I'm trying to get data from a REST api. The challenge is that the response is nested (JSON format).
I did split up the seperate fields by editing the RSD file, adding something after the xPath...

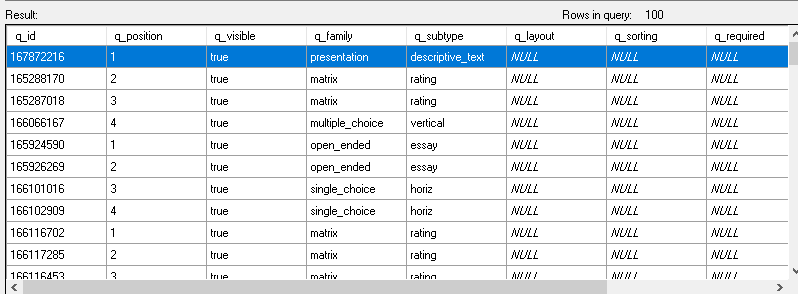
The result looks better than before but still all my answers are comma seperated in 1 field/row combination instead of 1 field 4 rows for example. It looks like this now:
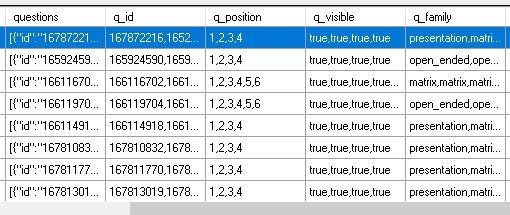
How can I make sure I only get 1 anwser per value per row? (So line 1, field q_position should be seperated to 4 rows with value 1,2,3 and 4)