


Relates to TimeXtender Data Integration 6024.1 and later versions
Incremental Load Rules in a Data Areas
Tables within a Data Area can have multiple mappings, with each mapping possessing its own incremental load rules, rather than a single overarching rule. This allows for flexibility: one mapped table can run a full load, another can run incrementally with deletes, and a third can run incrementally with updates.
Incremental loading operates by using the max batch number from the incremental table and the source table, comparing it with the Primary Key table (the _PK table) to identify updates, deletes, or new rows. Therefore, it is recommended to configure the primary key field for the table when setting it up for incremental loading.
To set up incremental loading for a table in a Data Area, incremental loading must first be configured in the data source within the Ingest instance to which the table is mapped. For detailed instructions, refer to Incremental Load in an Ingest Instance.
Setting up incremental load on tables
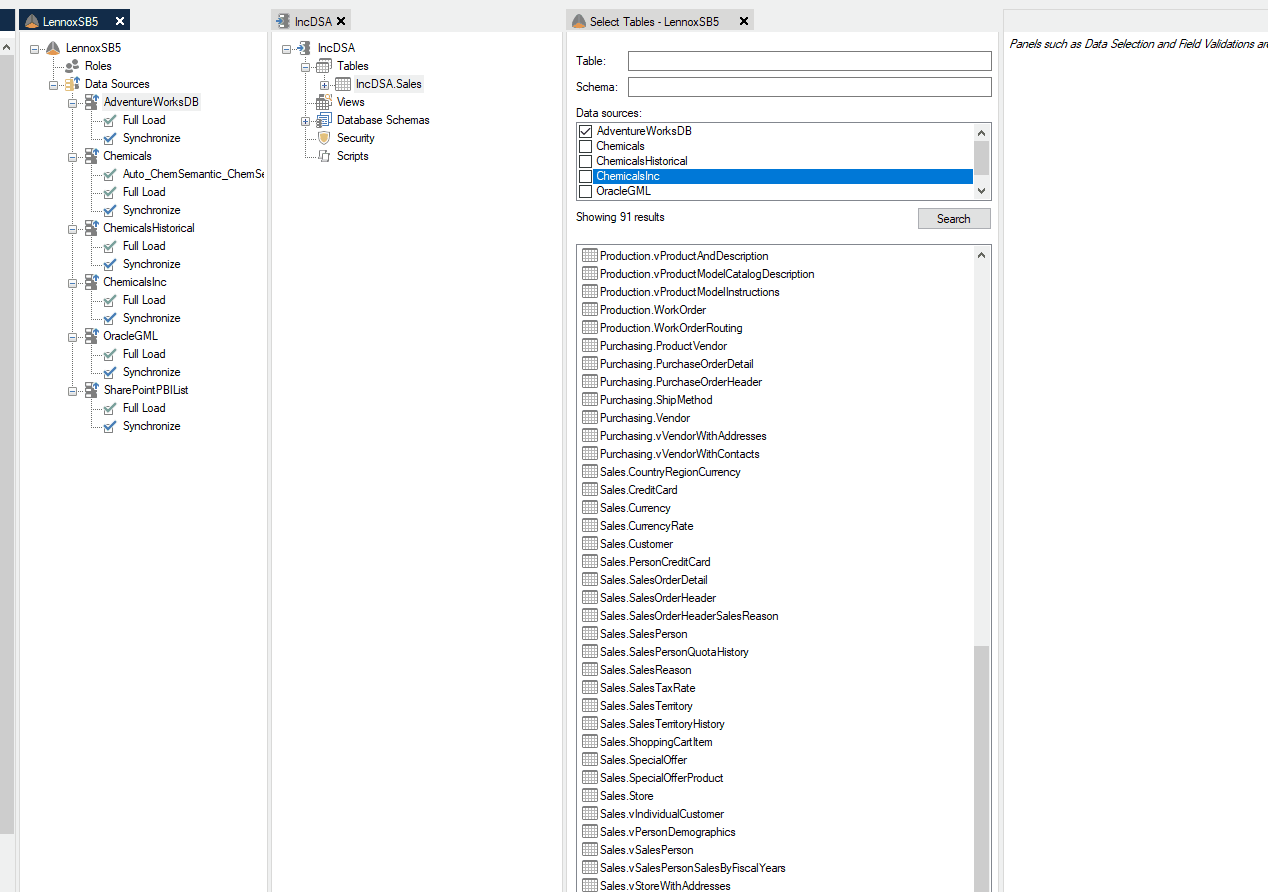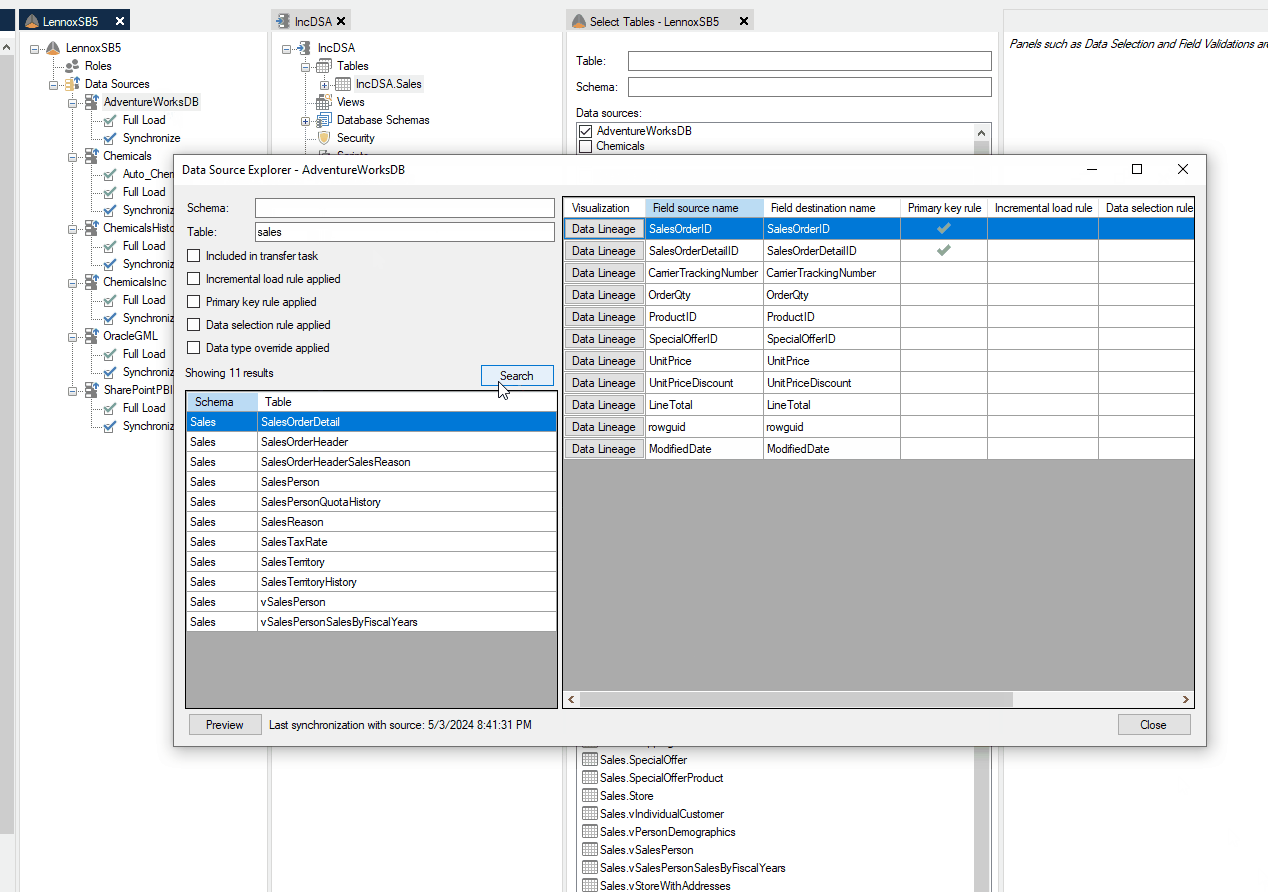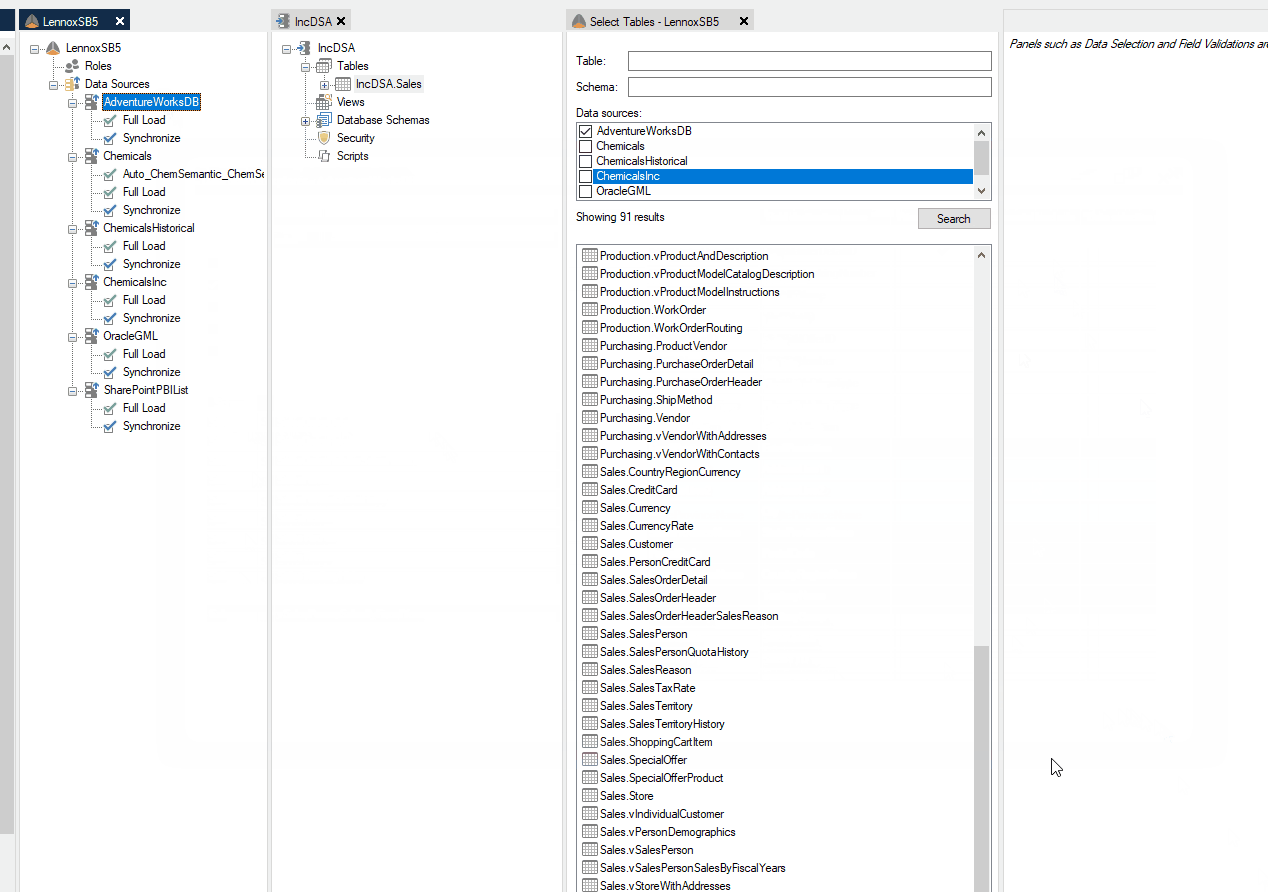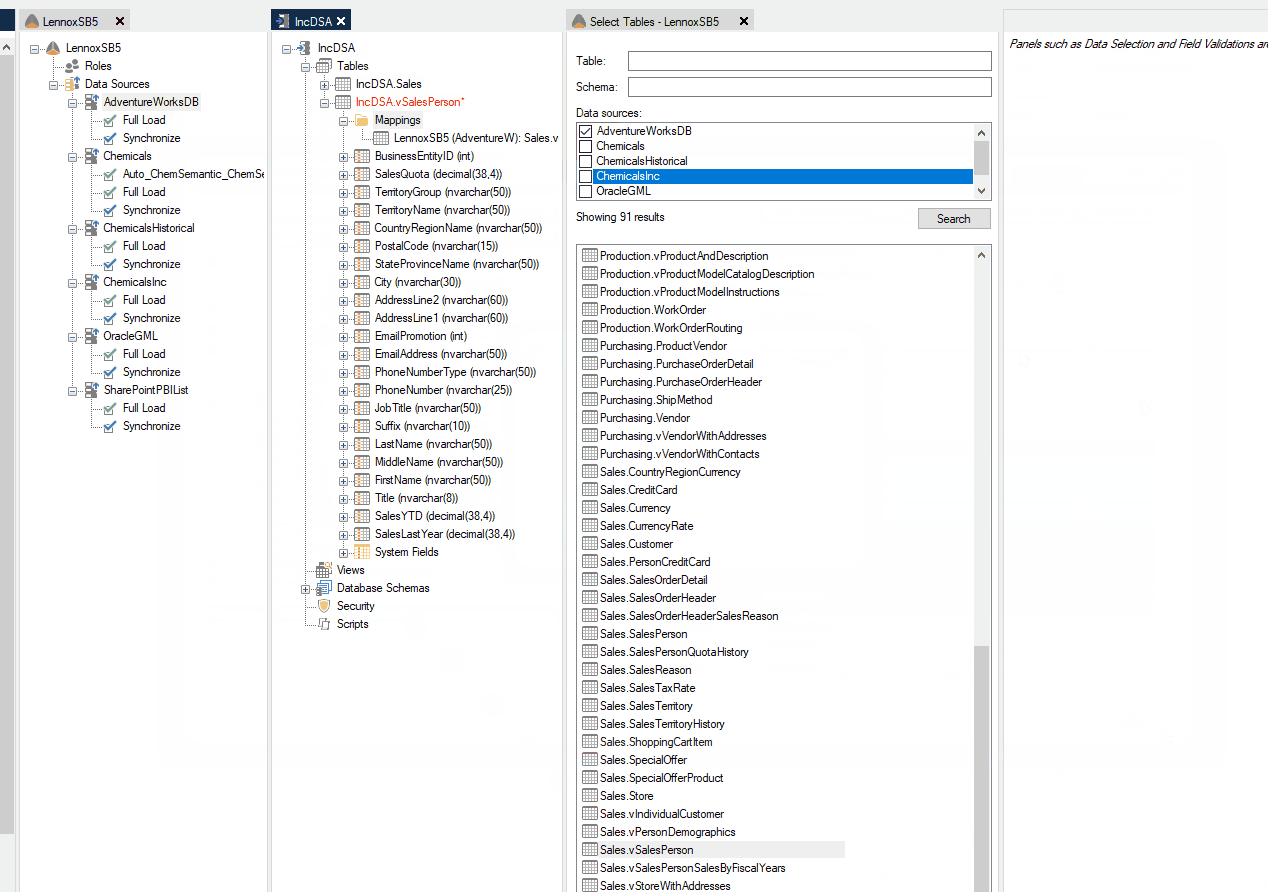
Mapping a table from an Ingest source to a Data Area table
When you map in a new table from a Ingest instance, the data extraction setting for the table will be set as automatic. If the table has an incremental load rule that is applied in the source, the table will load incrementally. This will be represented by an "I" icon for the mapping in the mappings folder under the table.
