Hi,
I have a setup of a TimeXtender 20.10.41.64, ODX, ADL, ADF, Self hosted IR which I get to work just fine.
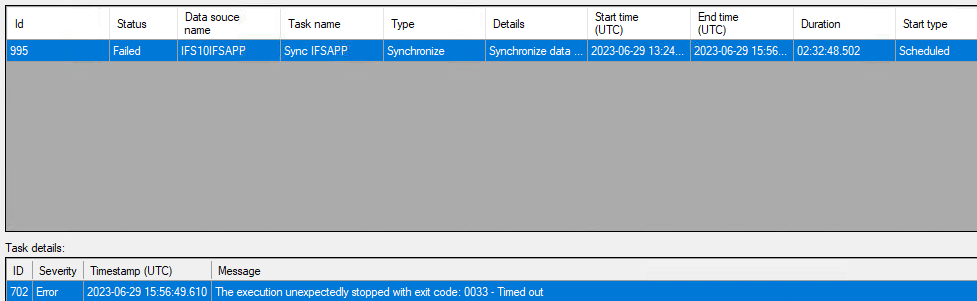
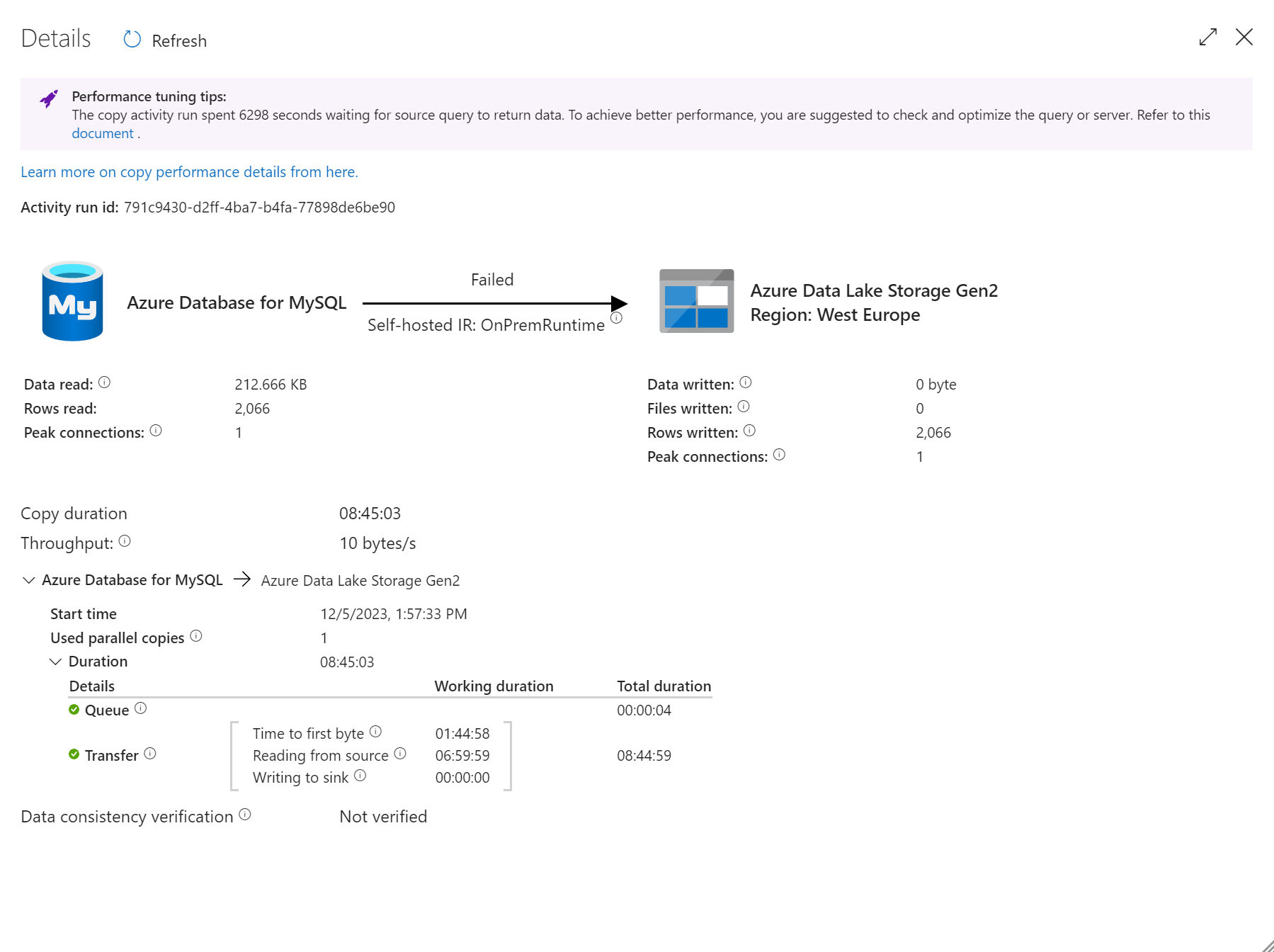
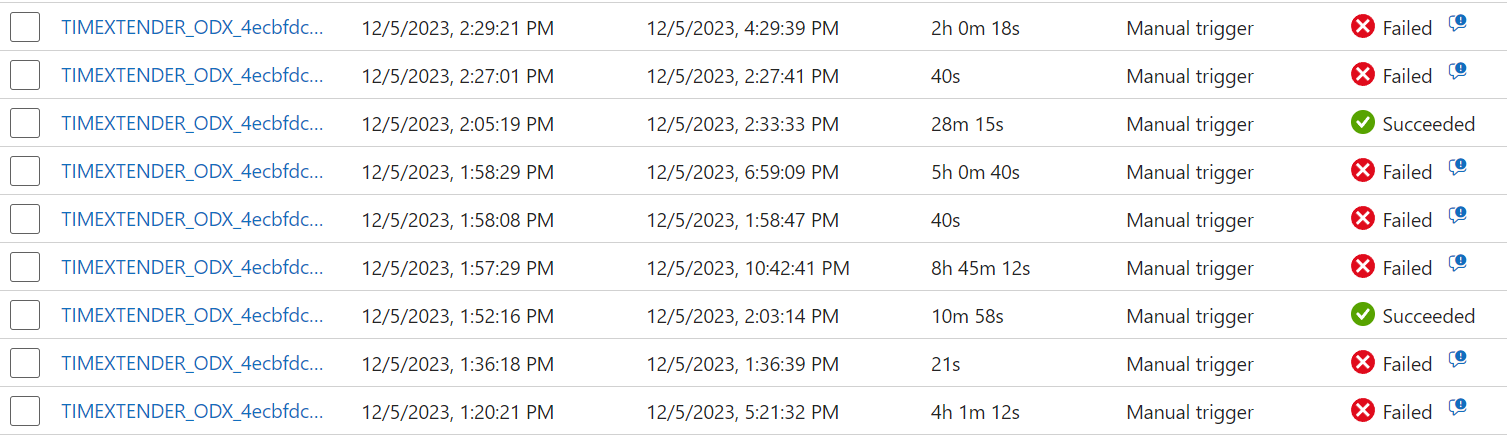
I need to extract data from an IFS10 source, Oracle database, and the sync is too slow so it times out and fail after 2 hours. The data source is provided by a third party and which means that the customer doesn’t have control to change any