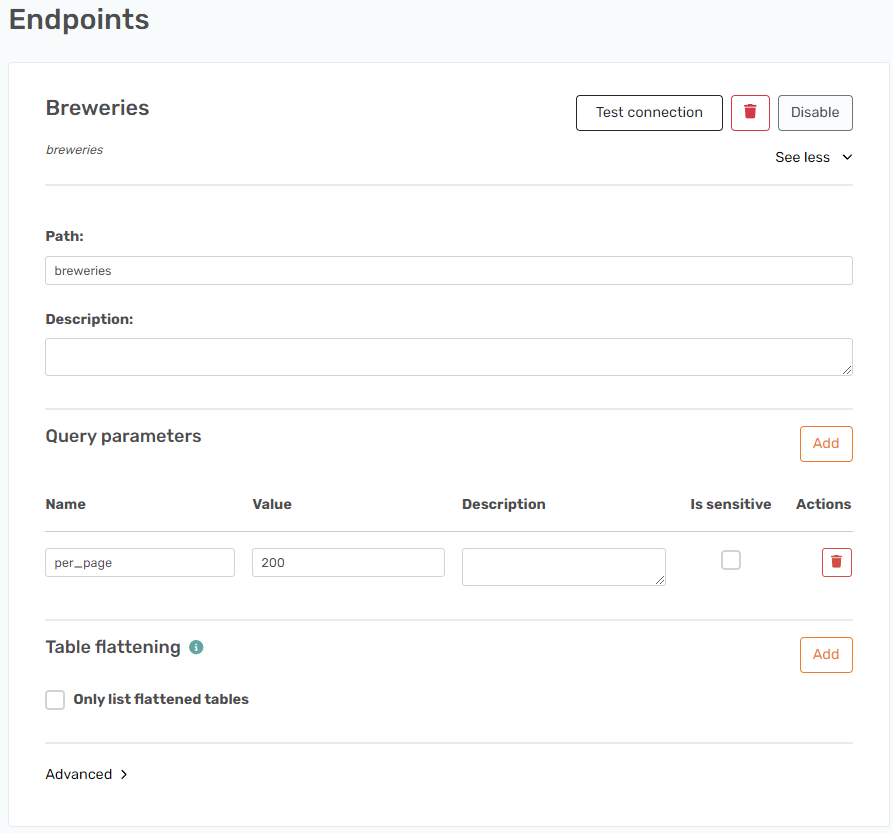
There is an API that gives a list of breweries called openbrewerydb.org. It is very simple as it only has one endpoint, but it contains a lot of options to filter what is returned. Namely the way it uses pagination with a page and page size parameter.
The issue is figuring out what page comes next and what the last page is. This is not shown anywhere in what is returned. As you can see in this image.
This is all that is returned, there is no info shown regarding what the next page or last page is. Also not in the headers or the metadata of the returned page.
If it returned the next page in a header you could use this GoREST Pagination guide and if the next page was shown in the metadata somehow this Graph API Pagination guide can be used.
Since those options aren't available, we will instead be using an option where an added operator will increase with one on each iteration starting at 1. This option is a operator you can add that is called {TX_NextPage} and it will increase its value with 1 on each iteration.
Initial Setup
Give the REST data source a name such as Open brewery and apply https://api.openbrewerydb.org/v1/ as the Base URL so it will be set up like so.
