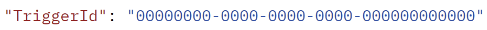Warning: This article refers to Jobs and the TimeXtender Jobs API which have been deprecated. Please schedule TDI execution packages via TimeXtender Orchestration rather than using jobs
This article describes the various endpoints within the TimeXtender API and how to send requests using the TimeXtender Postman collection. To use the collection, download and install Postman, download the collection, open Postman and import the collection into Postman.
Prerequisites
The API Key needs to be setup in order to use the TimeXtender API endpoints.
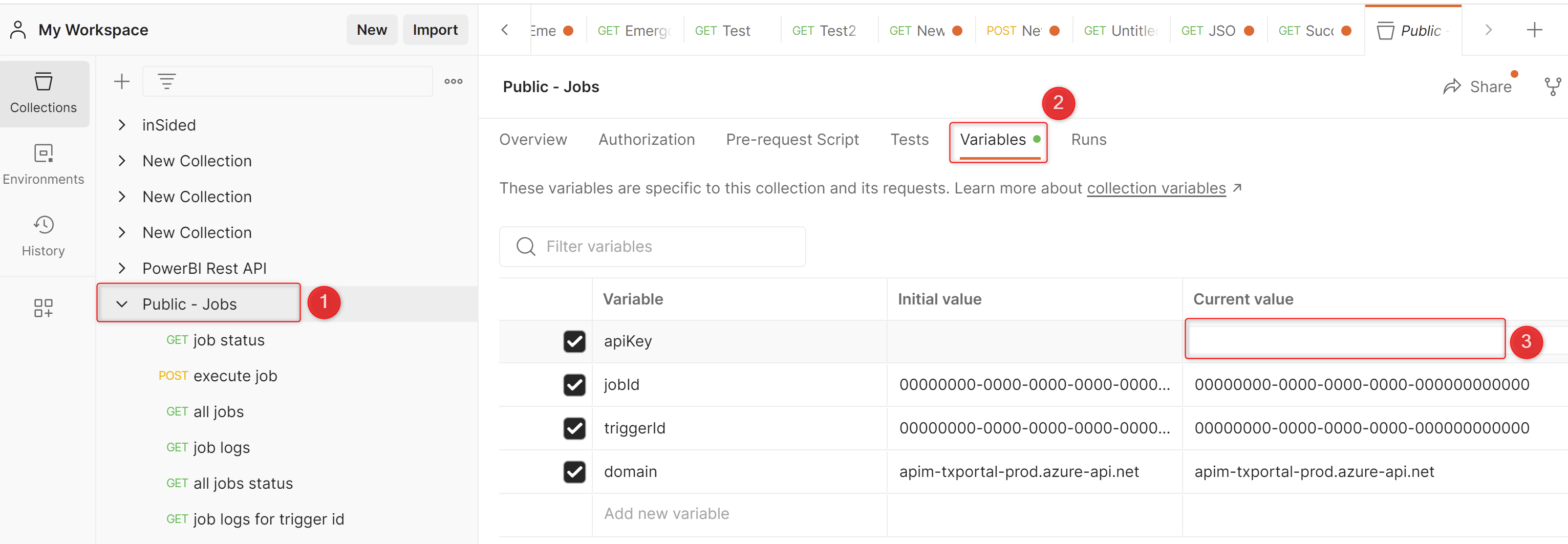
- In Postman, select the Public - Jobs collection that has been imported in the left sidebar
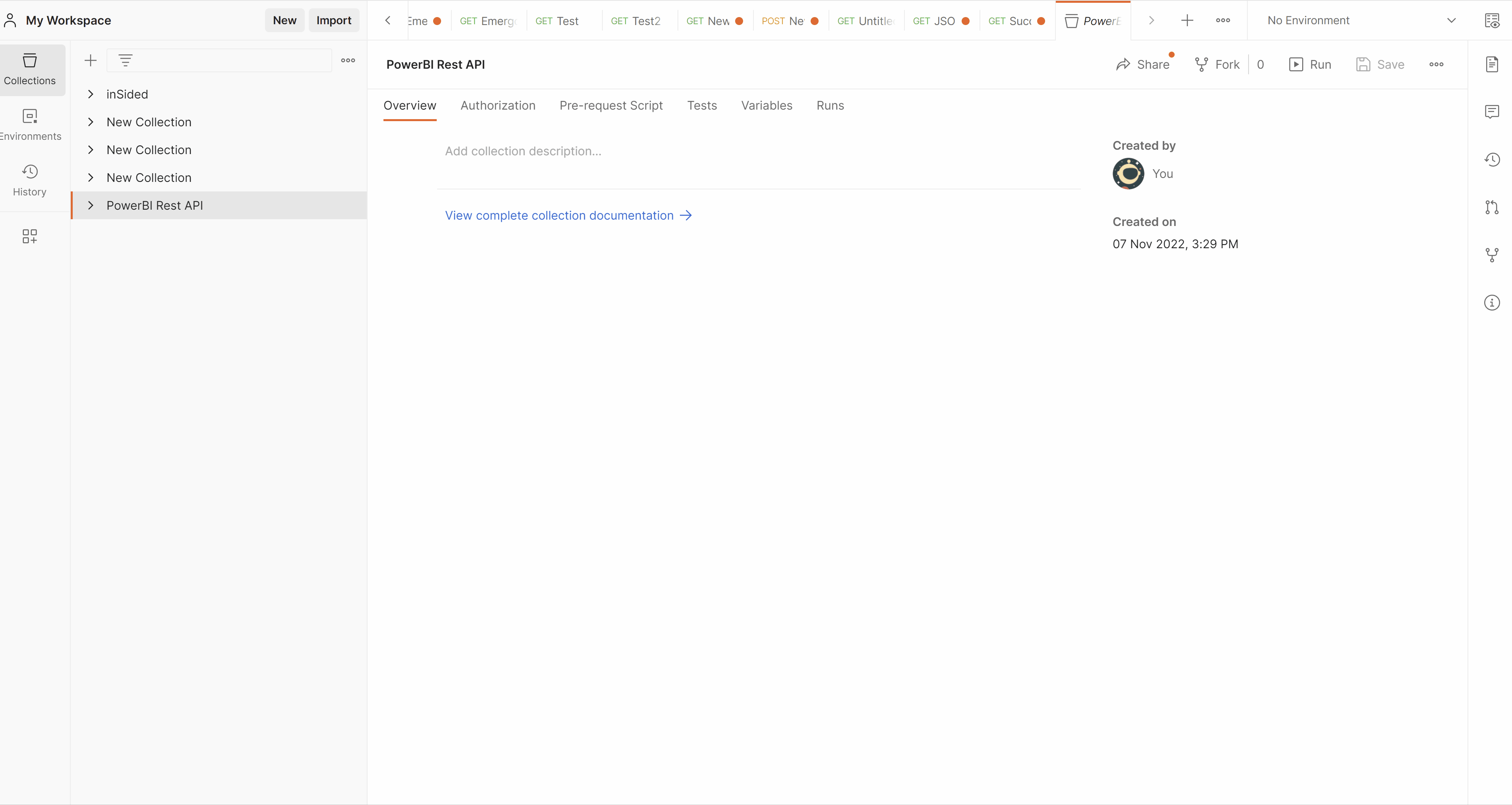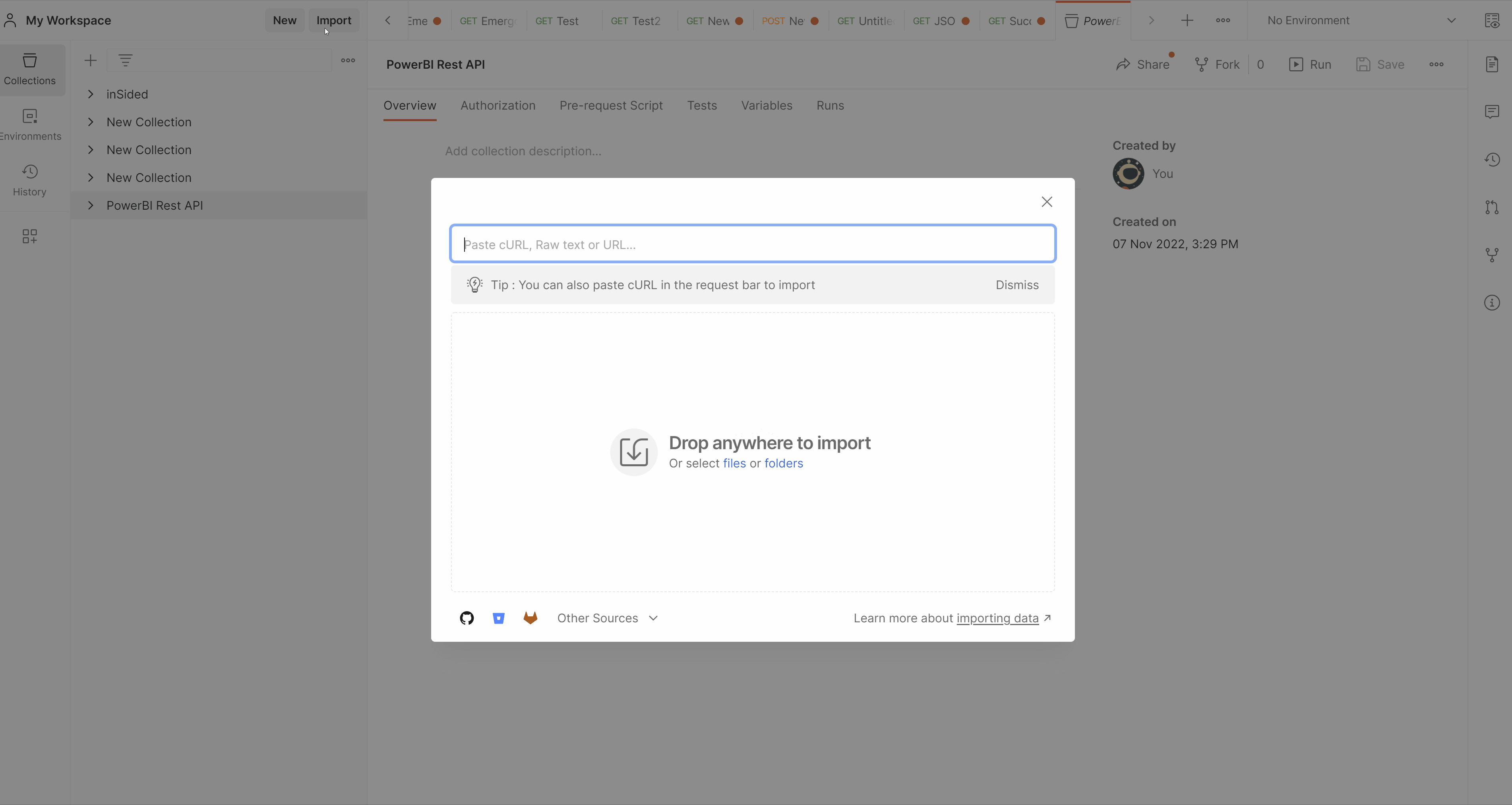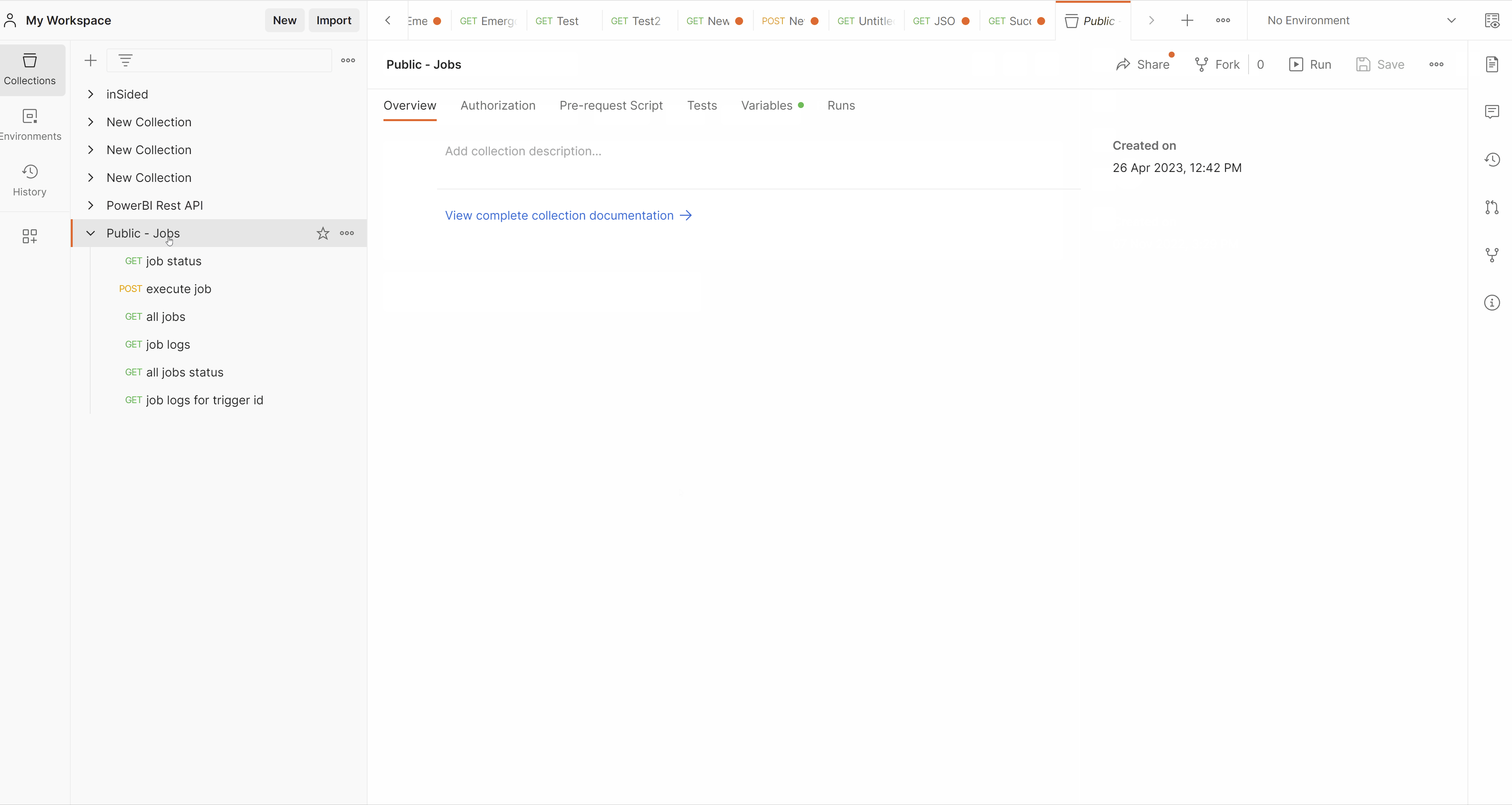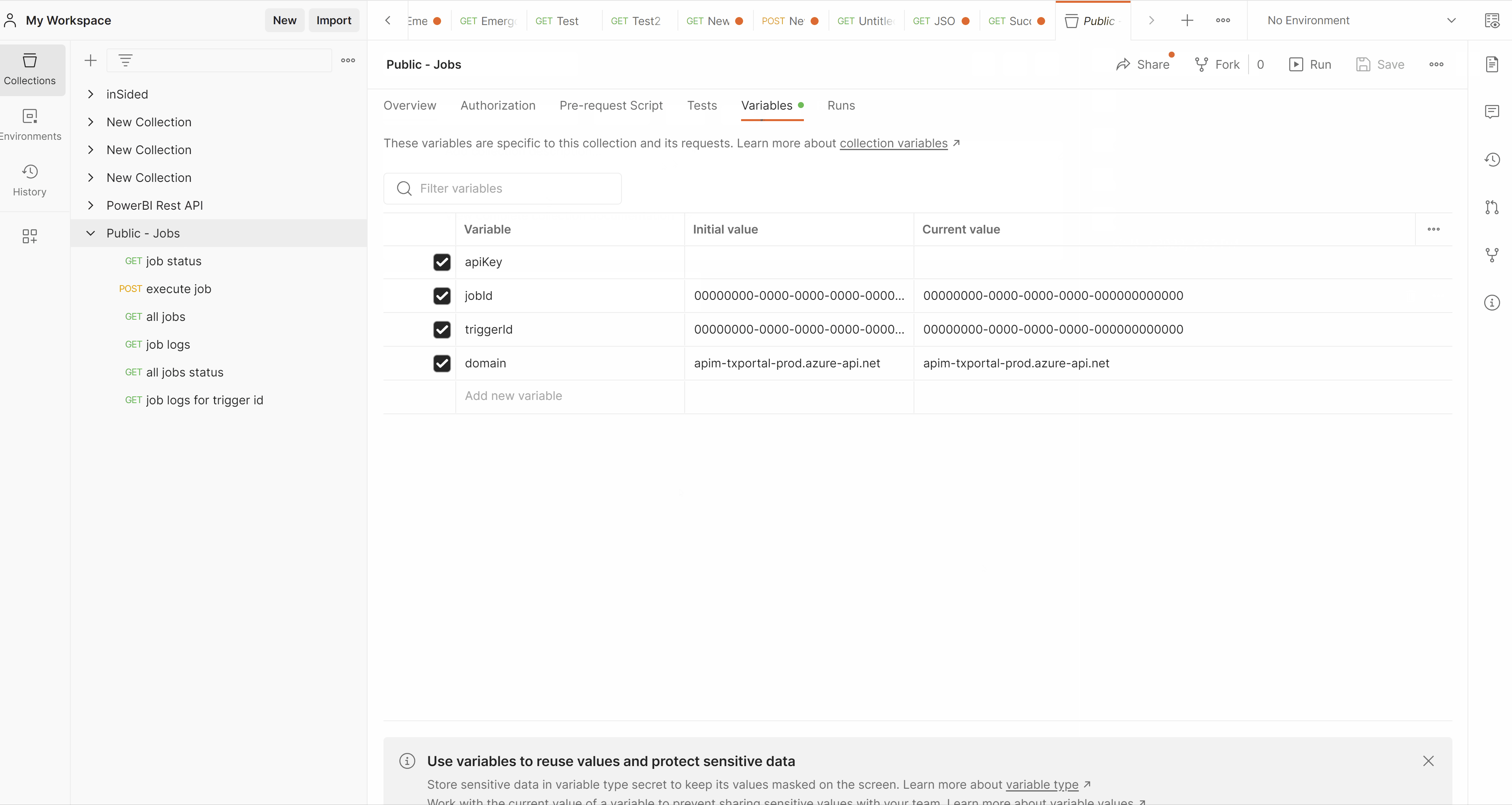
- Select the Variables tab
- Enter the API key in the Current value for the variable apiKey (for more info on how to create an API key see API Key Management)
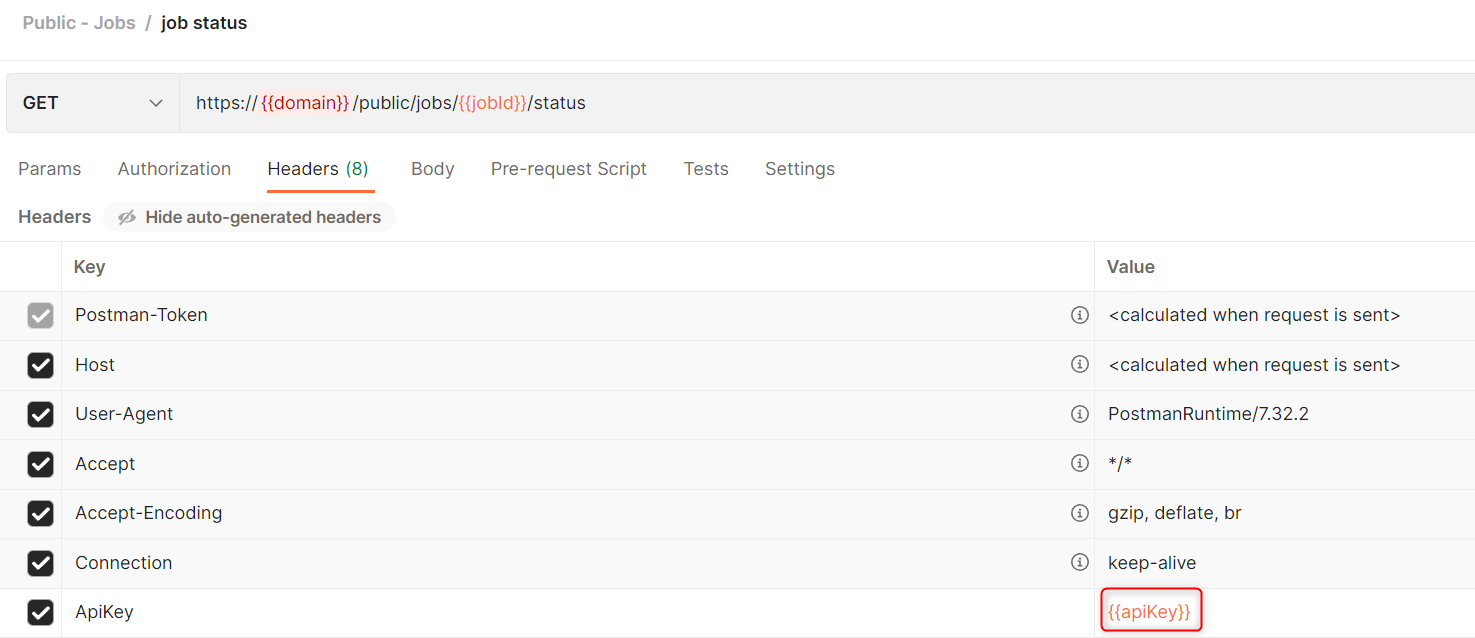
Once entered, the apiKey variable is used for the entire collection, as the variable is referenced in the request headers for the various calls. Alternatively, the variable above can be entered manually within the request headers for the individual calls. For example, the {{apiKey}} variable for the job status request can be replaced with the actual API key.
Variables
The following variables are included in the Postman collection:
- ApiKey - the API key that you have created in the Portal for your organization
- JobId - the Id of the job you want to execute, check status of, etc. Use the "Get all jobs" endpoint in order to retrieve the Id for your jobs
- TriggerId - the trigger Id of a specific execution of a job. This Id is returned when running a POST call to execute a job
- Domain - the base domain of the TimeXtender API gateway serving the public API
As mentioned in the Prerequisites section above, ApiKey must be added in the variables section in Postman. For some of the endpoints, JobId and TriggerId variables also need to be added by modifying the current value in the Variables section.
