

I am having some issues with the transfer step when loading incremental using direct read. The problem seems to be that the generated procedures do not utilize indices on the underlying tables, resulting in full PK scans for every run.
I was especially having problems when running on azure general compute. Switching to hyperscale helped some, but the transfer step still uses approx 40sec scanning ~90m rows causing bottlenecks.
When using ADO.NET I could set an index on the incremental rule-field speeding up the search to <1sec.


The execution-plan generated by TX looks like this:
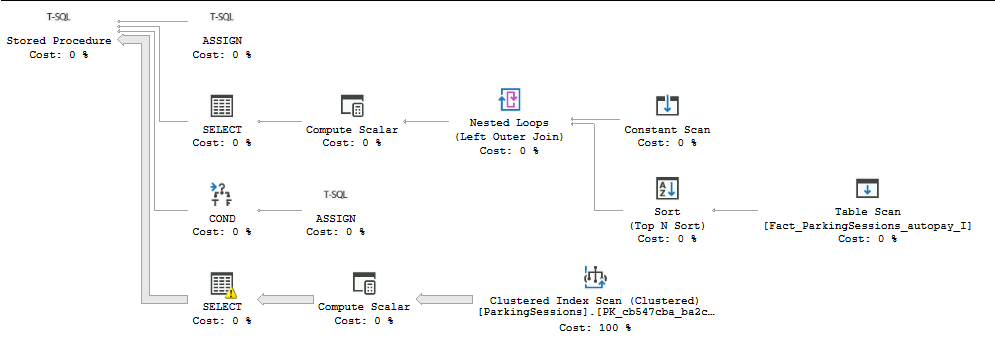
Here we get a PK index-scan even when there is an index on dw-timestamp.
Testing on a subset of the data (~10mill rows):
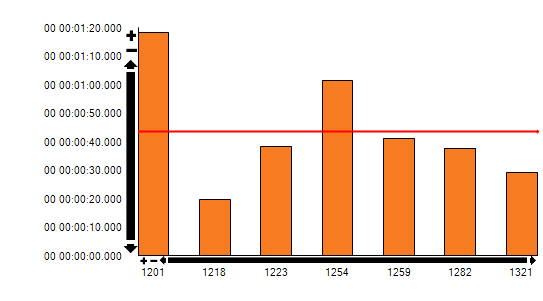
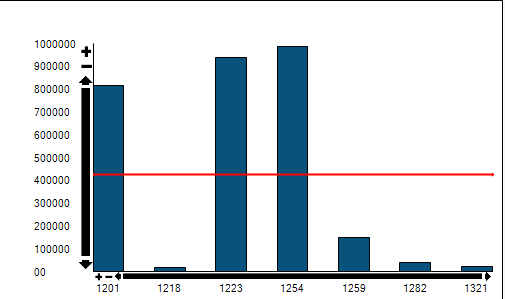
Adding the option(recompile) to the procedure results in the procedure using the dw-timestamp index:
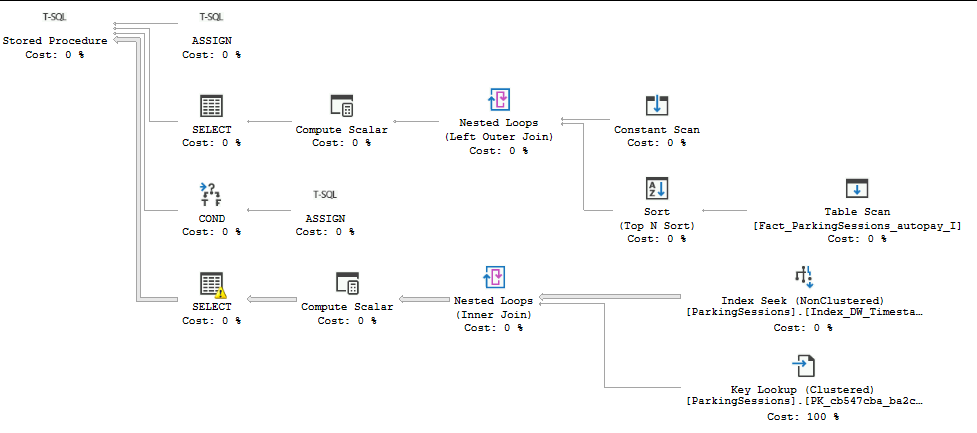
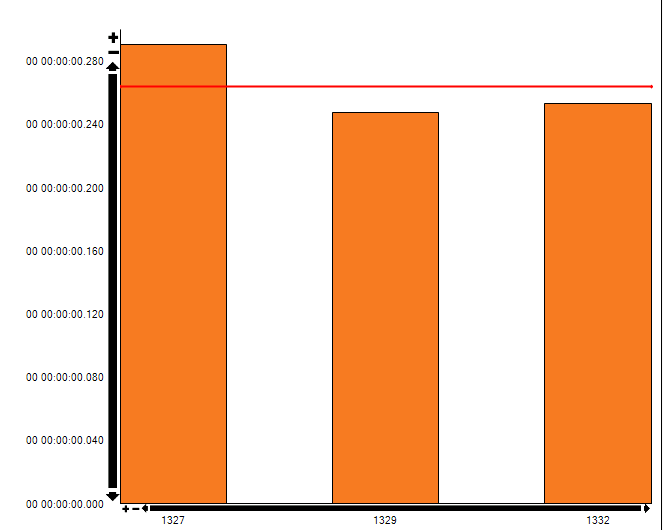
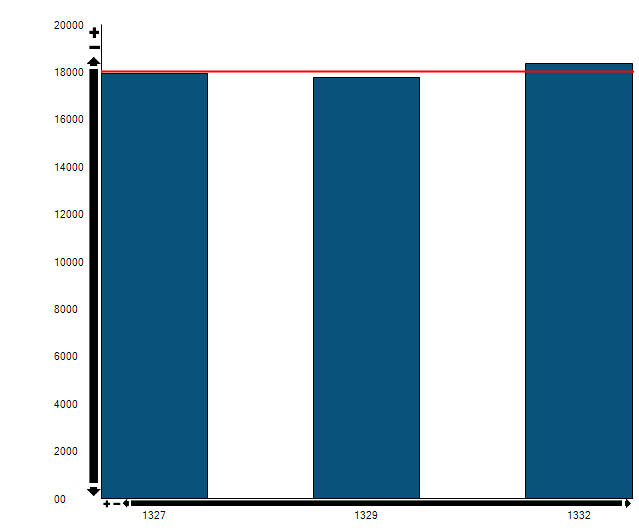
Is there a good reason for why these procedures are generated without the recompile flag?
Is it something that could be added in a later release?
And is there a way to work around this other than reverting to ADO-net transfers or SSIS? Scaling the DB/service tiers to compensate for something using a simple index could do better seems like a poor solution.
Might be semi-related to this post:ADO.NET Transfer consistently slow on incremental table with no new rows | Community (timextender.com)



