Hi Joost,
The default behavior of Discovery Hub in data cleansing is complicated, but is roughly as follows:
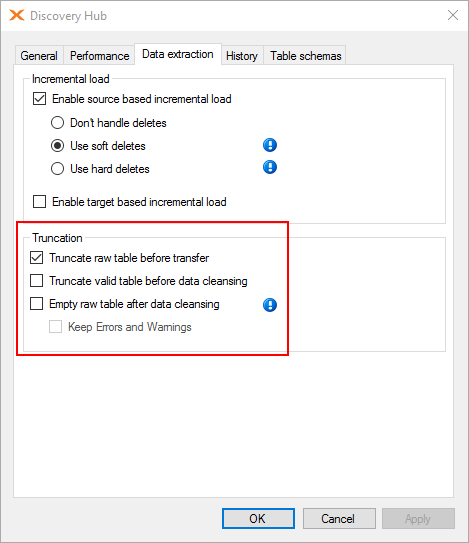
- Truncate raw table
- Copy new records to the raw table
- Update the raw table with lookup values
- Detect validation problems
- Truncate the valid table
- Copy valid rows through the transformation view into the valid table
In the end, the valid table is a subset of the rows in the raw table, given default table behavior. This does mean that the table has a larger footprint on the hard drive, but it also allows you to understand exactly why the records in the valid table are there, and why they look like they do. You can empty the raw table after data cleansing, but then you will be hard pressed to explain any discrepancies between your data and the source.
If you check "Keep Errors and Warnings," all rows in the raw table that trigger a validation rule will be retained, so you can see what the problem was. This can be helpful, but if you don't understand why a transformation or lookup field doesn't contain the value you expect, you will be out of luck. I can't really understate how useful the raw copy of the data is for troubleshooting purposes!
The "Truncate raw table before transfer" option should almost always be on, otherwise you will load data both for the last load and for the current load into the valid table at once. There are some edge cases that involve switching this option off, but they are very rare.
Incremental tables and history tables alter this behavior somewhat. Both require that the "Truncate valid table before data cleansing" option is turned off. This is because history tables need to be able to retain records that are no longer present in the source, and incremental tables work by only bringing in new or update records from the source.
Incremental tables will only contain a full set of raw records during their first execution, or if a full load is triggered. This makes them load much more quickly, but can make troubleshooting older records more difficult, and works best with transactional tables that don't need to be heavily denormalized.
Simple mode tables follow different rules - they only have a valid table by default. A normal simple mode table does not respond to either of the raw table truncation options because it does not have a raw table. It doesn't allow you to turn on the truncate valid table before data cleansing script because it has no data cleansing script. To be fair, graying these options out for a normal simple mode table might be something we should look at as a UX improvement.
If a simple mode table is set to incremental, a raw table will be added. This is because the incremental load needs to be able to update existing records and insert new ones, and so records can't just be inserted directly into the valid table.
I hope this overview helps somewhat - if you have any follow-up questions, please let us know! For this kind of thing, a meeting can be helpful to step through these processes and see them functioning in a live environment. If that's something you'd like, I'm sure we can work with your partner to set something up!