TimeXtender API Endpoints
Get All Jobs Endpoint
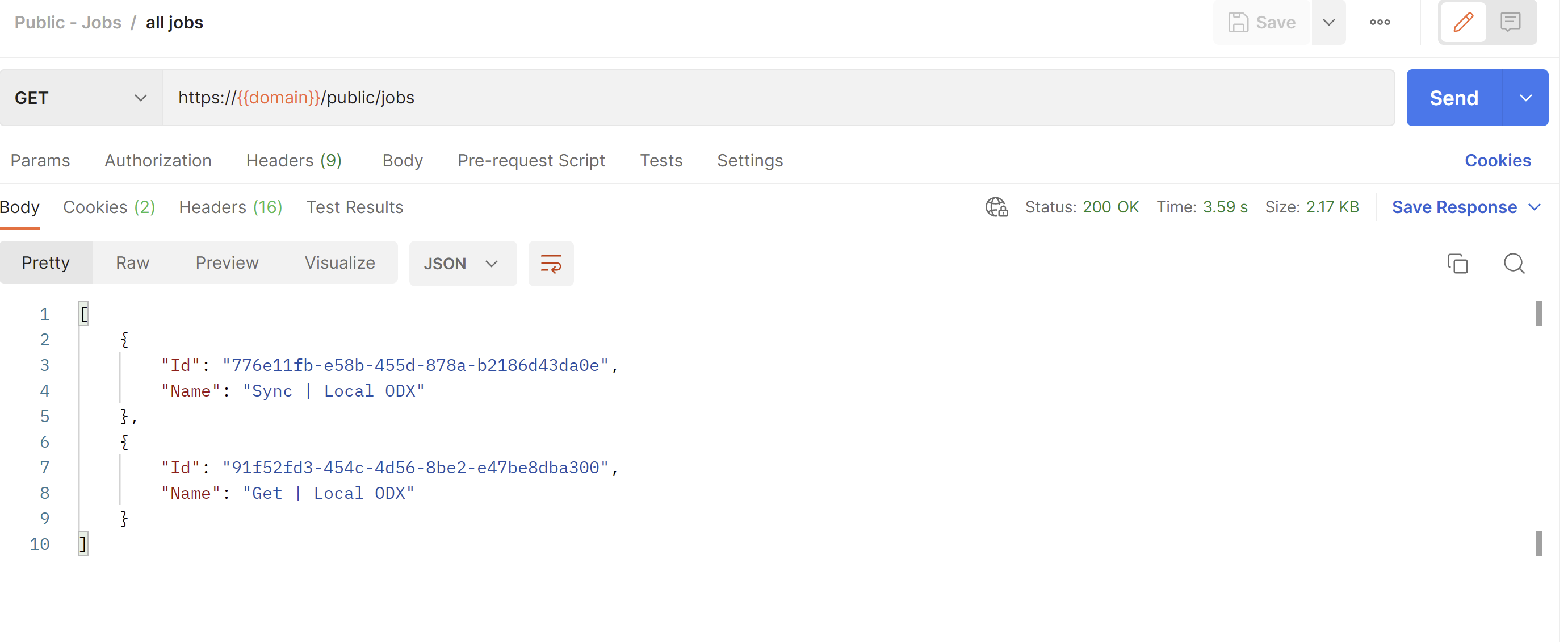
GET /public/jobs
This endpoint retrieves a list of all jobs for your organization. Each job consists of the following values:
- Id (guid) - the Id of the job. This will be used for most of the remaining endpoints as an identifier
- Name (string) - the name of the job
Execute Job Endpoint
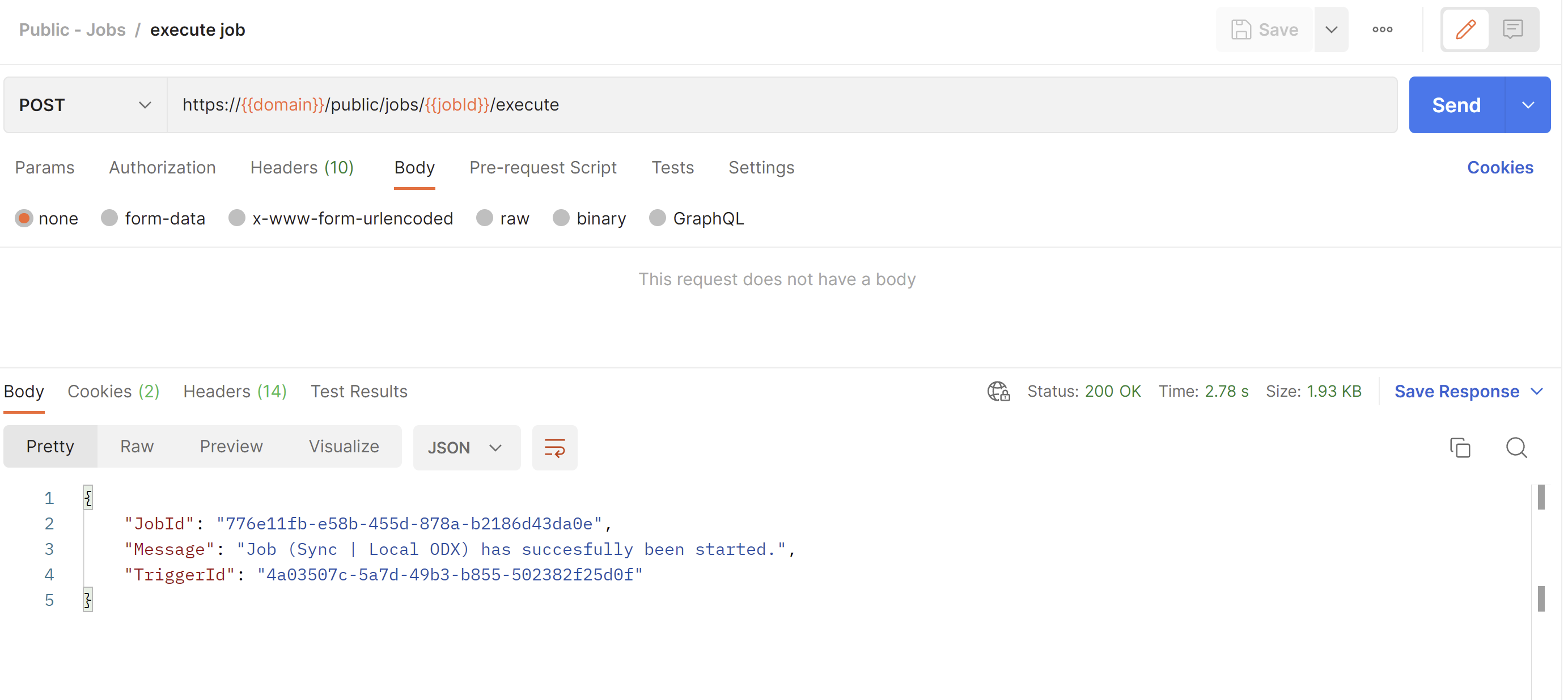
POST /public/jobs/{job_id}/execute
This endpoint will queue a job for execution by setting its status to "pending". The job will then be picked up by the application, at which point it will start the job execution along with execution logs.
If successful, an object will be returned with the following properties:
-
JobId (guid) - the Id of the job which has been queued to execute.
-
Message (string) - a message explaining that the job has been started.
-
TriggerId (guid) - a trigger id is unique to an execution and will be attached to the created logs once the job has been started. It can be used to filter logs.
Get Job Status Endpoint
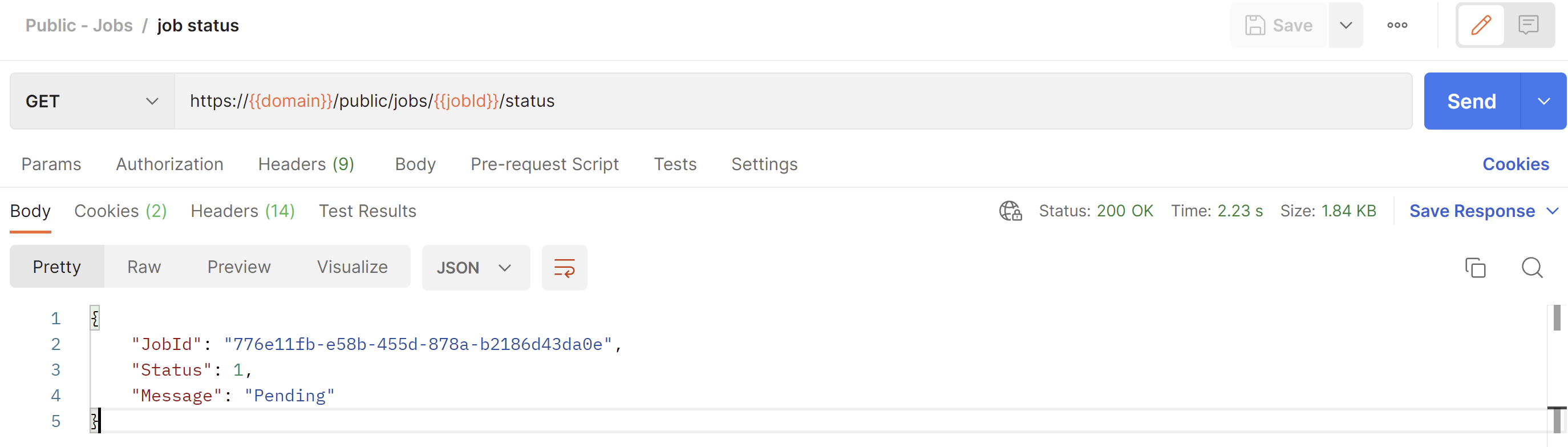
GET /public/jobs/{job_id}/status
This endpoint can be used to check the current status of a job. The following status codes exist:
- 0 - None
- 1 - Pending
- 2 - Running
A job will be "idle" until it has been executed. It will then go to status "pending". Once picked up by the application, it will change to status "running". When the execution finishes (or fails), the job will return to status "idle".
The status endpoint will return an object with the following properties:
- JobId (guid) - the Id of the requested job.
- Status (int) - the status code.
- Message (string) - a message explaining what the status code means.
Get All Job Statuses Endpoint
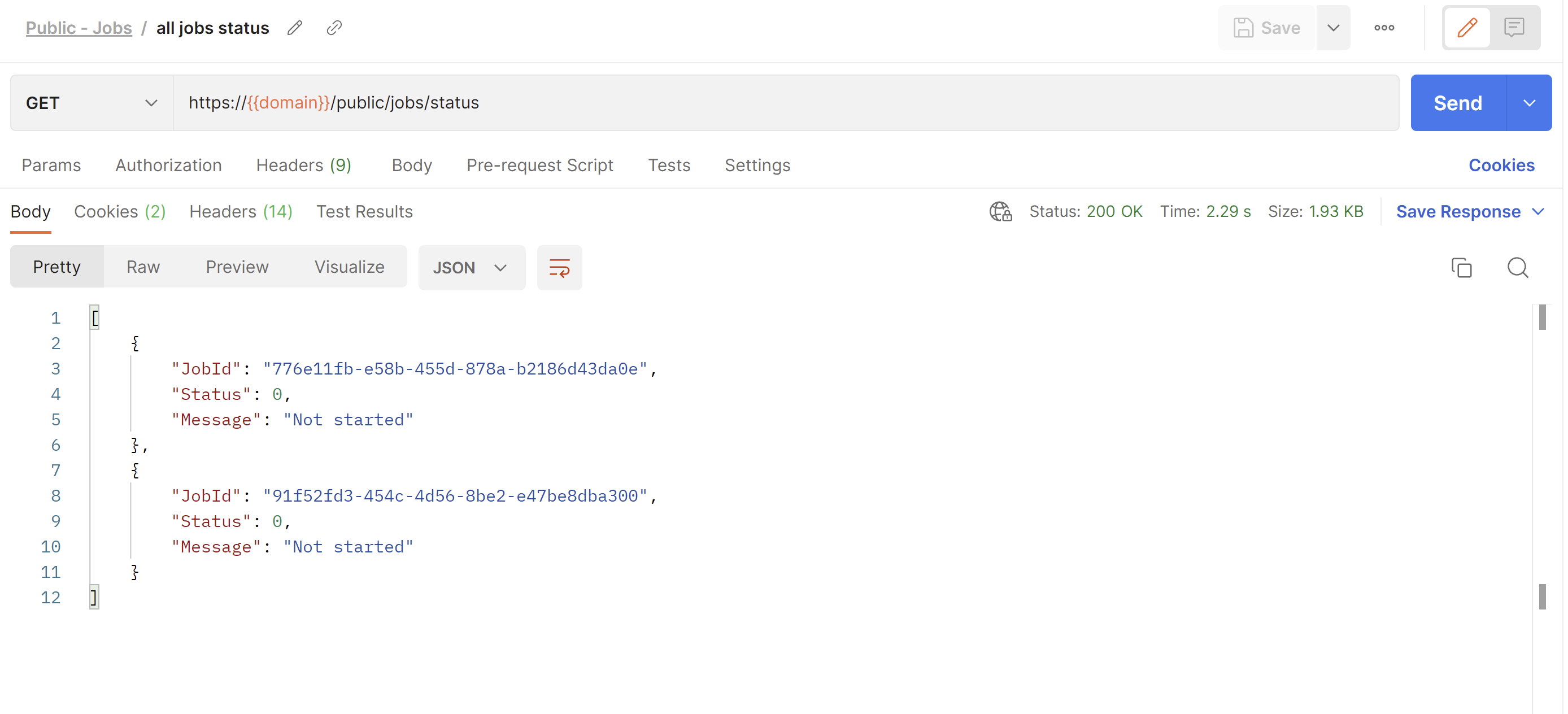
GET /public/jobs/status
This endpoint will return a list of statuses for all jobs in an organization. The status objects in the list will look identical to the one from the Get Job Status endpoint.