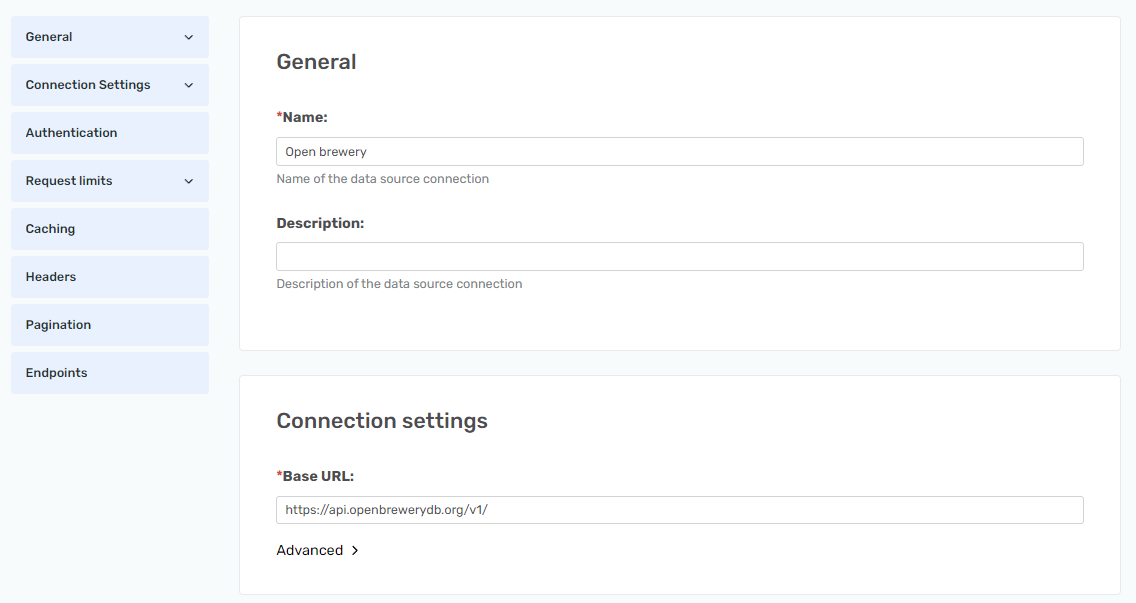
Pagination
As mentioned we will use the {TX_NextPage} operator option to do the pagination, but since we do not know the last page we will also need a dynamic stop condition that will tell when to stop increasing the value.
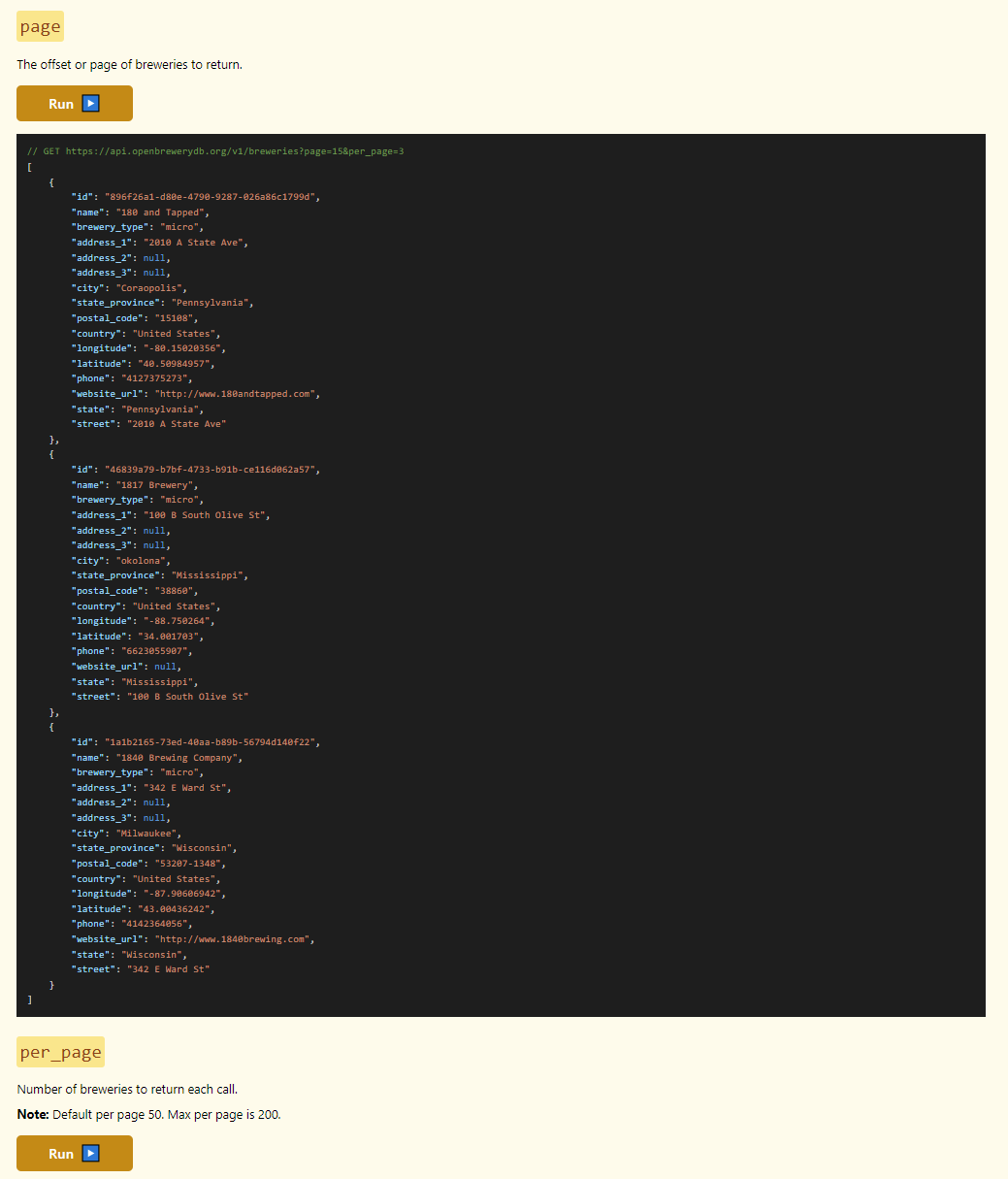
To figure out how to find when it should stop you can add a check on what is returned and then see if the returned contains what you look for. So if you set up that it should increase the page value on each iteration, the first page will look like this.
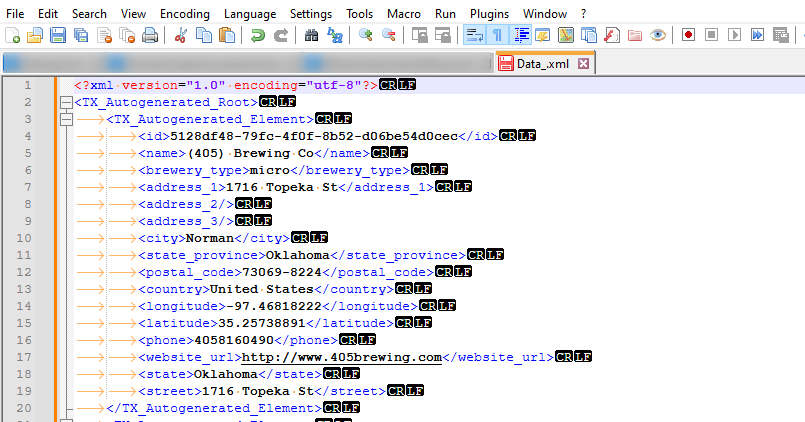
And the last page will look like this.
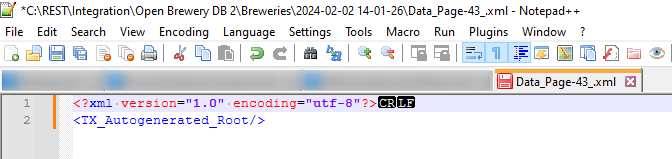
This means that the rule made to stop should check whether the file is empty and if so stop. The XPath rule that can do that is the following (*/*/*)[1]. The rule means that it will check if there is any content after the third level and if there isn’t it will stop. A different wording of the XPath rule could be (TX_Autogenerated_Root/TX_Autogenerated_Element)[1]/*[1]. The reason it checks for three levels is that there could be another level below TX_Autogenerated_Element that could be sent back without having any real data.
The only parameter we add in the pagination area is the page parameter. In this API it is called page and not Page. This is an important distinction as an incorrect case setting of all the characters can make it not work. There also is the per_page parameter, but this needs to be added at the endpoint instead.
