Hi,
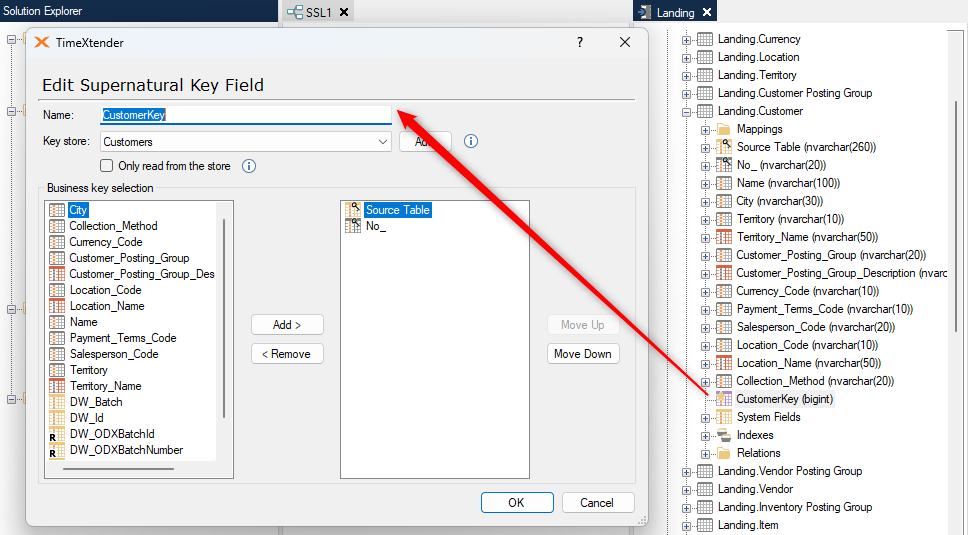
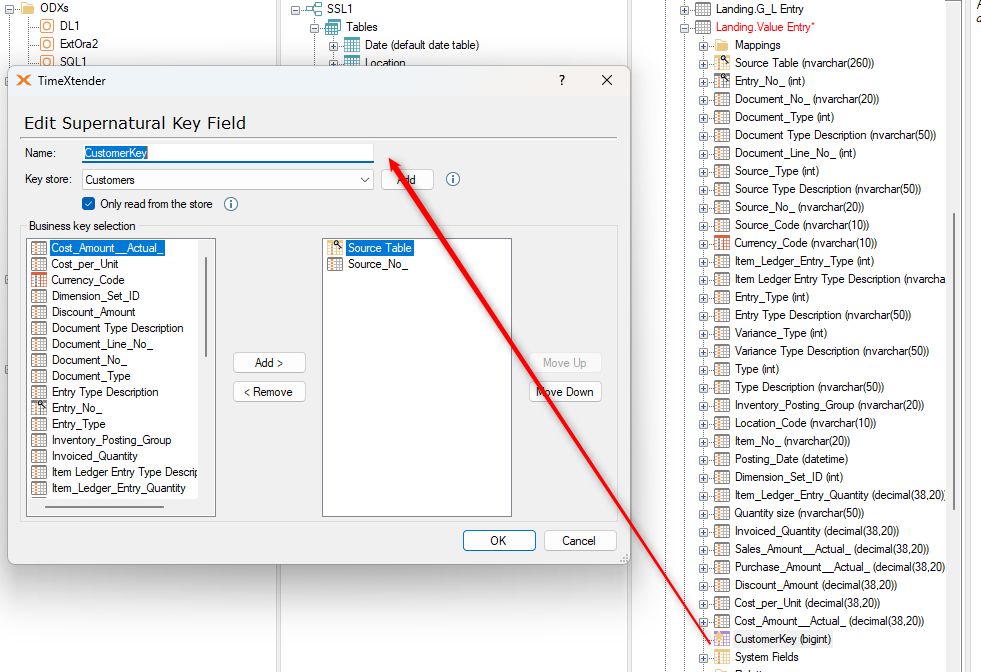
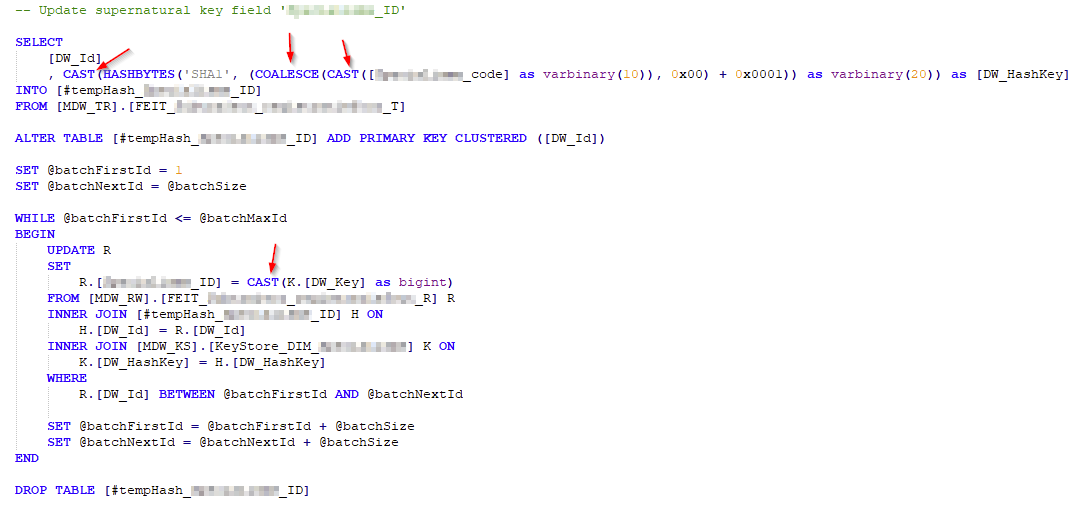
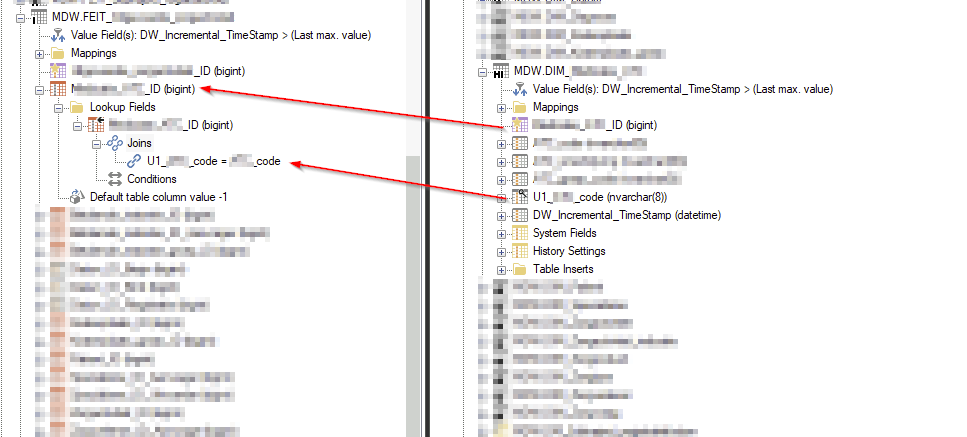
I have seen clients use Supernatural key fields to create keys between the fact and dimension tables, usually when the logical key is a combination of fields. I have seen these two methods used:
- The Supernatural field key is created in both the fact and dim table, using the same key store
- The Supernatural key is created in the dim table, then mapped to the fact table with a conditional lookup
Is there a difference in performance here? Is there a best practice to advocate for?