Dear Community,
I like to build my data estates with supernatural keys but in lager datasets the data cleansing starts to take very, very long. Do you happen to have the same issues? Is there a way to make the supernatural keys load faster? Even with incremental loading it begins to be super slow:
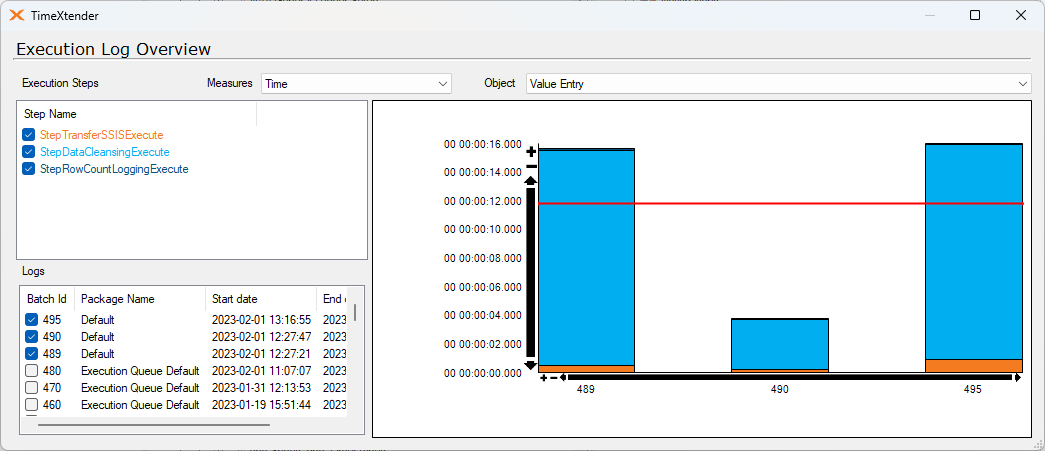