Below is an example of a table that is brought in from the Ingest to the Prepare instance, where the mapped table has an incremental load rule applied in the Ingest data source.
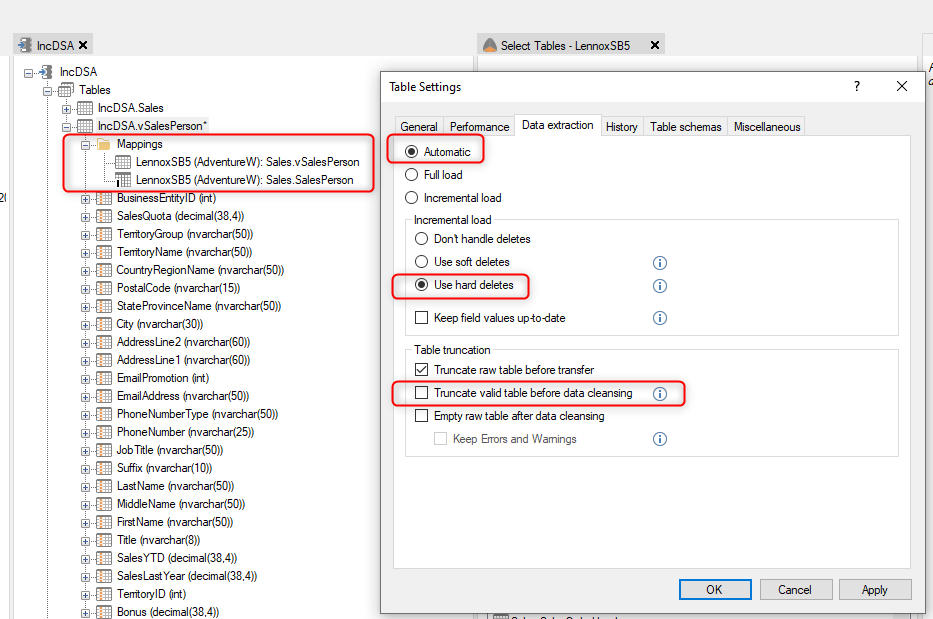
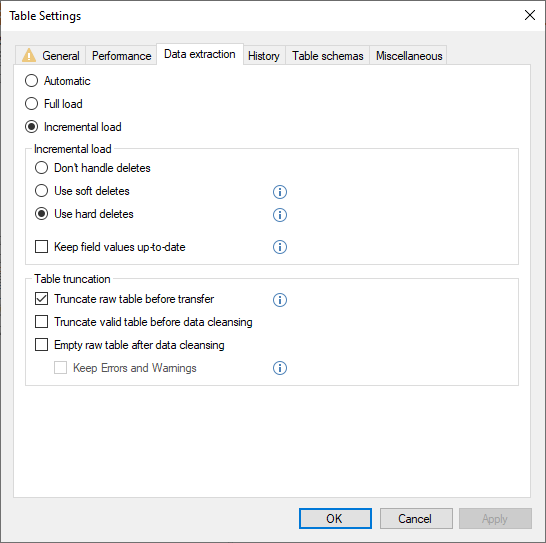
It is possible to enable soft or hard deletes by right clicking on the table and selecting Table Settings, and then selecting the Data Extraction tab. There is no need to change the data extraction from Automatic to Incremental Load, since the table is already using incremental load automatically based on the incremental mapping, however you can change it to incremental load if you wish.
