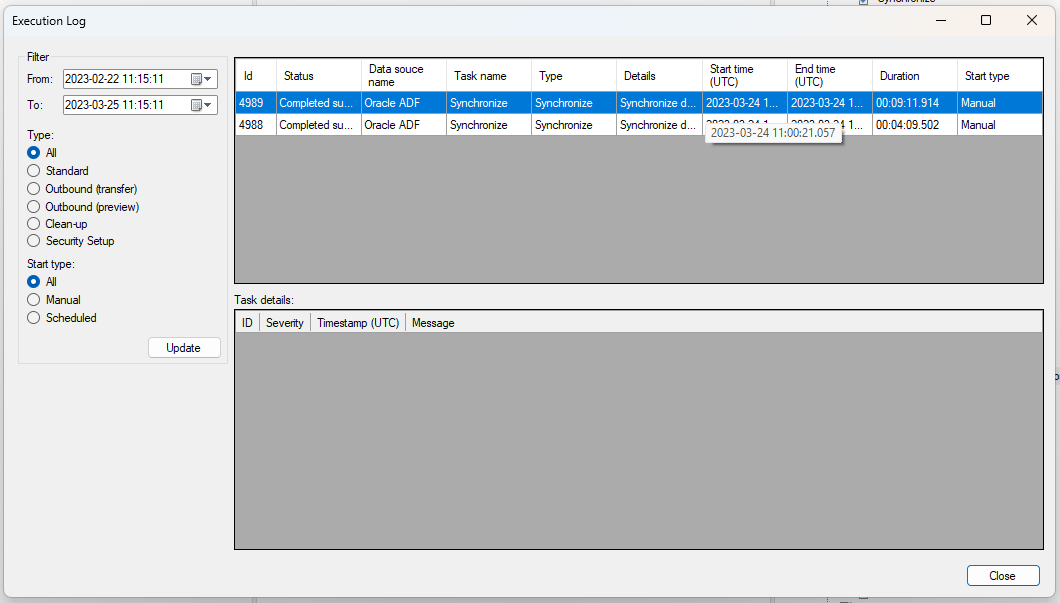
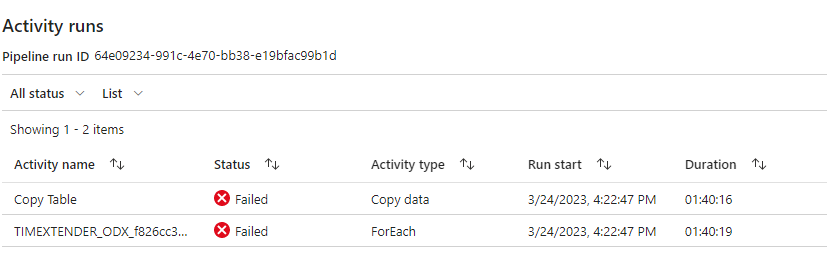
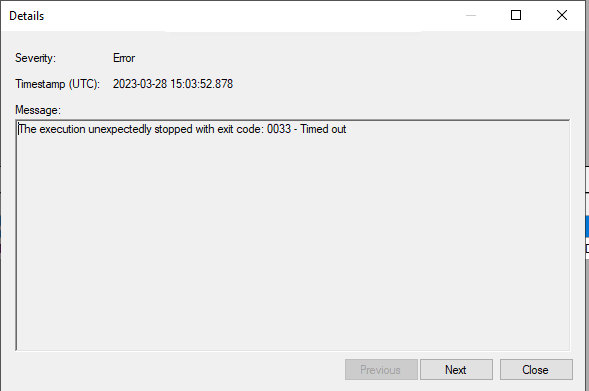
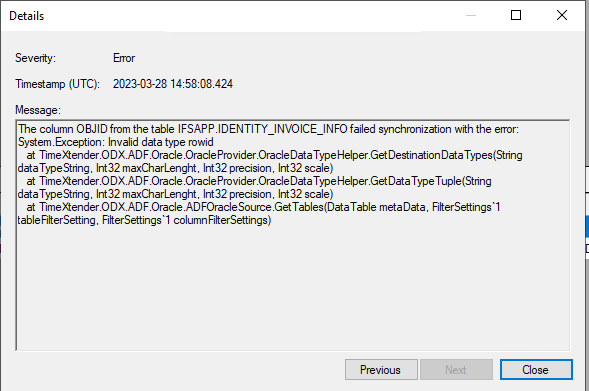
- Syncing starts running and I can see in ADF that is is running but it never receives any data from the data source
I have tested from a SQL data source with ADF and it works just fine, both sync and transfer
I have in ADF tested to preview tables in the dataset created by TX and I can preview tables from Oracle DB just fine. I have even tried to create my own pipeline in ADF to copy data from the same data source to the same sink that TX created and it works just fine. It creates a parquet file in the destination, ADL, and I can open the file and see that the data is correct.
So anyone have an idea why TX can’t sync?