Hi all,
I have a client that has a datalake with parquet files in an Azure Storage Account Blob container (Datalake Gen2). This datalake has not been created by ODX server, but has been created by Synapse (scripted, delta lake parquet files). Since we want to load multiple tables from multiple folders we use the CData Parquet connector v2023 (TX 20.10.41). The issue we have is that we can’t find the right settings for the connector to recognize that the folder we’re connecting to contains multiple tables and that the parquet files are in a subfolder of the table folder.
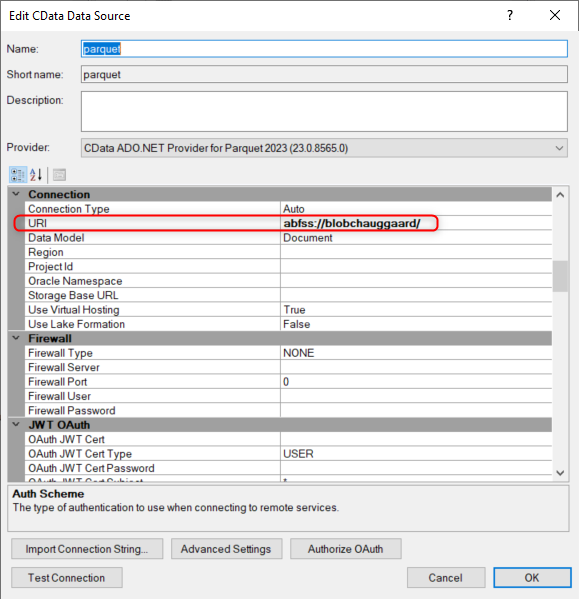
For the connection we use a Shared Access Signature and the connection is working:

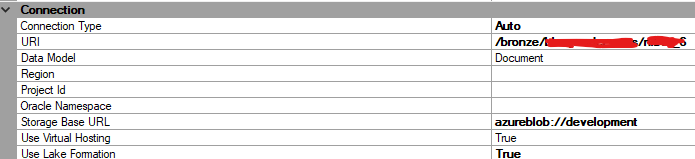
The name of the container is ‘development’ which we configure in the Base URL. In the URI we point to the folder of the bronze layer, the system and the database:
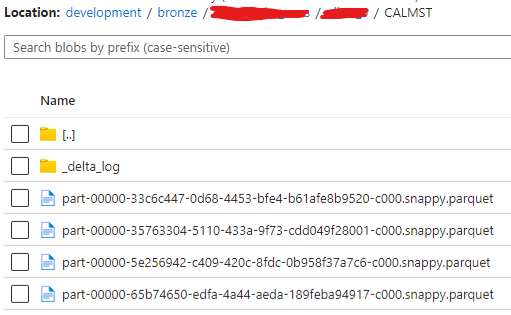
The database folder contains a folder for each table. In each table folder some tables have a a partition folder followed by the actual parquet file.
Since the connector needs to scan multiple folders we’ve set the setting ‘Include subdirectories’ to True. The ‘Aggregate files’ option is set to False (default).
Example of the full URL to a parquet file for a partitioned table:
<<storage-account>>.blob.core.windows.net / <<container>> / bronze/<<system>>/<<database-name>>/ <<table-name>>/DW_PARTITION=A000/part-00011-59d17d8c-7064-466c-b039-5edf43df4b78.c000.snappy.parquet
Some table are partitioned, some not.
Anyone any ideas? :-)
ps: I’m also trying the CData ADO.NET ADLS connector as mentioned in this TX KB article.
Edit: example screenshots of the structure in a partitioned table ADRMST:
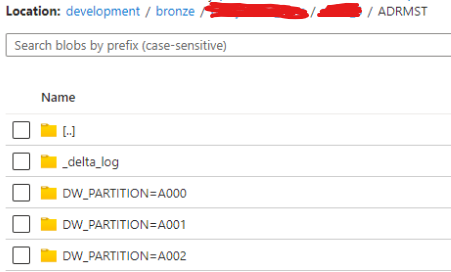
Example of the contents of a partition folder:
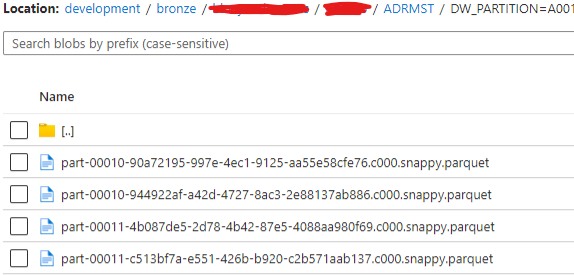
The folder contains multiple files since the data is created with an incremental load.
Example of the contents for an unpartitioned table: