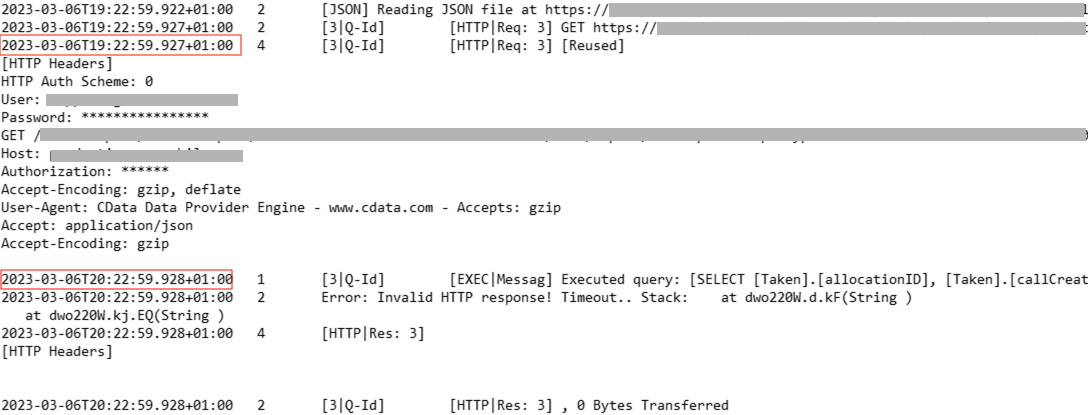
We’re facing issues with CData REST API connector when requesting an API for a large dataset. TX sends the request, but seems to never receive a response. The execution fails when it hits the timeout limit (currently set to 3600 seconds).
In the logs (verbosity 4) I see that nothing happens between the time that the request was sent and the moment of timeout.
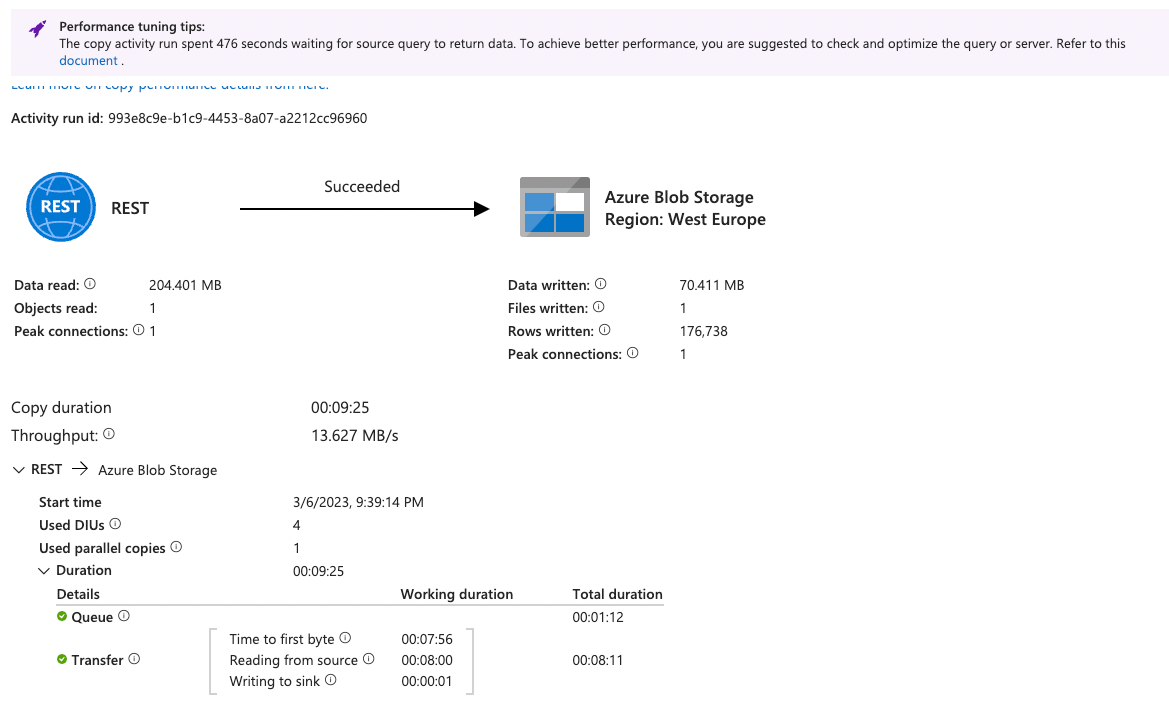
I put the same URI, headers and parameters in Azure Data Factory. After 9 minutes it receives a response of 204MB and 176K rows. In Postman, I received a response after 8 minutes.
While I agree that it might be better to somehow make smaller API request. In fact, when I limit the date range to only this year, TX gets a response in about a minute. However, I still expect TX/CData to finish the request when the dataset is larger and it takes more time before the response is generated by the server.
Due to NDAs I cannot post logs, RSDs or credentials here, but I’ll send some additional files via email.
Tx version 20.10.39 CData REST API version 22.0.8423.0
Another thing the customer can change is remove the Accept-Encoding:gzip line from the CustomHeaders property in their connection string. Our driver automatically appends this header, and it is possible that having 2 separate Accept-Encoding headers could be causing an issue in the server's response.
If they still continue to run into timeout issues, would they be willing to allow us to use their credentials to test this API on our end and see if we can identify what is causing the response to be blocked?
Let me know if they continue to run into issues or if they have any questions.
Thank you. I agree that it should not just timeout. We’re also discussing the issue with the creator of this API. It would be better to load this API incrementally, but so far we don’t have the parameters needed.
If you have a start and end date option of the URI, you can apply something close to incremental load. The issue will be if you don’t have a date field to apply the incremental rule on.
If that is the case, I would do the following.
Use the dynamic date option I have in my RSD guide in the file you got. For the first few executions you run one year with fixed start and stop date.
You store this in a table with history applied and no deletes. Then you run all subsequent years like this until you reach present time. and then you set it to pull the last few days on each execution.
It may transfer the same rows, but it will not be that many and since the source runs with history, it will be able to control it so no doubles are applied.
Ok, thanks for the suggestion. Will have a look at it. What makes it complicated is that the API queries from a Mongodb and translates all tables to a relational model. As a result, some tables including this one do not have a primary key. Even the combination of all fields does not result in unique rows. Somehow (according to the business) this makes sense and they told me not to remove duplicates. I will discuss it once more, because I have the idea that we are not receiving all attributes.
If the table does not have a primary key, you can get around it by generating a supernatural key that consists of all of the fields, so it hopefully becomes an unique key. You can set this key as the primary key and then still set up history.
If there is no way of making an row unique even setting all rows as pk I would argue that the only benefit would be to show how many times this rows appeared, maybe with an additional custom query that counts the rows based all the fields as a group by.
Another thing the customer can change is remove the Accept-Encoding:gzip line from the CustomHeaders property in their connection string. Our driver automatically appends this header, and it is possible that having 2 separate Accept-Encoding headers could be causing an issue in the server's response.
If they still continue to run into timeout issues, would they be willing to allow us to use their credentials to test this API on our end and see if we can identify what is causing the response to be blocked?
Let me know if they continue to run into issues or if they have any questions.
The API developer will setup a test environment soon, also to test a new feature which will allow us to load incrementally. Maybe I can share these credentials when it’s ready.
Hi @Christian Hauggaard, yes we have and we perform incremental loads now. It’s been running fine for about two weeks. I don’t think the issue mentioned here is fixed, but we have a solid workaround.
I can still share the test credentials for CData if you like.
We use 3 different kinds of cookies. You can choose which cookies you want to accept. We need basic cookies to make this site work, therefore these are the minimum you can select. Learn more about our cookies.