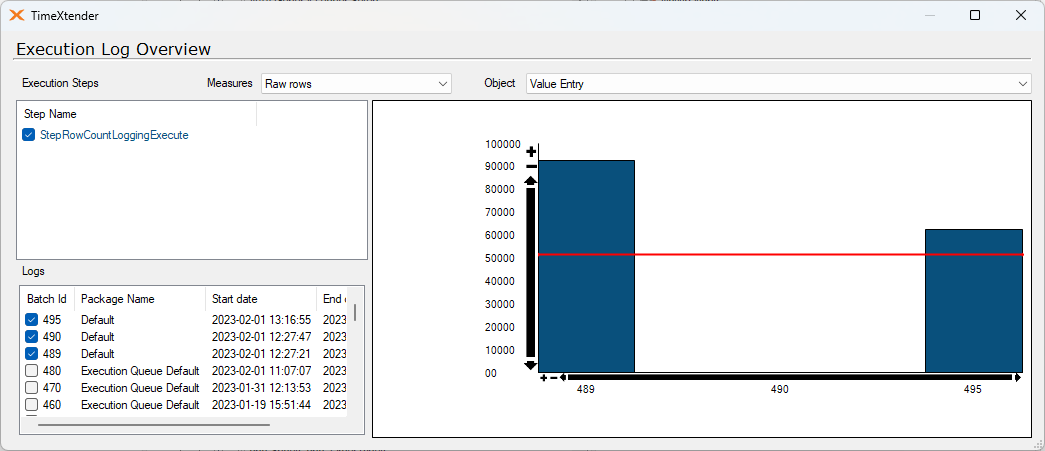
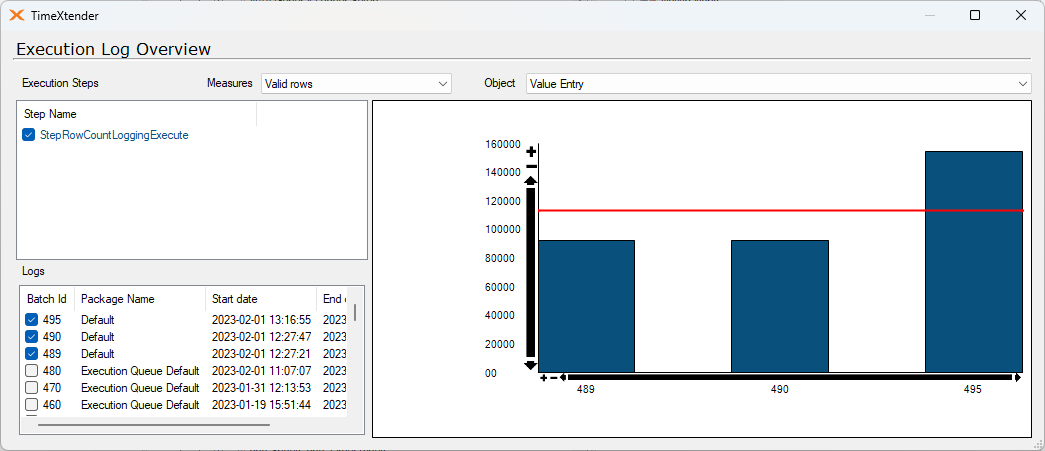
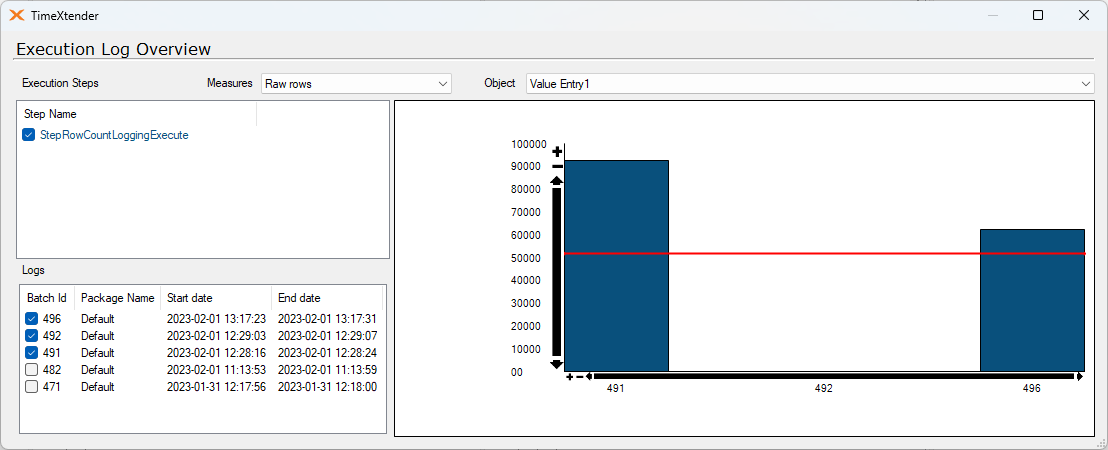
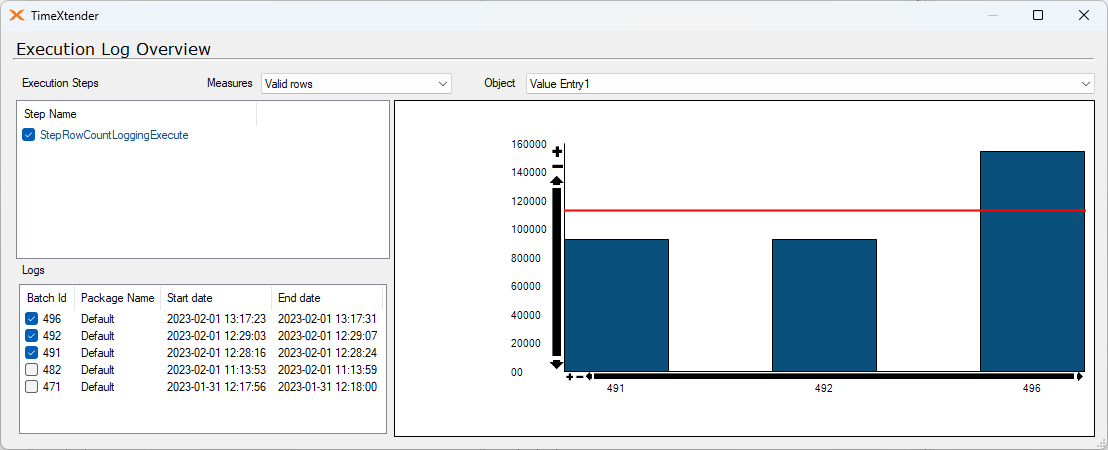
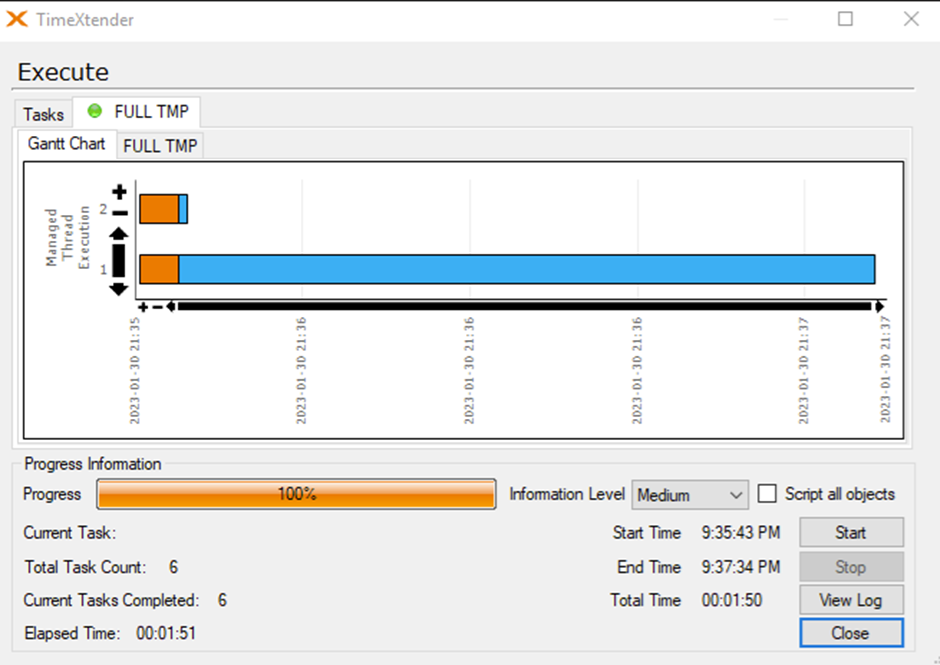
I've ran a test on 435,397 records. This is on a Azure SQL with 10 vCores
1. is a full load on the table with 7 supernatural keys.
