Hi,
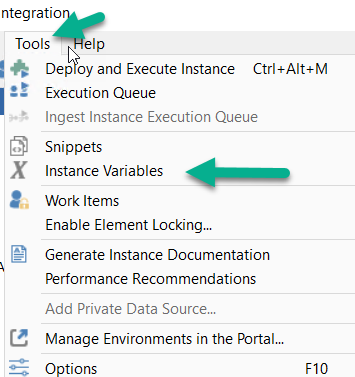
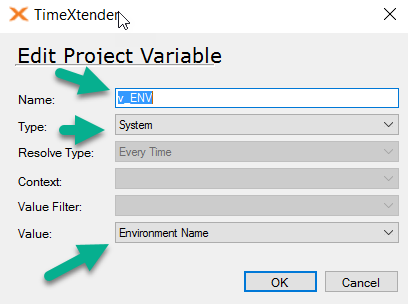
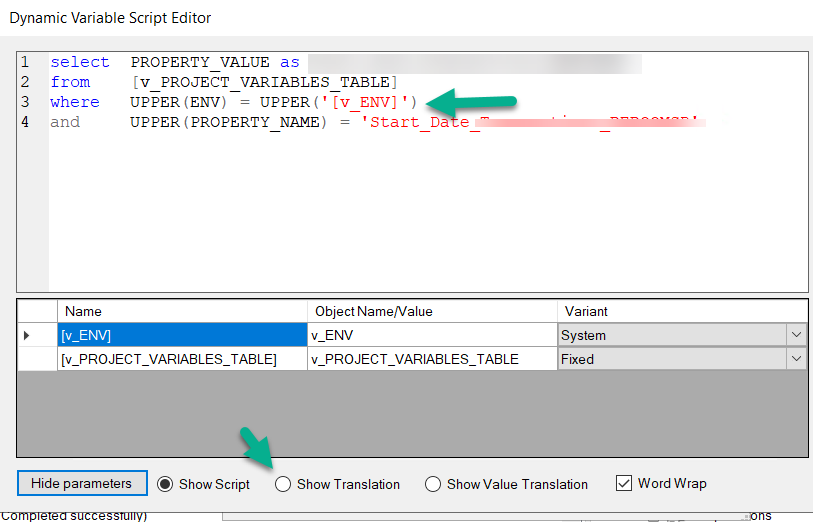
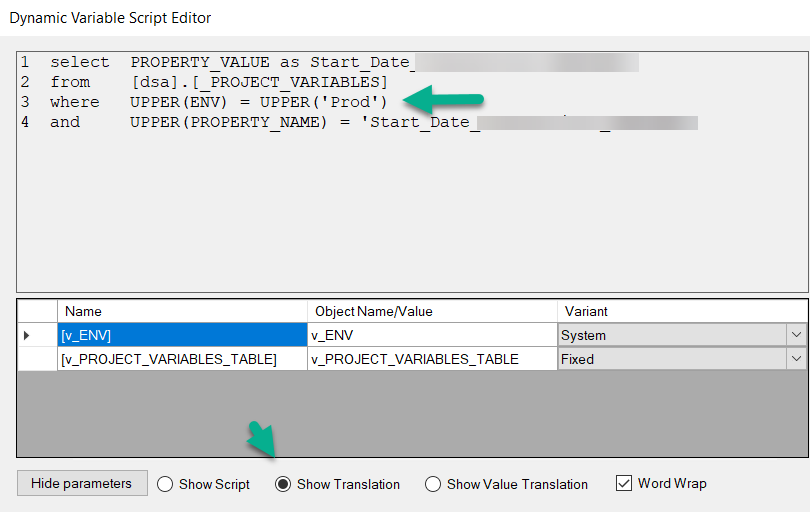
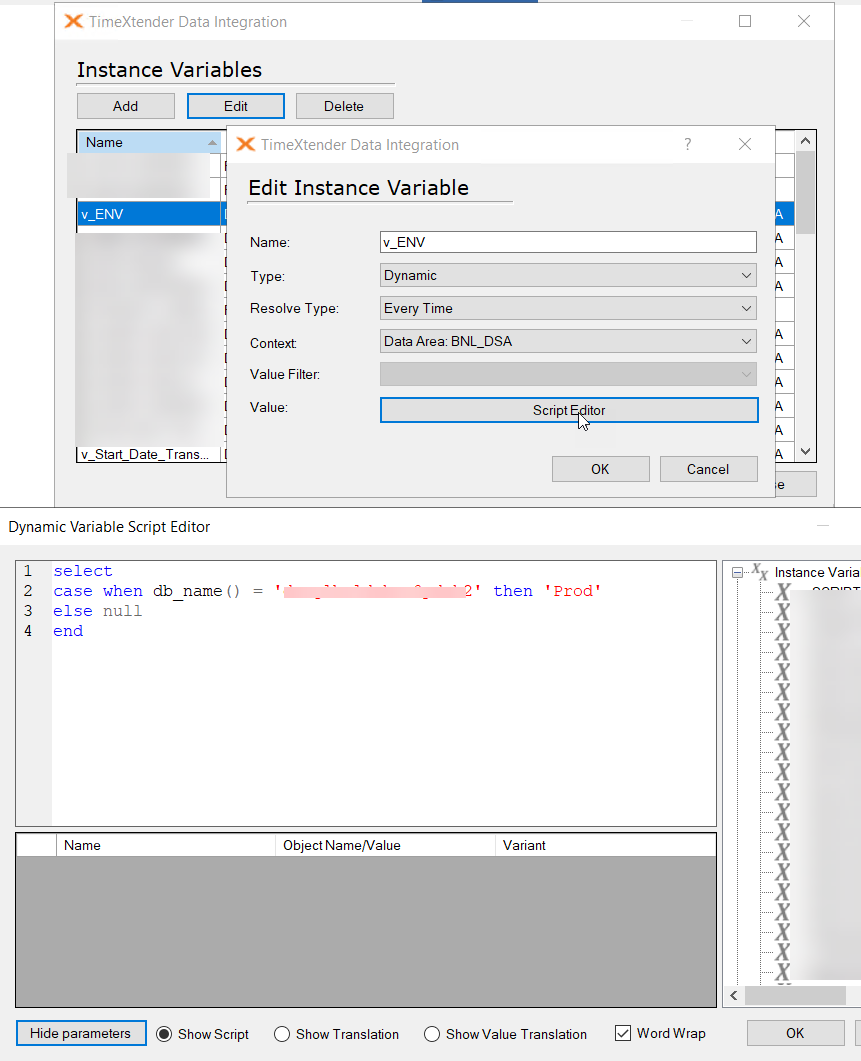
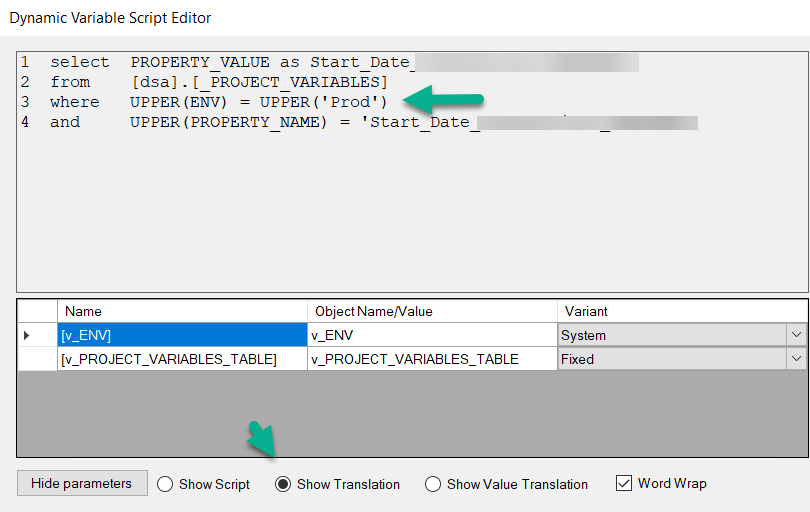
We are migratring i customer from version 20 to 21. In version 20 they use a system variable to limit the amount of data loaded into certain DSA tables in the development environment.
is there any way to accomplish this in V21 - setting a variable that only affects one instance?
BR
Anders