The all jobs statuses endpoint will return an array of objects with the following properties:
- JobId (guid) - the Id of the requested job.
- Status (int) - the status code.
- Message (string) - a message explaining what the status code means.
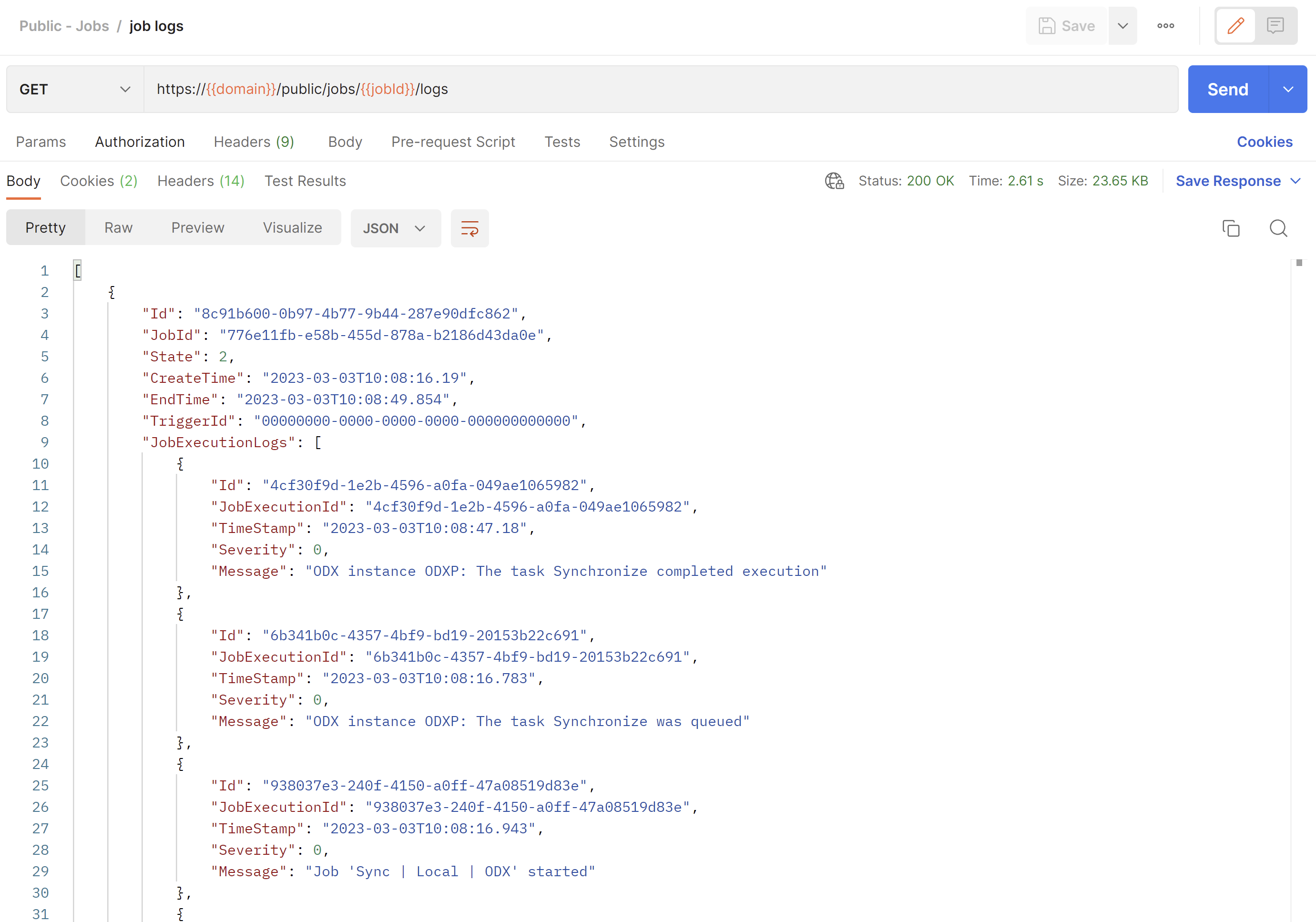
Get Job Logs Endpoint
GET /public/jobs/{job_id}/logs
This endpoint returns an array of job executions, as well as logs for a specific job.
