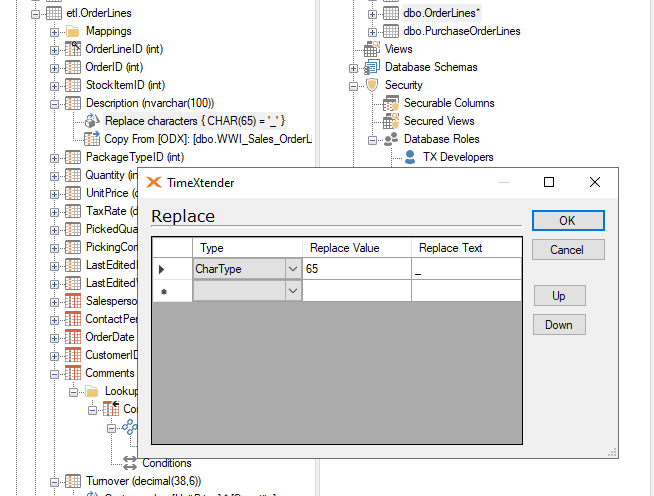
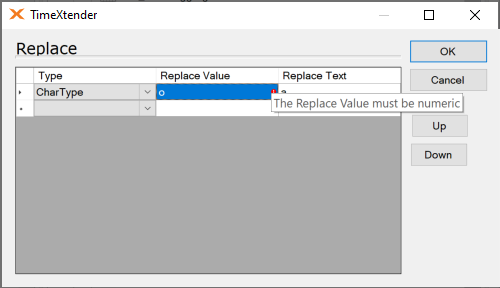
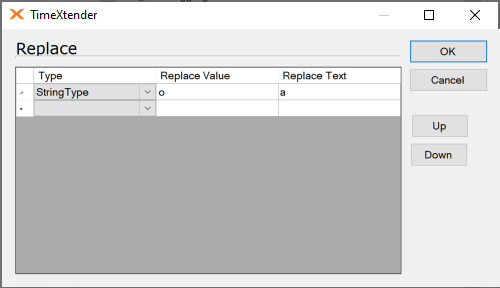
I discovered that when using the replace transformation with the CharType that you are required to know or look up the int value of the character you want to replace and use that as the parameter.
This does not seem to be documented anywhere or be useful in any way I can think of. I assume REPLACE('abc’, char(65), 'b’) is functionally equivalent to REPLACE('abc’, 'a’, 'b’). In a Case Insensitive collation there is no difference between the two anyhow.
There is also no COLLATION or binary type support, which are things that you can do with REPLACE() that might actually be useful in certain rare cases.