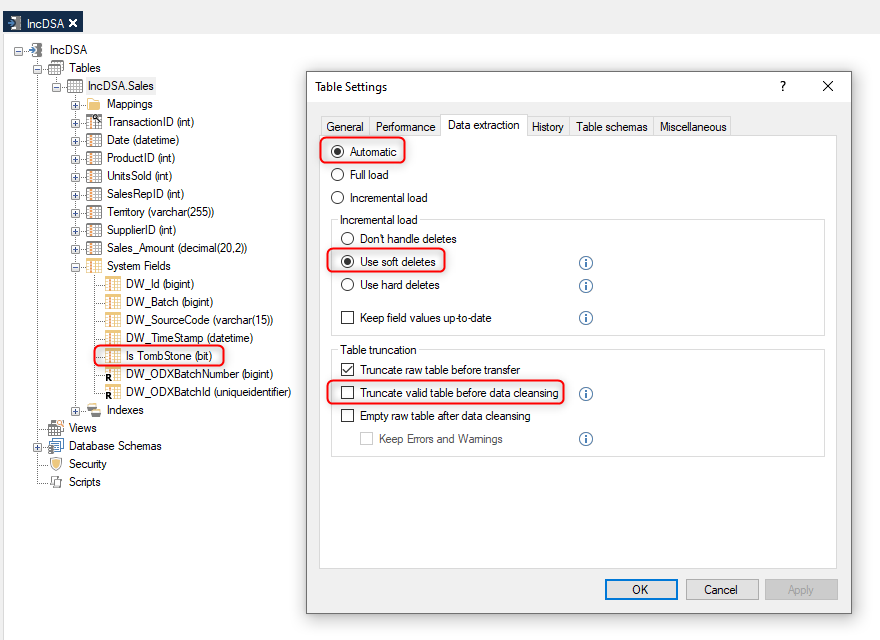
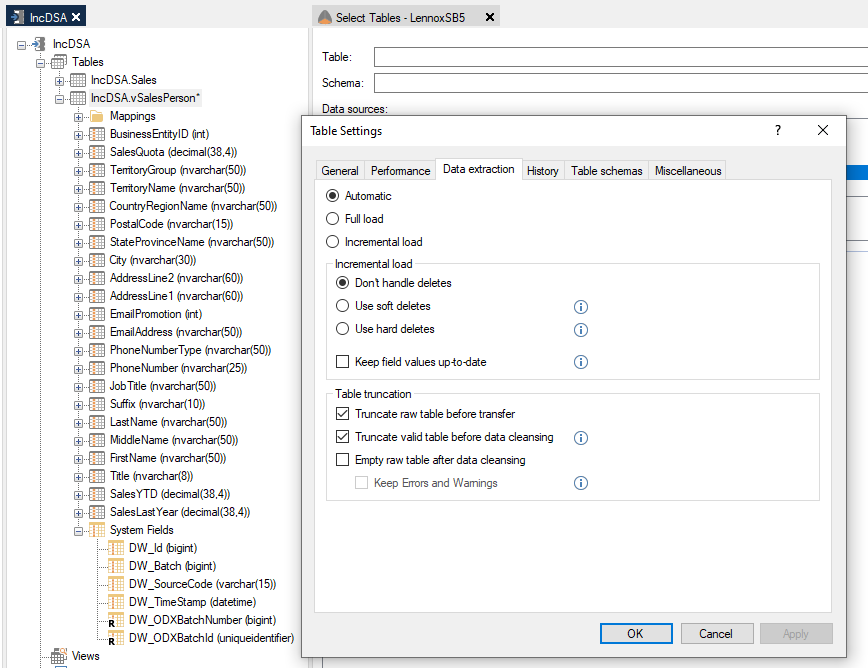
If there is no incremental load rule that is applied in the source, then the mapping for the table will not display an "I" icon, and a full load will occur when the table is executed. See an example of this below.
Data Extraction is still set to Automatic by default, and since there is no incremental rule applied in the source and the table mapping is not incremental, the table will automatically be fully loaded. Therefore, there is no requirement to change the data extraction from Automatic to Full Load, however you can change it to Full Load if you wish.
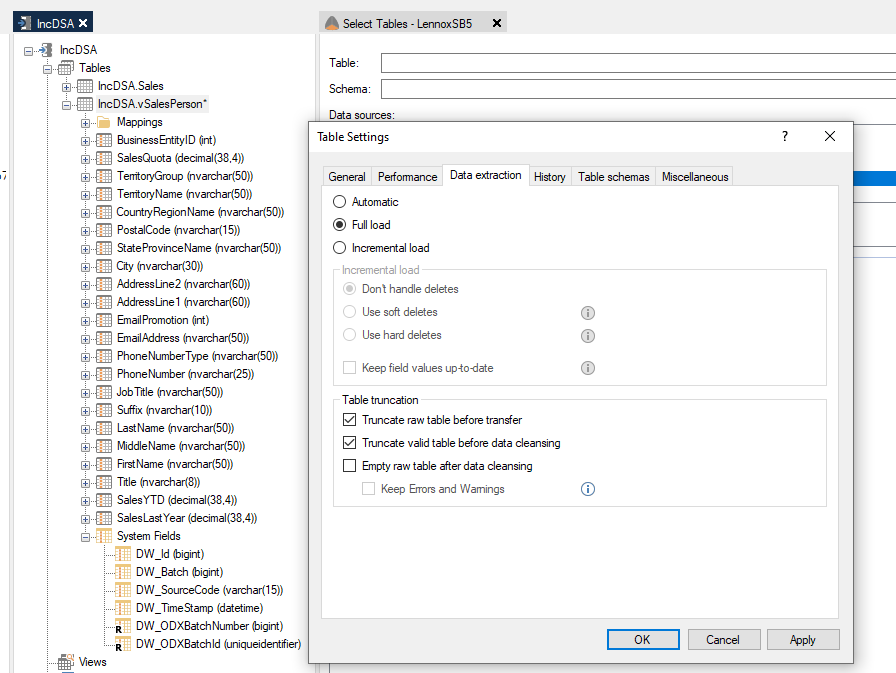
If you want to force a table that has an incremental load mapping to always be fully loaded instead, this can be done by changing the setting to Full Load. Note that this will gray out the options for delete, as they will no longer apply.
Mapping multiple tables to a Data Area table from multiple Ingest tables
Incremental rules will be set on each of the mapped tables individually, so it is possible to have one mapped table that is being loaded incrementally and another mapped table that is fully loaded. The automatic setting is appropriate in these instances.
Mapping tables from another Data Area
If you are mapping a table to a table from another Data Area, and the source table has an incremental rule setup in the Ingest Instance, we recommend that you use the Automate feature to base the incremental rule on the auto-suggested IncrementalTimeStamp field. This IncrementalTimeStamp field is mapped to the DW_Timestamp field of the source table. However, if you are mapping a table to a table from another Data Area, and the source table does not have an incremental rule setup in the Ingest Instance, we recommend that you use setup the incremental rule on a date field (e.g. a modified date field).