2. is a full load on the same table without the supernatural keys.
1 has data cleansing of 1 second. 2 has a data cleansing of 104 seconds!
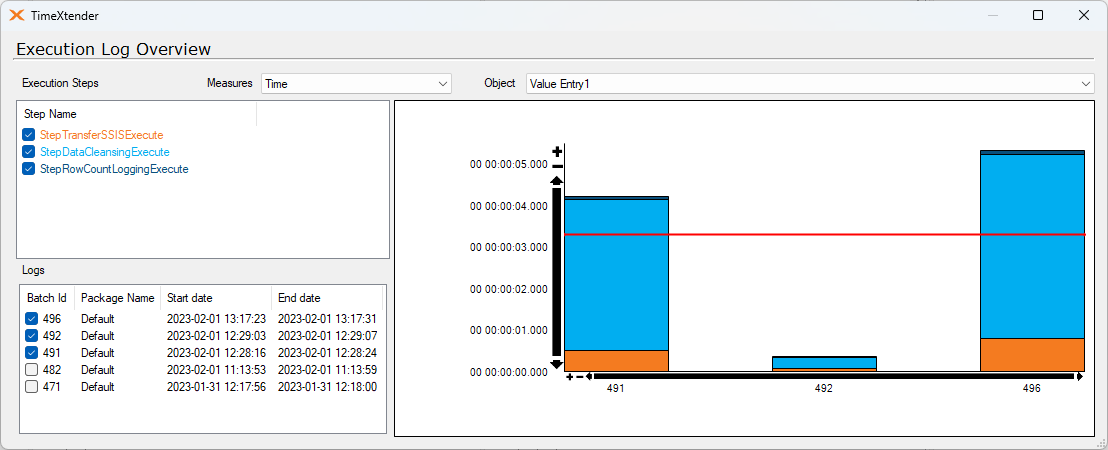
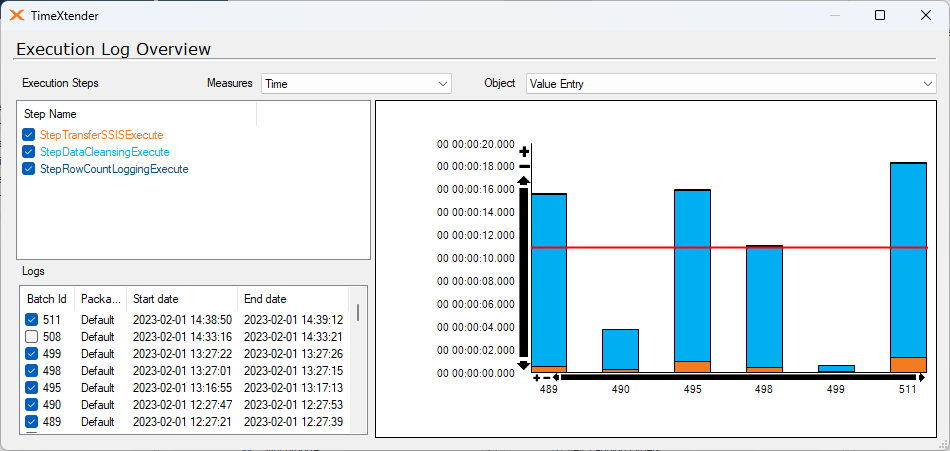
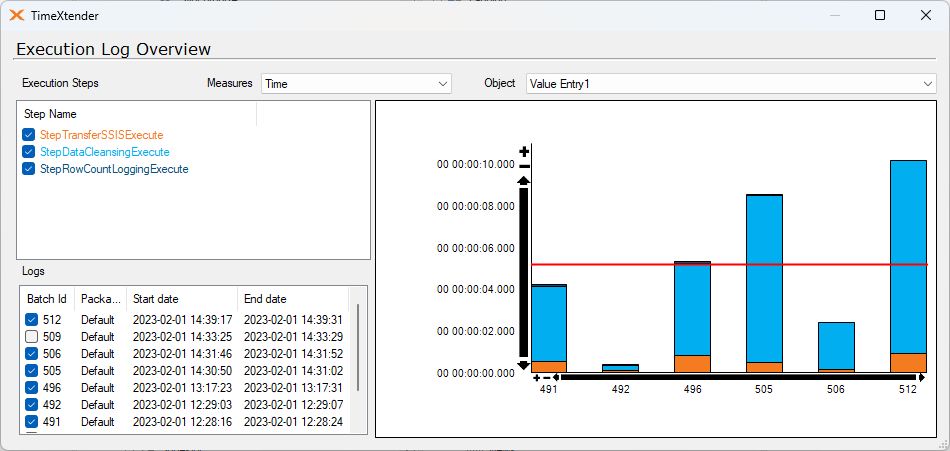
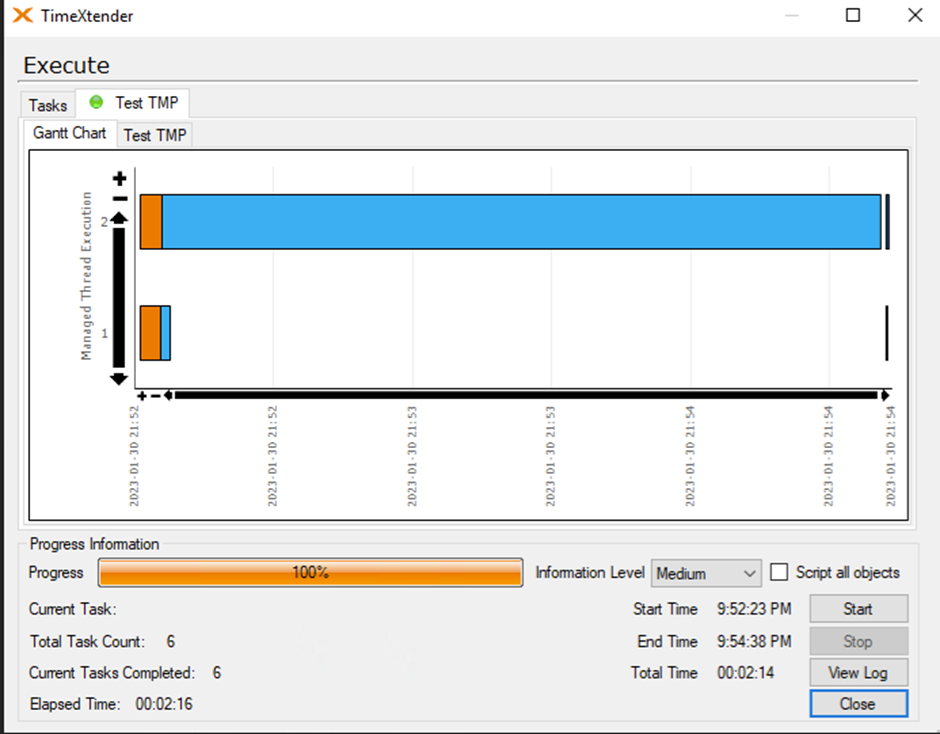
Second I've done a test on the same tables but now incremental loads:
1. incremental load with 7 supernatural keys
2. incremental load without supernatural keys
1 has a data cleansing time 1,6 seconds and 2 a data cleansing of a whopping 129 seconds!
I'm not so sure I want to keep using the supernatural keys. What do you guys do?
Take care
= Daniel