Hi!
I beg your pardon for this somewhat lengthy post, but I try to be thorough to avoid confusion. :)
I have a problem with updating an SCD.
We are moving an old adress history table from another system into a SCD in TX. It has gone well so far since the old system made one insert per person per day regardless of whether there was an update or not, which has made us go from about 108M rows to about 275k rows with actual changes. So far so good. :)
The problem now is that have a hard time to get this moved table to update correctly from a new source. The setup looks like this at the moment:
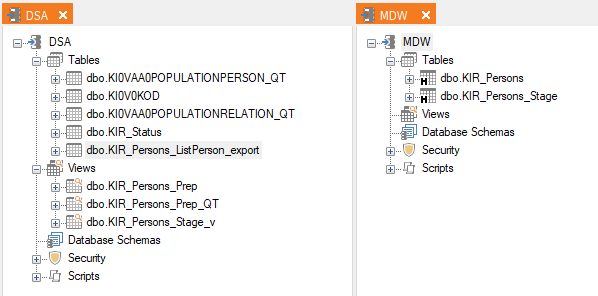
The MDW table KIR_Persons is the correct and prepared historical data from the old system where I have fixed the From- and To-dates along with the “Is Current” flag. The “break date” for the data from the old system is 2023-10-16 which is when I made the final export.
The new source for the address data is the DSA table KI0VAA0POPULATIONPERSON_QT which is the result of a query table. I’m using the DSA view Kir_Persons_Stage_v as a source and for data preparation for the target MDW table KIR_Persons_stage for testing this out. The settings for the SCD looks like this:
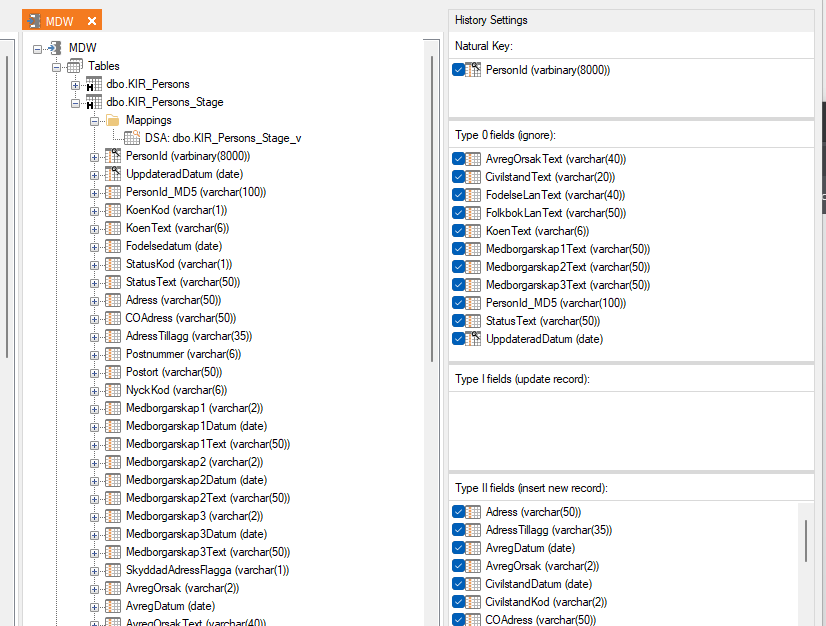
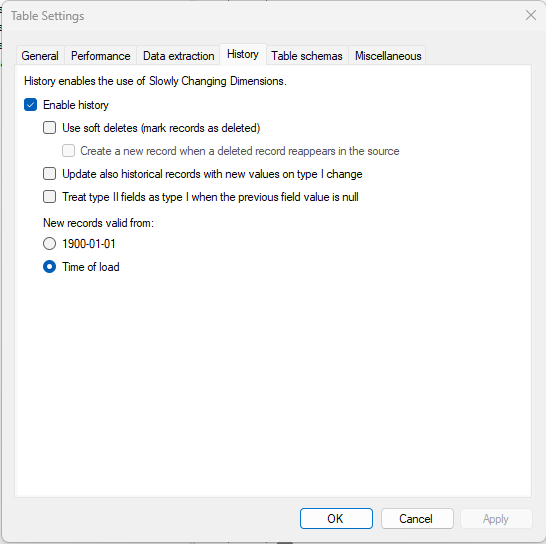
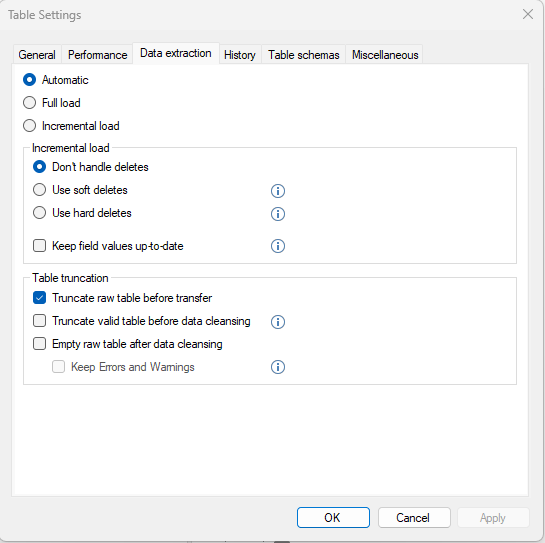
The TipTool says that the “Truncate valid table..” is ignored if using this.