The reason for this is that it does the first call without any pagination applied and therefore would also not add the per_page parameter for the first call. So if you by default get 50 rows and set it to run with 200 the first page would return 50 and the following 200 which would make it miss 150 rows when you get to the last page.
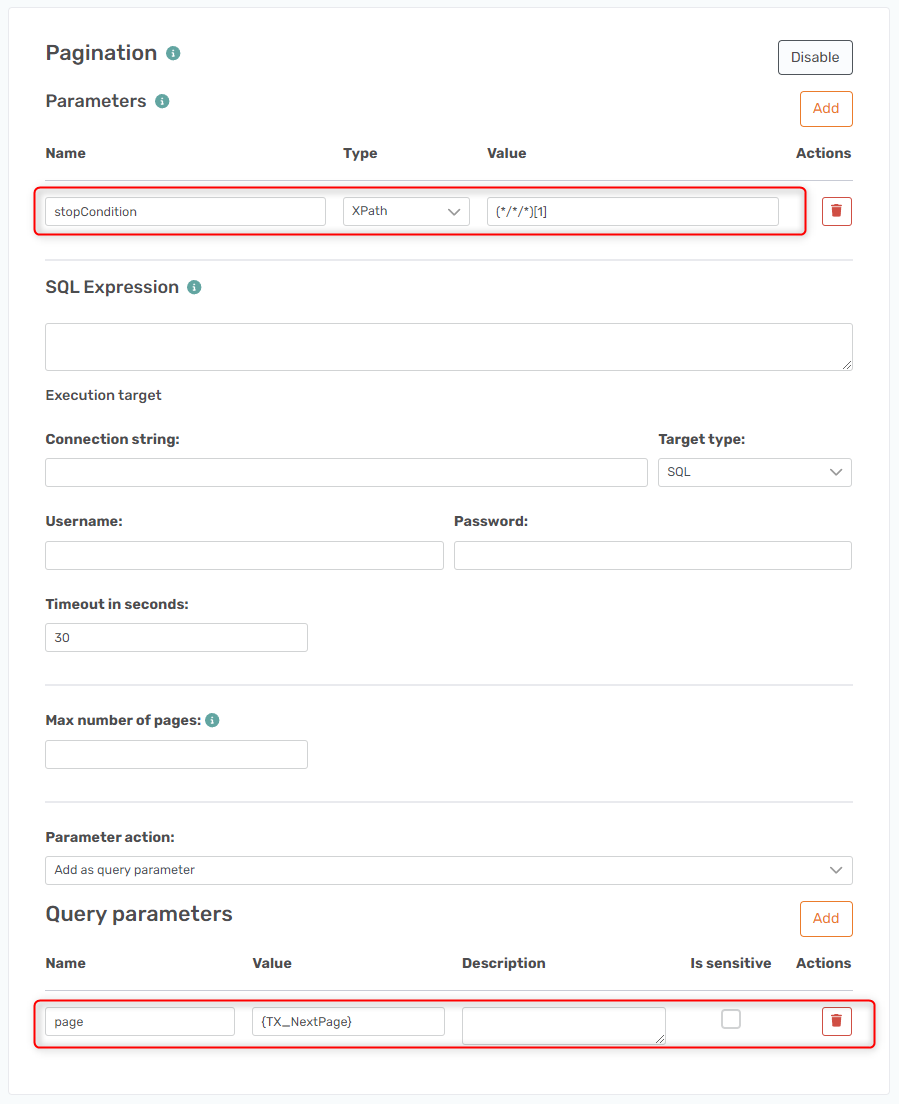
You need a Parameter with the Name field equal to stopCondition, the Type field equal to XPath, and the Value field equal to (*/*/*)[1]. You need a Query Parameter with the Name field equal to page and the Value field equal to {TX_NextPage}.
It should look like this.
Endpoint
As mentioned there only is one endpoint for this API and it is called breweries. In the pagination guide above I mentioned that the per_page parameter needs to be applied to this part instead of the pagination.
You need the Path to be equal to breweries and the Name equal to Breweries. Then your Query parameters need to be set to Name field equal to per_page and Value field equal to 200.
It should look like this.