
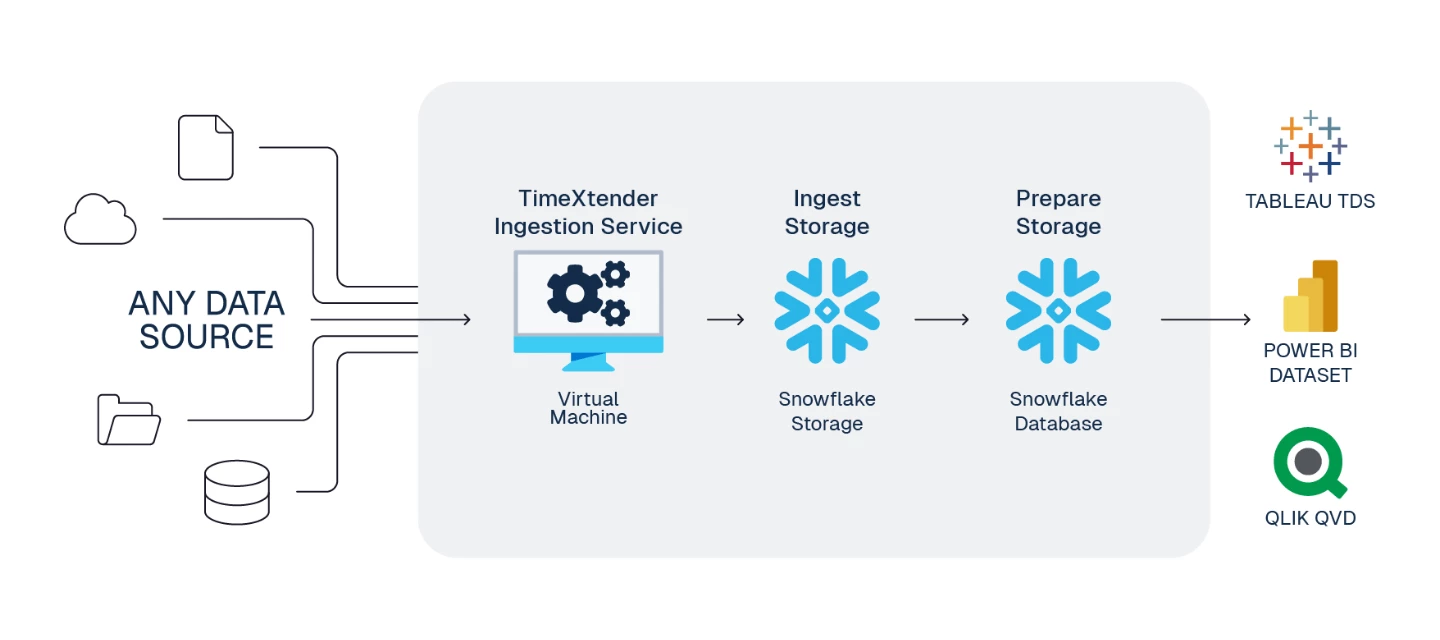

This is a standard reference architecture to implement TimeXtender Data Integration fully in the cloud with Snowflake for both Ingest and Prepare storage.
Note: TimeXtender currently only supports Azure-based Snowflake accounts. When creating your Snowflake account, select Microsoft Azure as the cloud provider.
To prepare your TimeXtender Data Integration cloud environment, here are the steps we recommend.
1. Create Application Server - Azure VM
To serve the TimeXtender Data Integration application in Azure, we recommend using an Azure Virtual Machine (VM), sized according to your solution's requirements.
Guide: Create Application Server - Azure VM
Considerations:
- Recommended Sizing: DS2_v2 (for moderate workloads). See Azure VM Sizes documentation for more detail.
- This VM will host the below services, and must remain running for TimeXtender Data Integration to function
- TimeXtender Ingest Service
- TimeXtender Execution Service
2. Create Storage for Ingest Instance - Snowflake
With native Snowflake ingest storage, you can run a fully Snowflake-based architecture — data flows directly into Snowflake without needing to land in Azure Data Lake first. This simplifies your architecture and reduces the number of Azure resources to manage.
Guide: Use Snowflake Ingest Storage
Considerations:
- Your Snowflake account must be hosted on Microsoft Azure
- TimeXtender Data Integration writes data in Parquet format to a Snowflake internal stage before loading into tables
- The database can be created automatically by the TimeXtender Ingest Service
- Key-pair authentication is recommended for secure, MFA-compatible access
- The same Snowflake account can be used for both Ingest and Prepare storage
Alternative: You can also use Azure Data Lake Storage Gen2 for ingest storage if preferred. Note that if using ADLS with Snowflake Prepare storage, you must configure a SAS token for Snowflake to access the data lake.
3. Create Storage for Prepare Instance - Snowflake Database
- Snowflake's automatic usage-based scaling of compute and storage resources provides ideal cost/resource optimization.
- Suitable for medium to large data solutions. A great choice for mid-size data solutions (from 500GB and up), or in cases where estimated size of data solution is uncertain and/or might rapidly grow.
Guide: Use Snowflake for Prepare Instance Storage
4. Configure Power BI Premium Endpoint (Optional)
If you have Power BI Premium, deploy and execute semantic models within Deliver instances directly to the Power BI Premium endpoint.

