Hi,
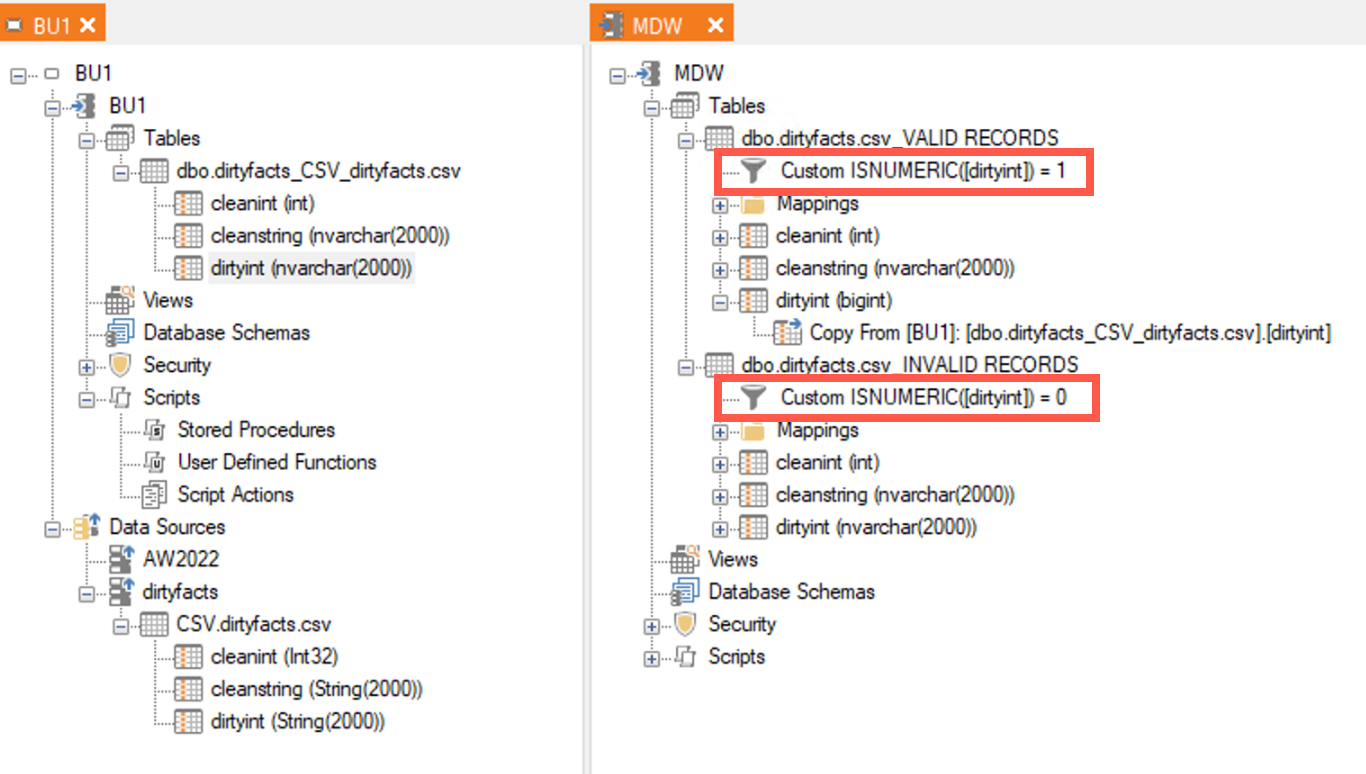
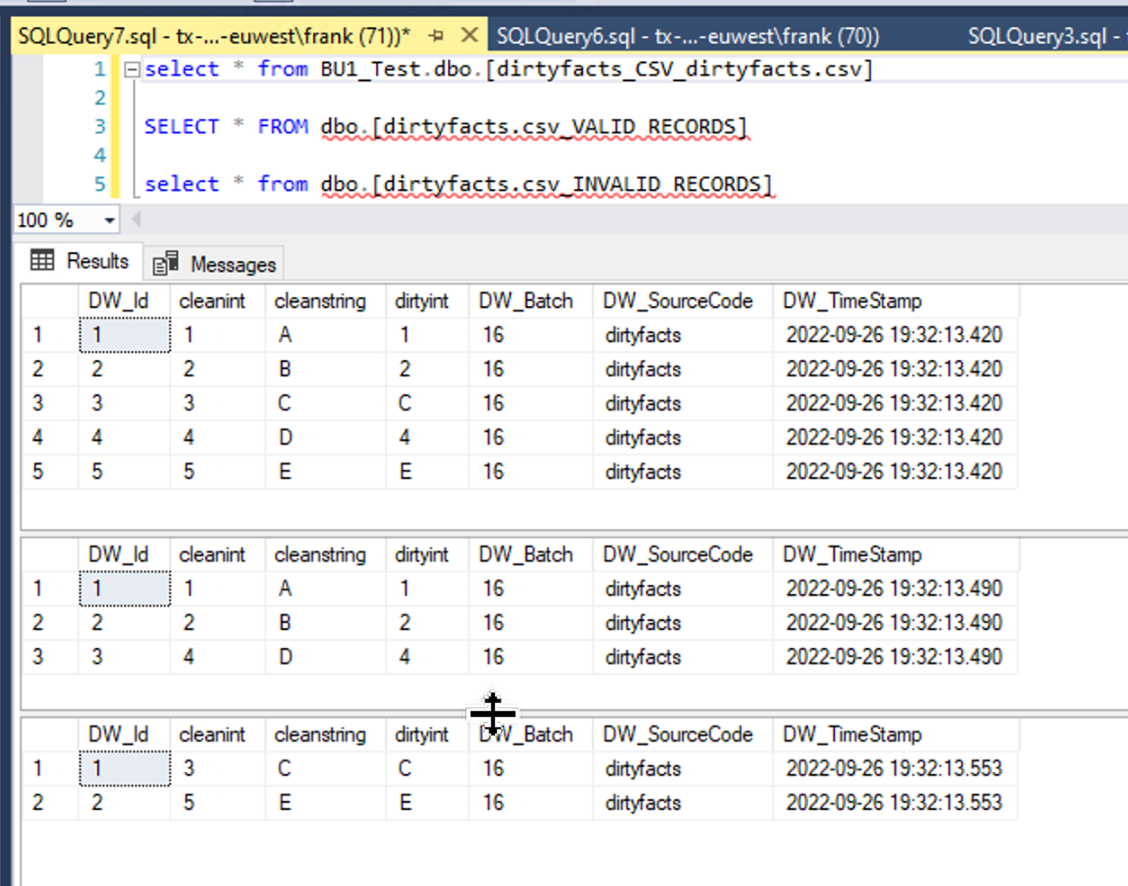
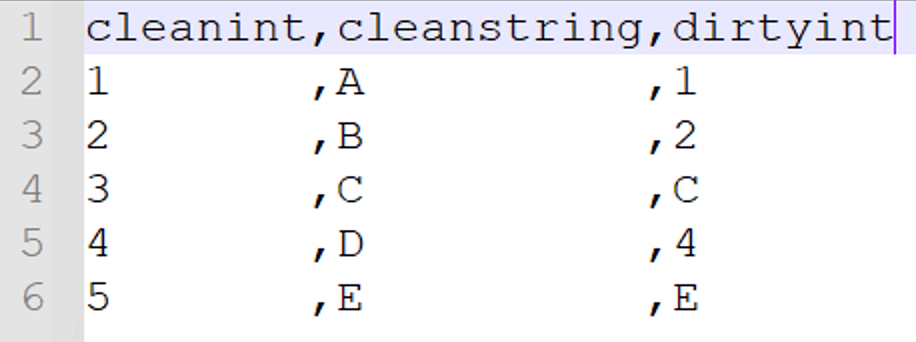
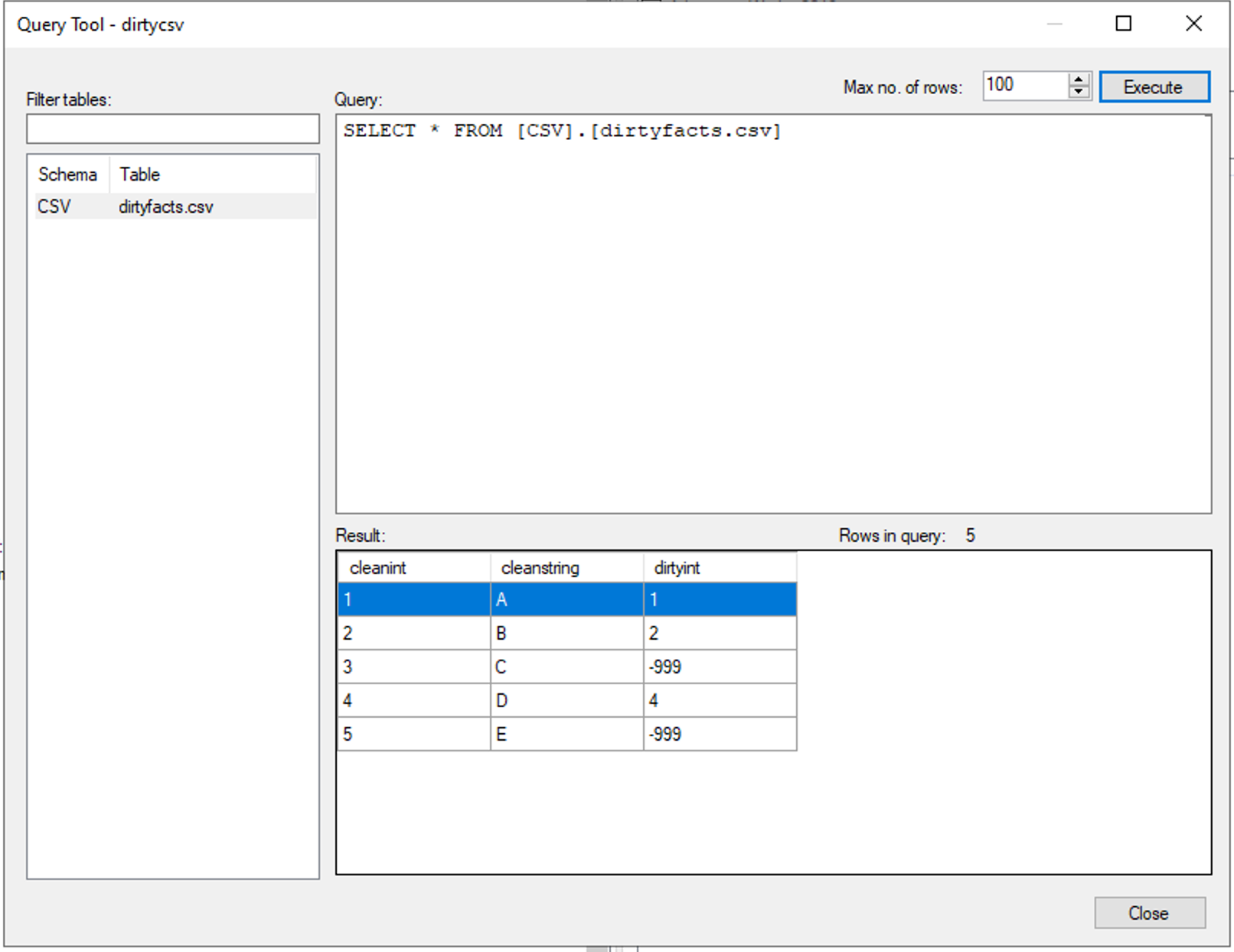
Let's assume I am importing from CSV file. The Data is very dirty and somehow I have stings in my int filed "ID" so the filed is interpreted as NVARCHAR(MAX). If I change data type of the field (right click > Edit Field) from string back to integer I receive a runtime error during the execution. What I was expecting was to see was corresponding entries in the _M and _L tables. Is this not part of data cleansing after all?
We have this problem all over and could not find a better solution than to build custom views with TRY_CAST etc. where we lose lineage etc.
What is the best way to clean up such data (keep valid rows, write errors/warnings on invalid rows)? We are talking 100+ tables so I'm looking for a highly scalable solution here not a one time work around.
Thanks and BR, Tobias