In the attached file Initial_SCD_Data (had to do it like that because I don’t know how you do this fancy “click on the picture to zoom in” thing :)) you see the important columns, along with the metadata, that the stage table was filled with before the new load.
This data was copied from the prepared KIR_Persons table (that’s why the screenshot is from that table but it’s the same query that I used filling the stage table) and in the attachment you can also see the comments about different cases that I wanted to investigate.
Then I executed the load to the stage table, with the same id:s that I had preloaded, with the keys and dates like this (obviously not all columns are present in this screenshot, but the PersonID and the UpdateDate are the most important ones here):
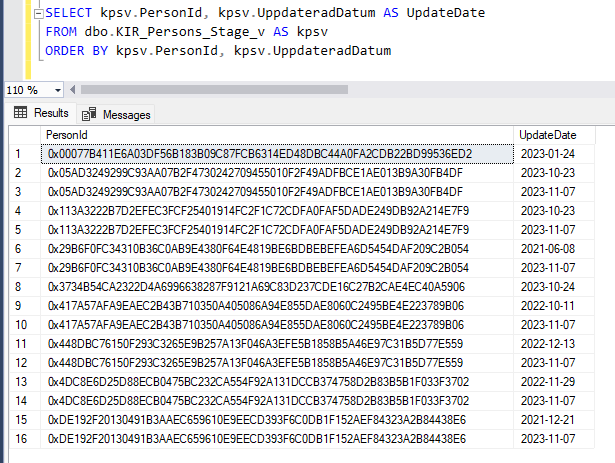
Some had an UpdateDate before 2023-10-16 and some after - and as you can see some had two update dates after 2023-10-16. Now, the UpdateDate is not in the Type2 so that should not matter for what gets updated or not. It’s just shown to illustrate what changes that should occur.
What I would presume is that rows with a date before 2023-10-16 would typically not result in an update while rows with a date after 2023-10-16 should be a new active row. If there are more than one row with updates for an ID you would get a very short timespan between the From- and To-dates but it would still show.
So, I had 15 rows in the KIR_Persons_stage table - loaded 16 rows with the expectation that some of the old rows would just be ignored, and some would end up as new active rows on the same key with correct From- and To-dates. This was not the case as can be seen in the attachment SCD_data_after_insert.
I ended up with 31 rows in the table and it seems like in most cases the SCD functionality just ignored the hash of the Type2 columns and just inserted a new row anyway. I can say that the ID starting with 0x00077B… got updated even though it had the same adress data but that was because of other changes in the columns.
For the ID starting with 0x05AD.. that had two updates after the break date both the new rows got inserted as active rows while the first insert did actually set the already existing row as not active, so half way there.
Is there something I’m missing here in the setup of the SCD?
When does the comparison of the existing checksum in the valid table and the checksum of the incoming data actually take place?
I noticed that the latest imported data is still in the RAW-table but that get truncated at each load, right? Or do I have to “preload” the raw-table with current data the first time for the check to go right?
And one other thing that I came to think of while writing this - how do the SCD treat NULLs compared to empty string?
I hope all this makes sense. :)