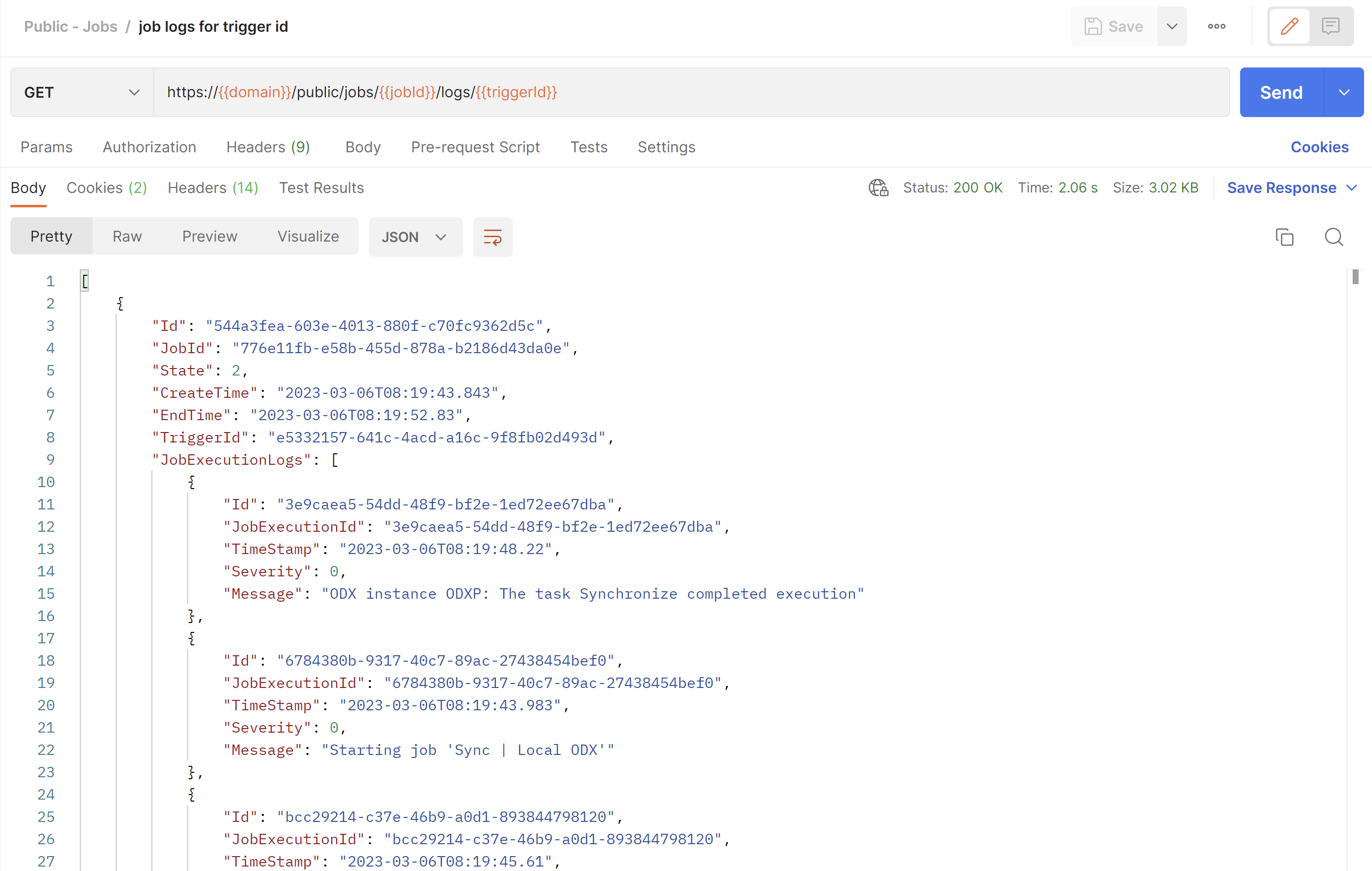
A job execution has the following properties:
- Id (guid) - the Id of the job execution.
- JobId (guid) - the Id of the job that has been executed.
- State (int) - the state of the execution.
- The following states exist:
- -1 - none
- 0 - created
- 1 - running
- 2 - completed
- 3 - failed
- 4 - completed with errors
- 5 - completed with warnings
- The following states exist:
- CreateTime (string) - the create time of the execution.
- EndTime (string) - the end time of the execution (NULL if the execution is still running)
- TriggerId (guid) - the trigger id of the execution (empty guid if started from the application)
- JobExecutionLogs (array) - an array of job execution logs.
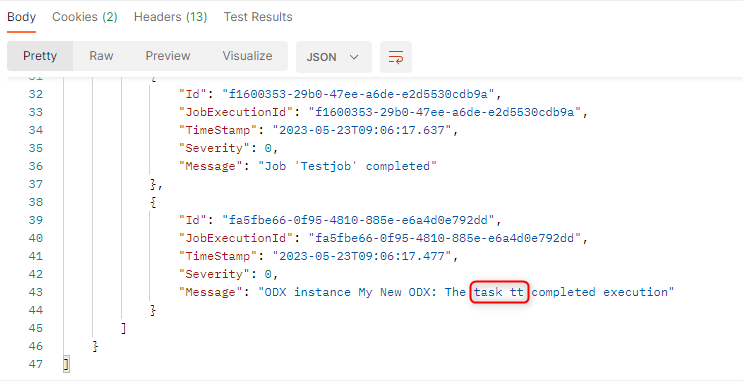
A job execution log has the following properties:
- Id (guid) - the Id of the log.
- JobExecutionId (guid) - the Id of the job execution which the log pertains to.
- TimeStamp (string) - a timestamp of when the log was created.
- Severity (int) - the severity of the log.
- The following severities exist:
- 0 - Information
- 1 - Warning
- 2 - Error
- The following severities exist:
- Message (string) - a message explaining what has happened in the log.
Get Job Logs for a Trigger Id Endpoint
GET /public/jobs/{job_id}/logs/{trigger_id}
This endpoint returns a similar result as the Get Job Logs endpoint, except it will only return logs with a trigger Id matching the one given as a route parameter. In other words, this endpoint allows filtering of logs based on a trigger Id.