


The core aspect of the exception manager is that each exception has a unique primary key. This unique key can be a single column or a composite key made from multiple columns; this unique key can only occur once in the results of a test.
Primary keys must be unique to work correctly in the exception manager. Normally, if an exception occurs the exception owner will have to change value columns in the underlying data source, to fix the exception.
The next time the test will be executed one of these will happen:
- If the test’s primary key did not contain changed columns
- The exception closes or stays open, depending on if the user fixed the underlying data source.
- If the test’s primary key contained changed columns
- The exception closes. A new exception is created if the user did not fix the underlying data source.
With the exception manager enabled, the default test primary key is a combination of all the test columns, except for the amount column. This works as a good starting point, but it has two issues:
- The danger of creating new exceptions as explained above
- When a column is added to test
- All open exceptions are closed and recreated
- Exceptions marked as “Not an exception” will be closed and reopened
The primary key tab in exception manager properties helps users set a unique primary key. For the custom section to work accurately, make sure you have already run your test.
The resulting data will be used to determine if the combination of columns is unique.
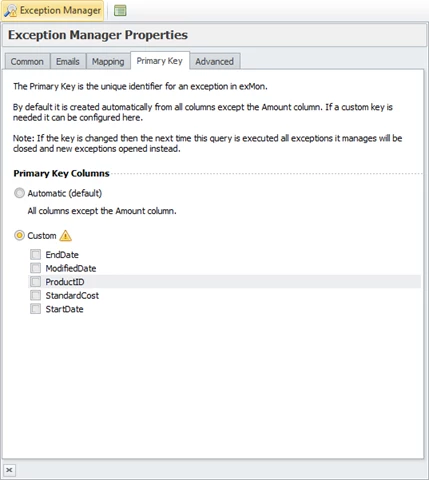
Note: Even though a combination of columns is unique for the current dataset it is not certain it will be unique for future data.
Worked Example:
Let's look at a test and see how its columns can be combined into a primary key, which columns work together, which cause a primary key error and how those errors affect the test.
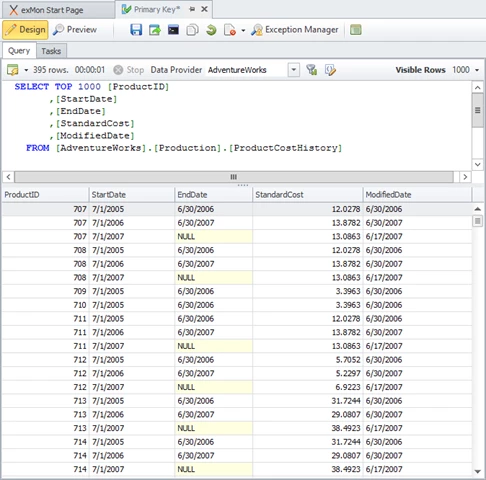
Here we see a query that returns 5 columns, ProductID, StartDate, EndDate, StandardCost and ModifiedDate.
Default behaviour
Looking at the columns, it is certain we would want StandardCost to be the AmountColumn. This means that the rest of the columns would be the primary keys. While this causes a unique primary key, it will recreate exceptions if we need to update EndDate or ModifiedDate. This behaviour also makes it harder to later add columns to the query.
The primary key correctly selected
When selecting the ProductID column along with either StartDate or EndDate columns, each exception becomes unique. This is likely the unique key we’re looking for which allows us to focus on the value of the other columns.
The primary key column selected with one or more value columns
When we have a primary key column and a value column selected, it results in odd behaviour. If we look at our query, if we were to select ProductID and StandardCost as our primary keys, the test would only work as long as StandardCost was unique for each ProductID. This test might run for months or even years without a failure, but eventually, it’s likely it’d fail by returning duplications.
Partial primary key selected
This primary key failure is probably the easiest to distinguish as the test will likely never successfully execute until other columns are added to the primary key. An example of this is if we’d select only ProductID as a primary key. In our case, we’d have multiple duplications of each ProductID which would result in the test failing to execute.
One or more value columns selected
When only value columns are selected, exceptions are chaotically linked together.
