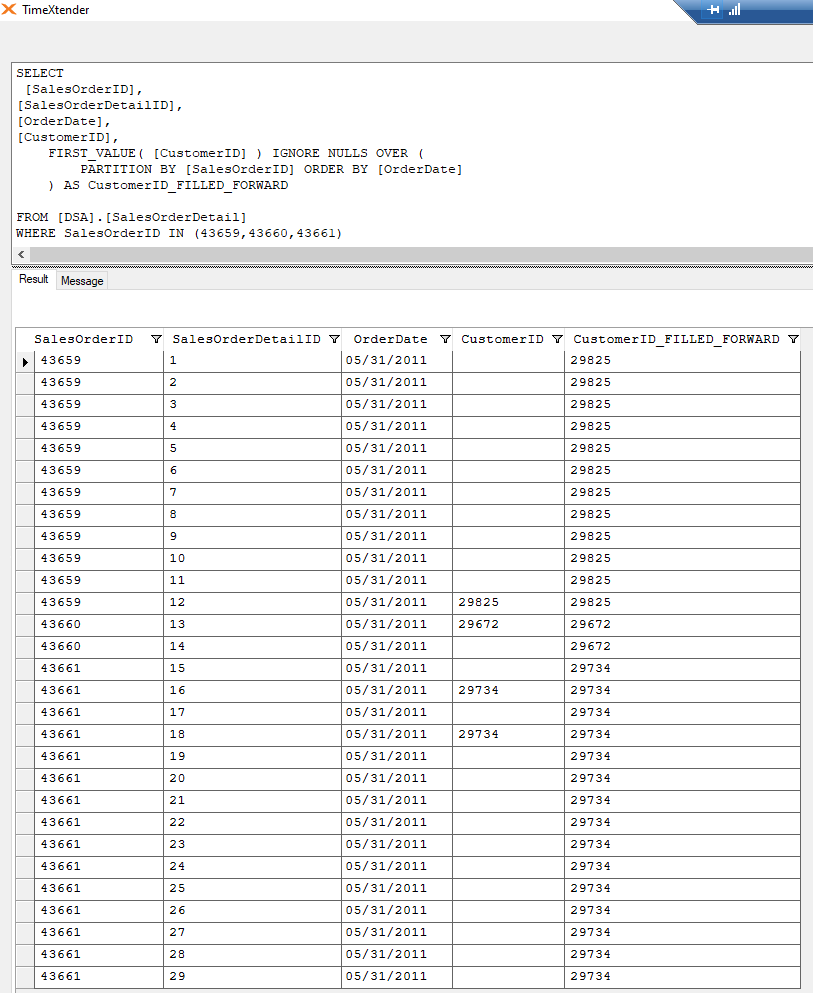
I would like to be able to flash fill down NULL values in my DSA table with certain conditions.
In the table below I have multiple NULL values. Take for example the column ‘CardCode DUAL’.
Row 2 with Company key MTW and project 1201121979 shows for CardCode DUAL DB0006. I would like to show value DB0006 also for all other rows where company key = MTW and project = 1201121969.
Same for Route Bron column. I would like to fill down NULL values on the most recent NON Blank value for that Company_Key+Project combination.
I think it should be possible with a self join or self select, but not sure how.