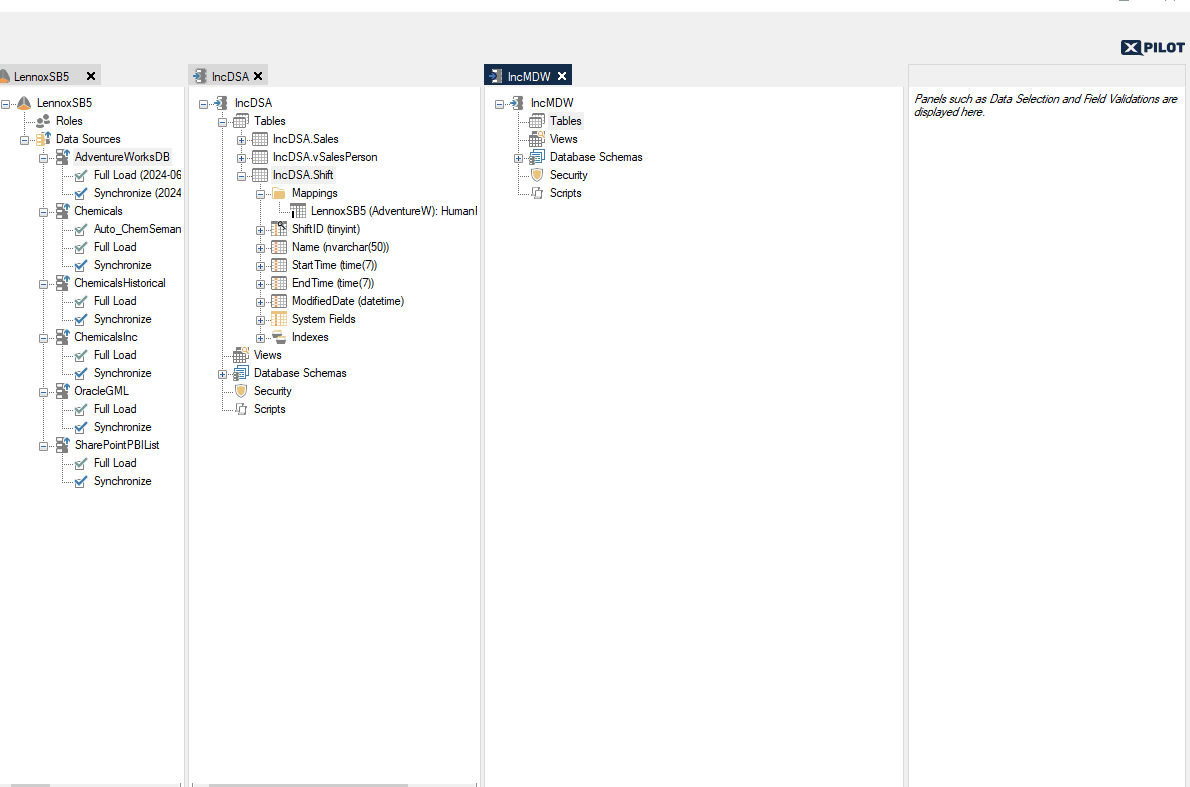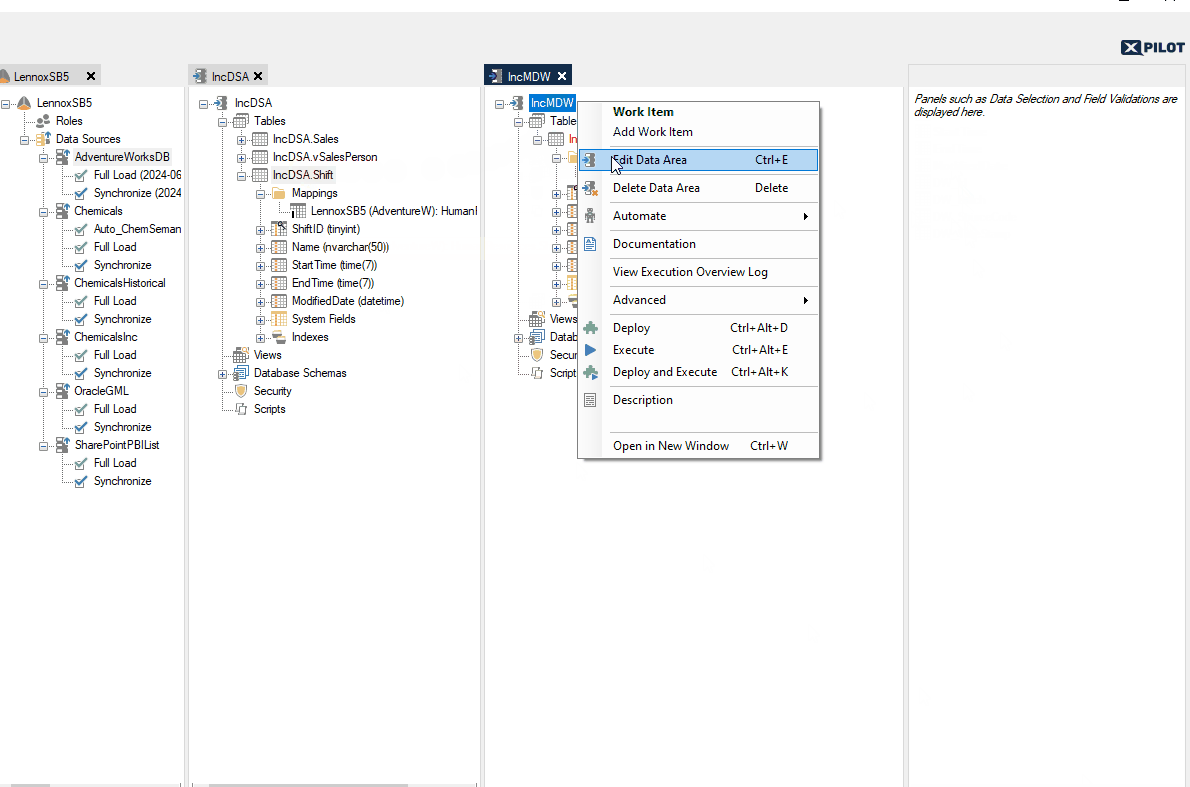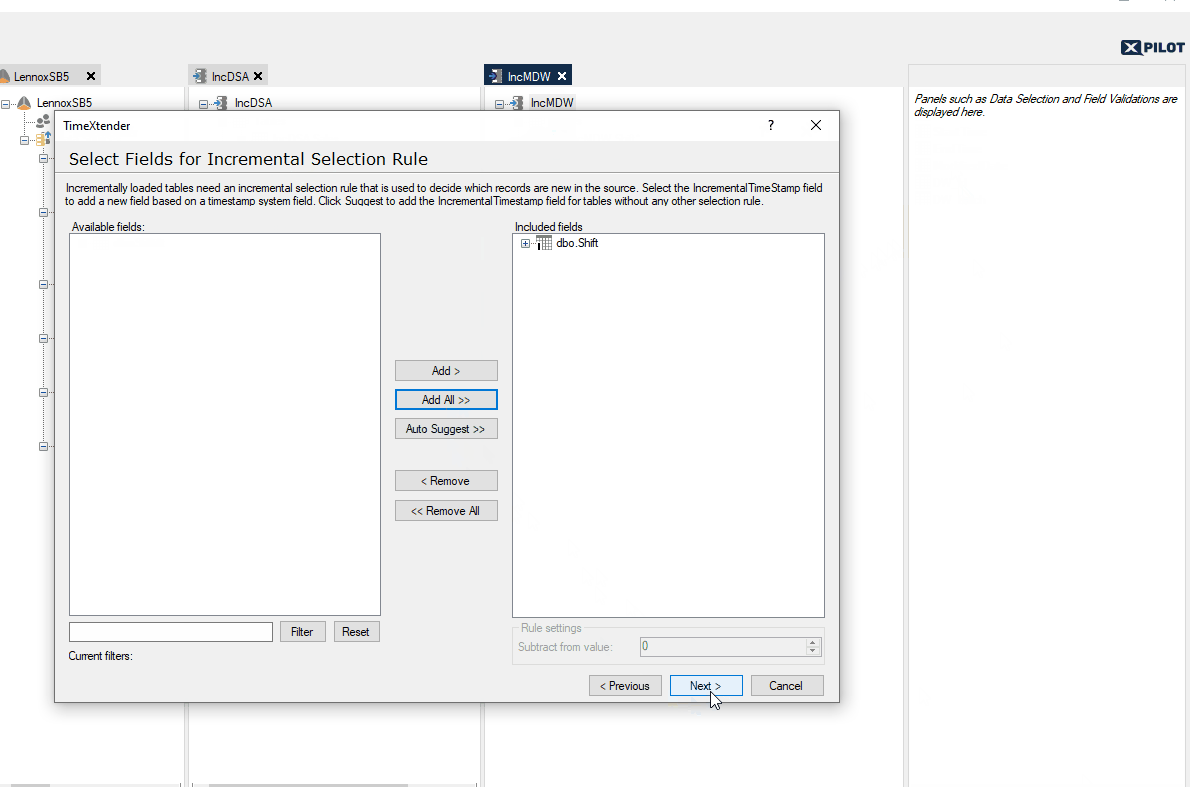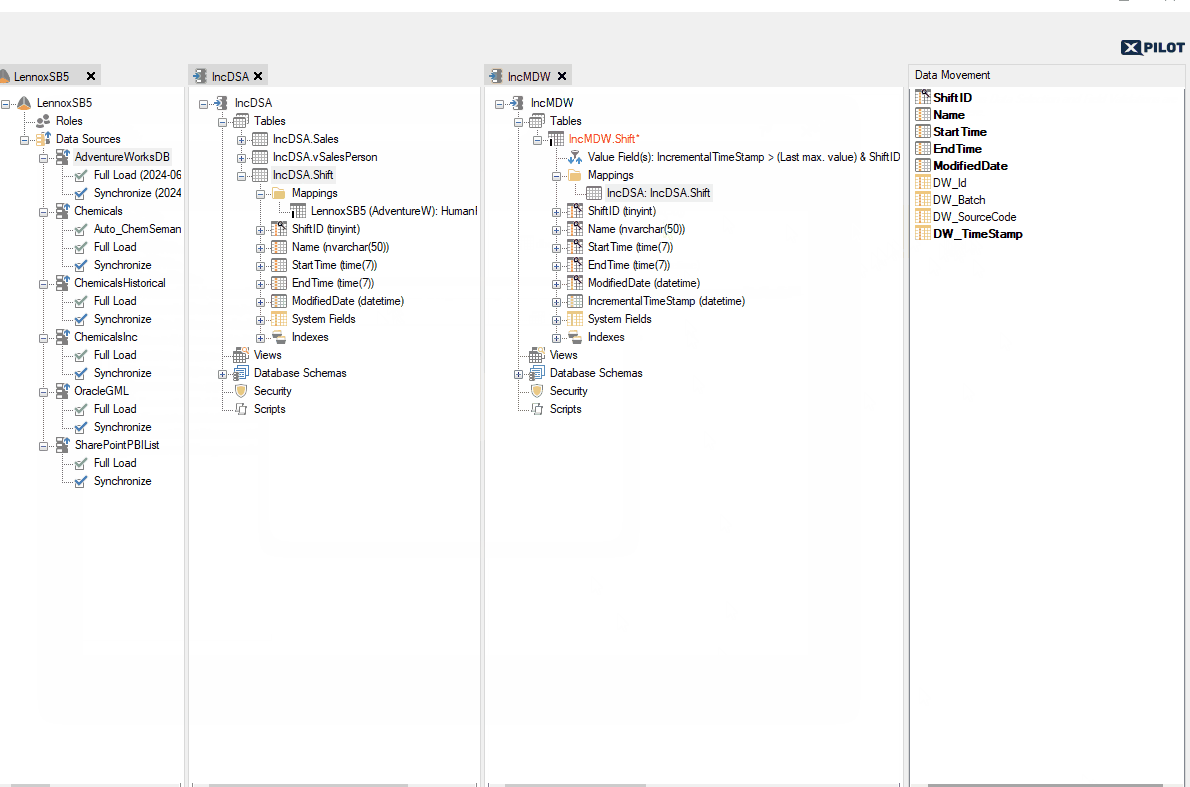
When the rule has been applied, the incremental load table will contain the incremental rule.
This will require that the data extraction settings are set to Incremental Load and not Automatic.
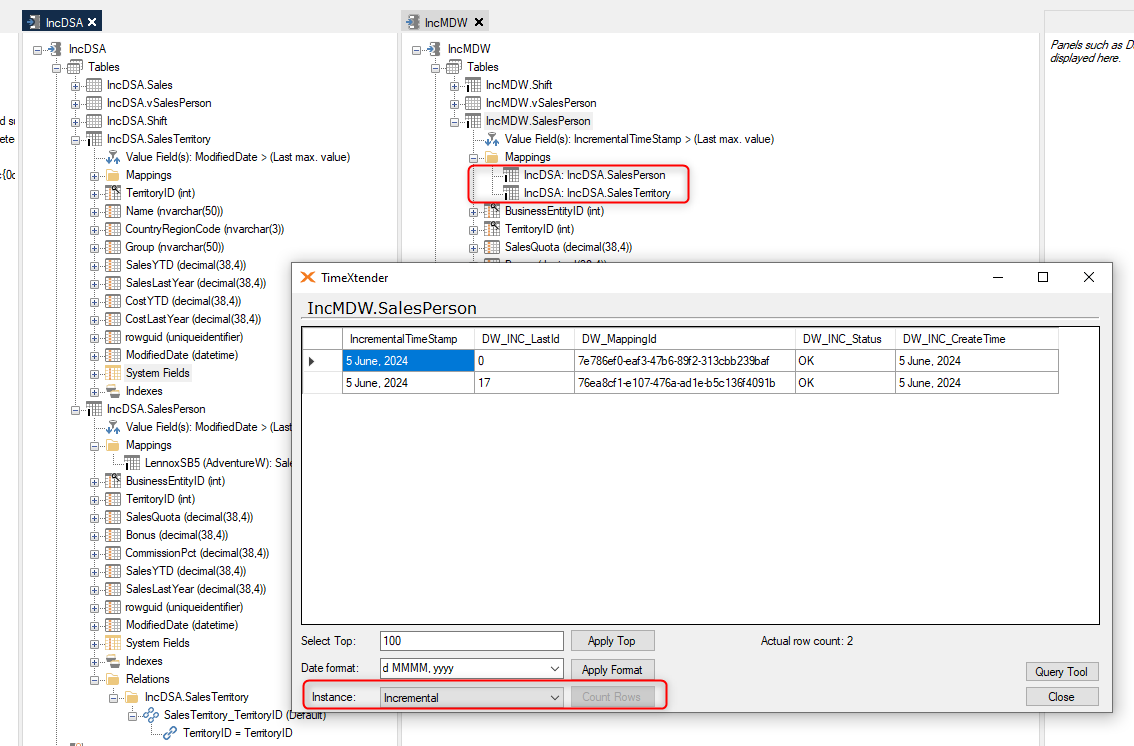
If you are mapping more than one table that is being incrementally loaded, it is possible to see that there is more than one incremental rule when reviewing the Incremental table as shown below.
If a table has a mapping from an Ingest instance, and another mapping from a table in another Prepare instance, it will not be possible to use incremental load. This is because one uses the DW_TimeStamp field and the other uses an ODX Batch number. You will have to split them out into two tables and then merge them at another point.
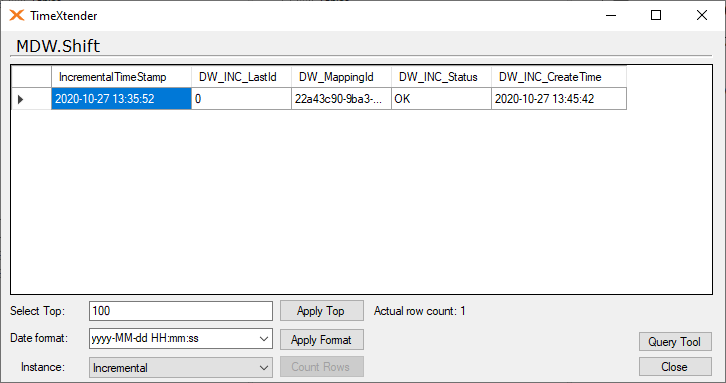
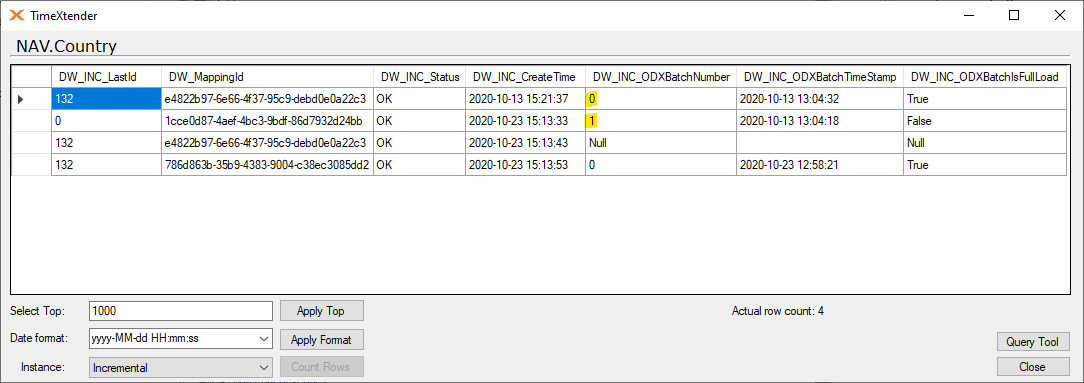
The incremental table
The _I table has seven fields.
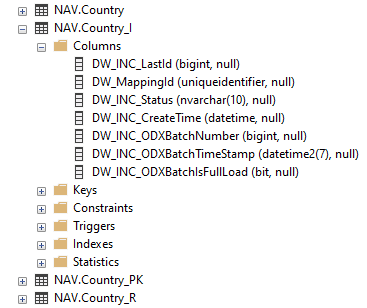
- Last id field
- This is the max DW_Id of the table before the latest execution.
- Mapping id field
- This is the GUID value of the mapping of the two tables. It is used to make sure it always uses the correct table.
- Status field
- If you open a table during execution and goes to the _I table, this will contain an Null value, but after an successful execution it will be set to OK.
- Create time field
- This is the value that is applied as the incremental value have been added for each table.
- ODX Batch Number field
- Is the reference field in the _R table that is used to know what the largest batch is.
- ODX Batch Timestamp field
- Is the date of creation of the latest full load folder or table depending on the store.
- Data Lake
- SQL
- ODX Batch Number Full Load field
- This will show whether an execution was a full load or not.
Here is how it looks when two tables are mapped.
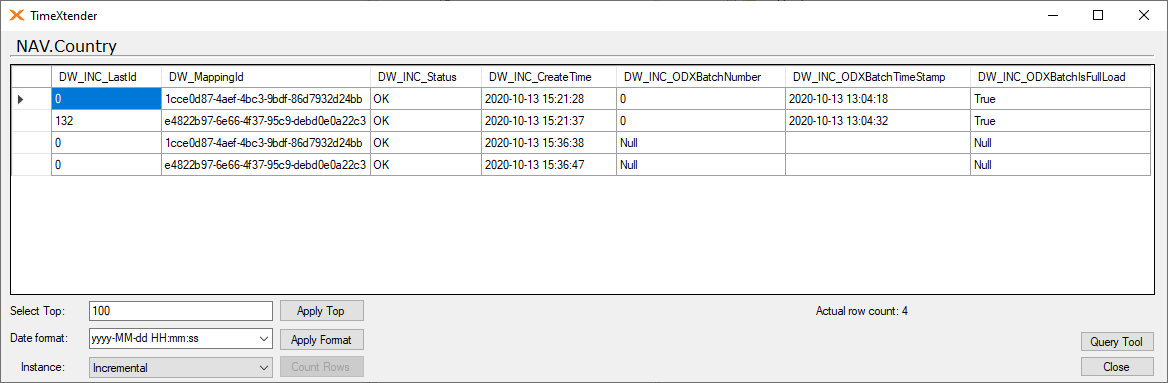
Also what you can see here is that the table have been executed at least twice, but haven't received new data from the source. That is why the ODX fields contain null values.
The raw table
There are two fields added to a raw data area table, when adding data from an Ingest instance to a Prepare instance.
- ODX Batch Number field
- The reference batch number from the incremental table
- ODX Batch Id field
- The id of the batches. Necessary as you can map more than one table that each have a batch 0 and you would not be able to see the difference otherwise.
Here is how it looks when there is new data in the raw table.
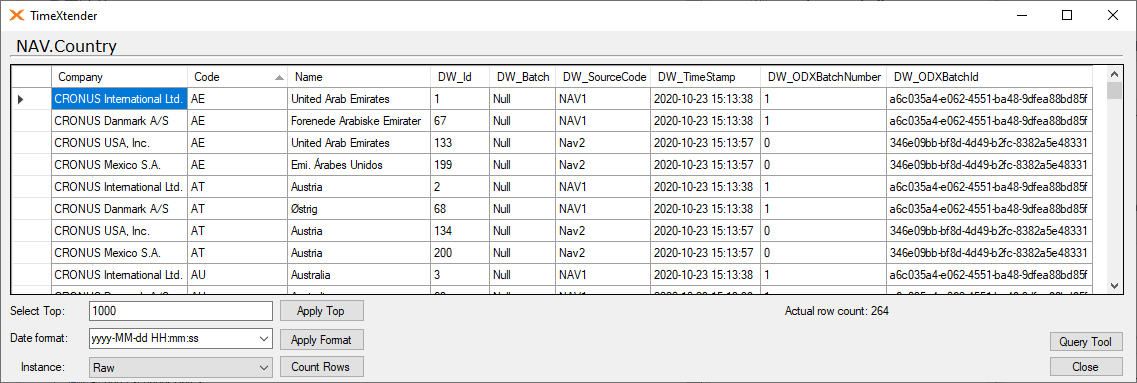
If you relate that to the incremental table, the batch number have in the same numbers.
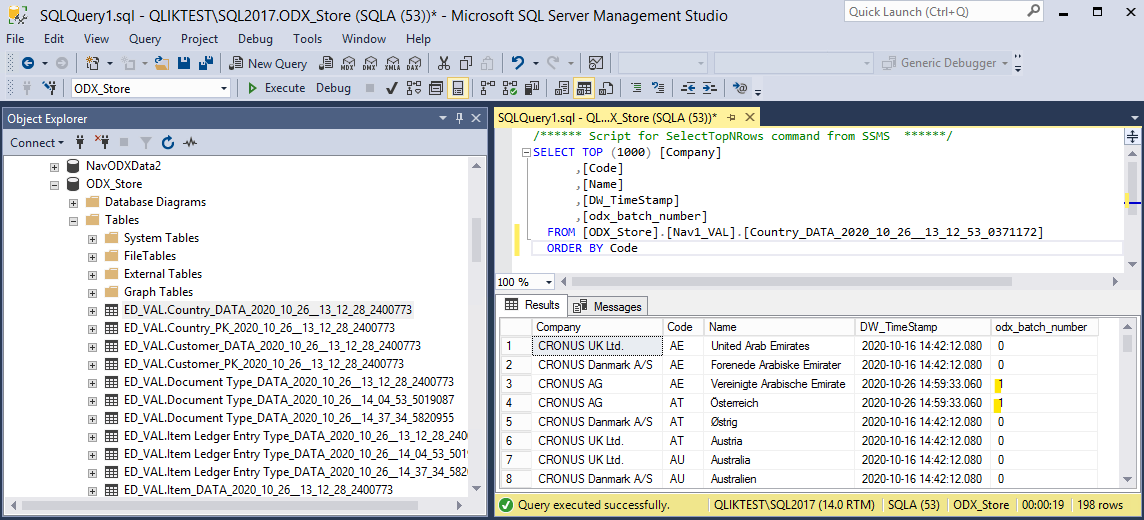
Here is what the reference in the data lake is. Each file has an higher number, which is the Batch number in the other tables.

Here is what the reference is in an SQL store. It is a field containing the batch number.
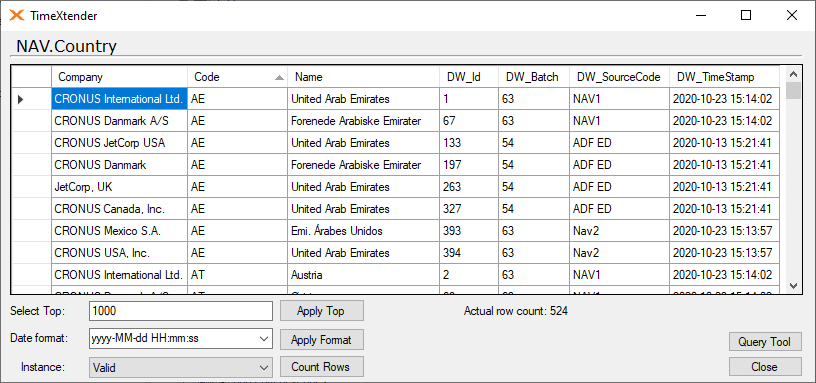
Changes to the valid table
The only change is that since we are not using a specific field in the source to generate an Incremental field, we don't have that.
Deletes
As in the other parts it is also possible to set up deletes on the Data Area tables.
It works by comparing the new rows with the primary key and then deleting the row or changing the Is Tombstone field value from False to True.
You can see how this is done in the code by looking at the data cleansing procedure.
Here it is for the Country table using Hard deletes.
-- Incremental load: primary key hard deletes
IF EXISTS
(
SELECT TOP 1 1
FROM [NAV].[Country_I]
)
BEGIN
DELETE V
FROM [NAV].[Country] V
WHERE
NOT EXISTS
(
SELECT TOP 1 1
FROM [NAV].[Country_PK] P
WHERE
P.[Company] = V.[Company]
AND P.[Code] = V.[Code]
)
AND NOT EXISTS
(
SELECT TOP 1 1
FROM [NAV].[Country_R] R
WHERE
R.[Company] = V.[Company]
AND R.[Code] = V.[Code]
)
ENDAdditionally you can also see how the Updates and Soft Deletes will be applied in there.