settings and 2 hours should be enough time for a sync. The customer have a couple of TX environments
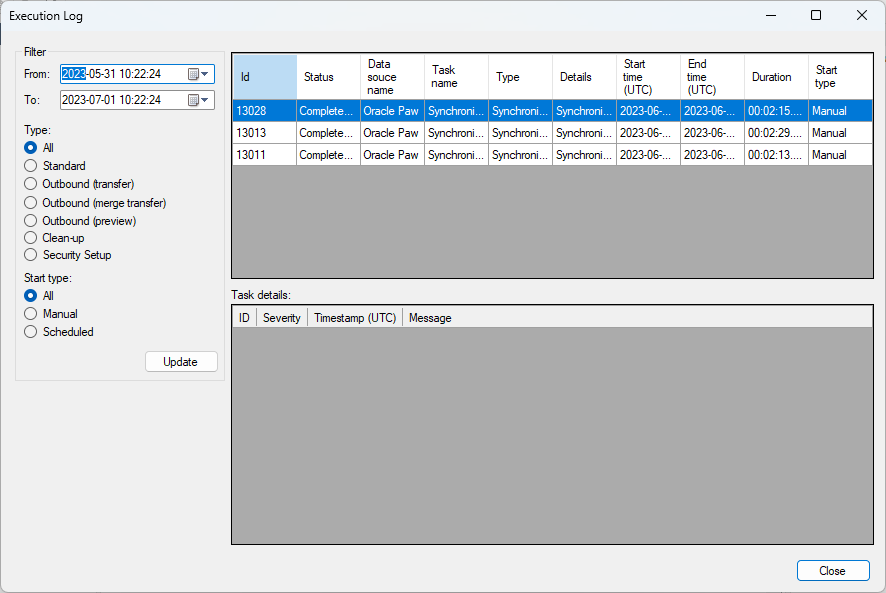
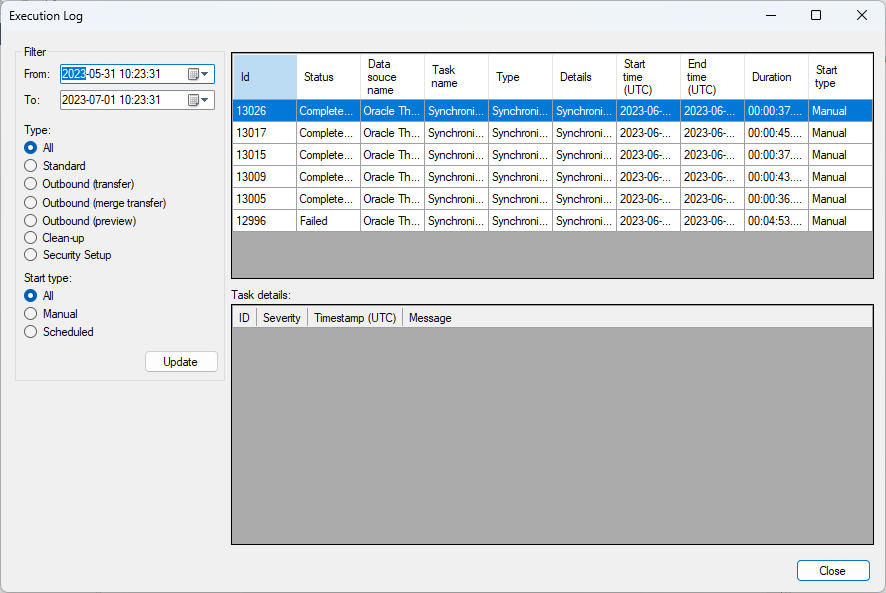
After many tests and discussing with the customer a similar problem have occurred before, but in an environment not using ODX server, where a sync took over 2 hours and this was fixed in Timextender release 20.10.3, issue “8889: Oracle slow synchronization - affects all bit specific data sources”. After this release the customer says the sync only takes about 10-15 min.
Could this be a problem in ODX server as well? I managed to get a successful sync with version 20.10.40 which took about 2 hours but after an upgrade to 20.10.41 I’ve managed to get 1 successful sync on 16 tries over 6 days where I’ve tried to do the sync different times during the day.
Is it possible to check if the issue 8889 could also affect ODX server and something possible to fix?